仅用于本人学习笔记的记录。
图片
题型记录
-
多余数据
提取多余数据,如文件末尾数据,exif中的信息等。kali 使用 binwalk 和 foremost 解析、分离文件。 -
篡改标识码,篡改扩展名
操作系统一般通过识别文件头部的标识码,来确定该文件是什么类型,文件中的其他结构同理。Windows 在图形界面下优先用扩展名来识别文件类型。修改成正确的标识码、后缀名。 -
LSB 隐写
Stegsolve 或者 zsteg 提取数据。 -
通道隐写
Stegsolve 查看通道。 -
篡改图片宽高
修改图片宽高。PNG 图片 CRC 反推图片宽高。 -
PNG 多个 IDAT 数据块
删除多余数据块,只保留需要的 IDAT 数据块。可使用 tweakpng。
例题 https://ctf.show/challenges#misc11-1143
工具 https://entropymine.com/jason/tweakpng/ -
PNG 篡改CRC
使用 pngcheck 计算。 -
GIF帧隐写
使用工具逐帧分析,可能涉及查看某一帧,或者分离帧后拼接帧,每一帧的规律等。 -
盲水印
使用工具分析。 -
F5等常见工具隐写
图片文件结构
图片文件的十六进制可以用010编辑器查看。
PNG
PNG(Portable Network Graphics)是一种无损压缩的位图图像格式,十六进制格式如下。
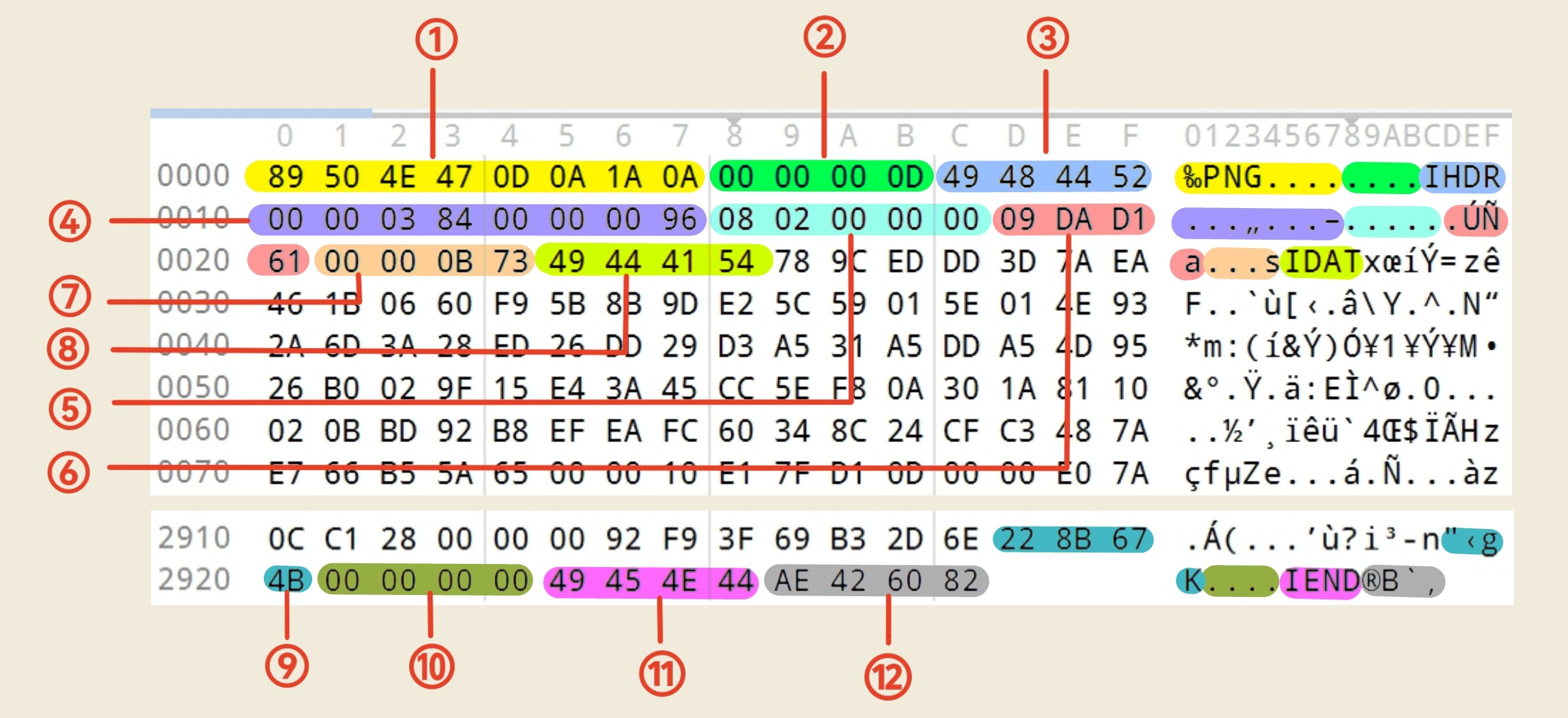
每块代表的内容如下:
| 序号 | 长度(字节) | 含义说明 |
|---|---|---|
| ① | 8 | PNG 文件签名,固定不变,用于标识这是一个 PNG 文件。 |
| ② | 4 | IHDR 数据块的长度,固定为 13,表示接下来的 IHDR 数据区有 13 字节。 |
| ③ | 4 | Chunk 类型码,ASCII 为 "IHDR",表示这是图像头部块。 |
| ④ | 8 | 图像宽度(像素),图像高度(像素)。每项长度4字节。 |
| ⑤ | 5 | 位深度,颜色类型,压缩方法,滤波方法,隔行扫描。每项长度1字节。 |
| ⑥ | 4 | IHDR 的 CRC 校验码,覆盖 IHDR 类型码 + 13 字节数据(③、④、⑤),用于数据完整性校验。 |
| ⑦ | 4 | IDAT 数据块的长度(不固定)。 |
| ⑧ | 4 | Chunk 类型码,ASCII 为 "IDAT",表示这是图像数据块。 |
| — | N | zlib 压缩图像数据,长度由⑦指定。 |
| ⑨ | 4 | IDAT 的 CRC 校验码。 |
| ⑩ | 4 | IEND 数据块的长度,固定为 0。 |
| ⑪ | 4 | Chunk 类型码,ASCII 为 "IEND",表示这是文件结束块。 |
| ⑫ | 4 | IEND 的 CRC 校验码,固定值。 |
PNG 文件由多个数据块(Chunk)组成,每个数据块的结构如下:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
| Length | 4 | 数据区(Data)长度(大端序) |
| Type | 4 | 数据块类型(ASCII 字符串,如 IHDR) |
| Data | N | 数据区,长度为 Length 字段指定 |
| CRC | 4 | 对 Type + Data 的 CRC32 校验值 |
PNG 规范只定义了 4 个关键数据块,它们必须被所有读写器识别,且顺序固定:
| 名称 | 类型码(ASCII) | 说明 | 出现顺序 |
|---|---|---|---|
| IHDR | 49 48 44 52 |
图像头,含宽高、色深、颜色类型等 | 第 1 个 |
| PLTE | 50 4C 54 45 |
调色板(索引色图像必须) | 若有,须在 IDAT 前 |
| IDAT | 49 44 41 54 |
压缩后的图像数据,可多个连续块 | 在 IHDR/PLTE 之后 |
| IEND | 49 45 4E 44 |
文件结束标记,长度 0 | 最后 1 个 |
PNG 规范允许把压缩后的图像数据分片存储,因此:
- 一个 PNG 文件中可以出现任意多个连续的 IDAT 块。
- 解码时必须按出现顺序把所有 IDAT 的数据拼接起来,再当做一个完整的 zlib 流解压。如果解压出来多个完整的 zlib 数据,那么说明有未在图像中显示的 zlib 数据。 默认只显示第一个 zlib 数据。(zlib文件头
78 9c) - 分片仅为了流式生成或减少内存占用,对图像内容无任何影响。
除了四个关键数据块外,其余均为辅助数据块。辅助数据块非必须(如 iTXt、pHYs、tEXt、tIME 等),没有固定的绝对偏移量,在 PNG 文件中的出现位置“允许浮动”,但是必须在 IHDR 之后并且必须在 IEND 之前。因此,它们通常位于 IHDR 块与第一个 IDAT 块之间或最后一个 IDAT 块与 IEND 块之间。
下表非必要了解
| 块名 | 用途 |
|---|---|
| iTXt | UTF-8 关键字-值文本,可压缩;常用来写 XMP、版权、注释。 |
| pHYs | 像素宽高比(或 DPI),让矢量排版软件按真实尺寸放置。 |
| sRGB | 直接声明“这张图遵循 sRGB”,色彩管理流程可跳过 ICC。 |
| tEXt | 最老牌的 Latin-1 文本注释,Key-Value 形式,写版权、作者。 |
| tIME | 最后修改时间戳,版本控制或相册排序用。 |
对于多个IDAT块有以下补充内容:
PNG协议规定,所有IDAT块中的压缩数据在逻辑上是一个连续的数据流。也就是说,解码器会把所有IDAT块中的数据按顺序拼接起来,作为一个完整的压缩数据流进行解压缩。
- 关键理解:PNG协议中,所有IDAT块中的压缩数据在逻辑上是一个连续的数据流,必须先作为一个完整的数据流进行压缩,然后再分割成多个部分放入IDAT块中。
- 只能显示第一个数据块:将图像数据分成多个独立部分分别压缩,导致解码器无法正确解压缩拼接后的数据流。默认只能显示第一部分的图像数据。
- 正确方法:先整体压缩,再分割IDAT块。
JPEG(JPG)
JPEG文件的数据是按照段(Segment)组织的,每个段从一个标记(Marker)开始,标记的格式是0xFF后跟一个非零的字节。
每段都以FF xx开头,紧接2字节长度的字段(大端,含长度本身但不含FF xx),随后是这段特有的数据。
JPEG 常见标记段如下表:
| 标记名 | 十六进制 | 全称 | 作用说明 |
|---|---|---|---|
| SOI | FF D8 | Start of Image | 文件必须以此开头 |
| APP0 | FF E0 | Application Segment 0 | 存放 JFIF 主信息 |
| DQT | FF DB | Define Quantization Table | 定义量化表 |
| SOF0 | FF C0 | Start of Frame (Baseline DCT) | 帧开始,含图像高/宽/分量等基本信息 |
| DHT | FF C4 | Define Huffman Table | 定义霍夫曼码表 |
| SOS | FF DA | Start of Scan | 扫描开始,其后为压缩图像数据流 |
| COM | FF FE | Comment | 存放用户注释(纯文本) |
| EOI | FF D9 | End of Image | 文件必须以此结尾 |
注:JFIF 是“JPEG File Interchange Format”的缩写,是对 JPEG 压缩数据的一套最小包装规则,有交换必需信息(如图像尺寸、分辨率等),让任何软件都能统一识别。
BPG
BPG(Better Portable Graphics,更优便携图形)是一种新的图像格式,其目标是在对画质或文件体积有更高要求时取代 JPEG。
使用 BPGviwer 即可浏览任何 BPG 文件。BPG 是一种既支持有损也支持无损的图片压缩格式,基于高效视频编码(HEVC)。也可以使用 Honeyview 进行浏览。
十六进制示例如图

https://bpgviewer.sourceforge.net/
https://www.bandisoft.com/honeyview/
honeyview 支持的格式
图像格式: BMP, JPG, GIF, PNG, PSD, DDS, JXR, WebP, J2K, JP2, TGA, TIFF, PCX, PGM, PNM, PPM, BPG
Raw 图像格式: DNG, CR2, CRW, NEF, NRW, ORF, RW2, PEF, SR2, RAF
动画图像格式: Animated GIF, Animated WebP, Animated BPG, Animated PNG
无需解压即可直接查看压缩包中的图像: ZIP, RAR, 7Z, LZH, TAR, CBR, CBZ
BMP
BMP(Bitmap)文件是Windows操作系统中的标准图像文件格式,其结构相对简单且固定。文件头是42 4D也就是BM。所有多字节字段使用小端序(低位字节在前),每行像素末尾可能填充0以保证4字节对齐。
BMP文件由4个主要部分构成,按顺序排列:
- 位图文件头
- 位图信息头
- 调色板(可选)
- 像素数据
(1) 位图文件头
- 长度:14字节
- 作用:标识文件类型及存储像素数据的偏移位置。
- 字段:
序号 字段名 长度(字节) 说明 ① bfType 2 文件类型,固定为 4D 42(ASCII码"BM")。② bfSize 4 文件总大小(字节)。注意小端序,如下图中 0x000A4CF0为 675056 字节。③ bfReserved 4 保留字段,必须为0。 ④ bfOffBits 4 像素数据起始位置(即文件头+信息头+调色板的总长度)。
示例如下
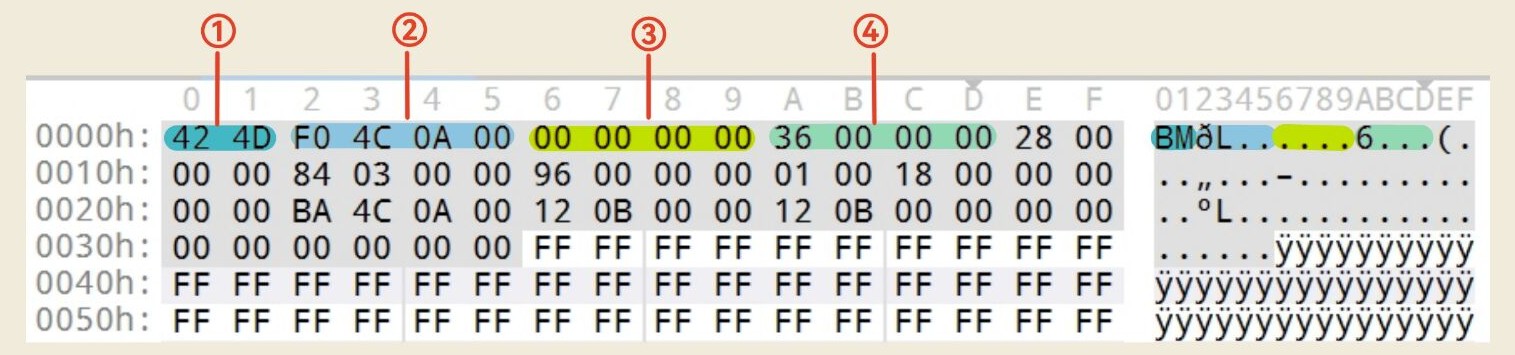
(2) 位图信息头
- 长度:通常为40字节(Windows BMP标准),也可能为其他版本(如12字节、108字节等)。
- 作用:描述图像的详细信息(尺寸、颜色深度、压缩方式等)。
- 核心字段(40字节版本):
序号 字段名 长度(字节) 说明 ① biSize 4 信息头长度(通常为40)。 ② biWidth 4 图像宽度(像素)。 ③ biHeight 4 图像高度(像素)。注意:正值表示底到顶存储,负值表示顶到底存储。 ④ biPlanes 2 颜色平面数,固定为1。 ⑤ biBitCount 2 每像素位数(1、4、8、16、24、32)。 ⑥ biCompression 4 压缩方式(0=不压缩,1=RLE8,2=RLE4,3=位域,4=JPEG,5=PNG)。 ⑦ biSizeImage 4 像素数据大小(字节,可为0表示未压缩)。 ⑧ biXPelsPerMeter 4 水平分辨率(像素/米)。 ⑨ biYPelsPerMeter 4 垂直分辨率(像素/米)。 ⑩ biClrUsed 4 实际使用的颜色数(0表示使用所有可能颜色)。 ⑪ biClrImportant 4 重要颜色数(0表示所有颜色都重要)。
示例如下
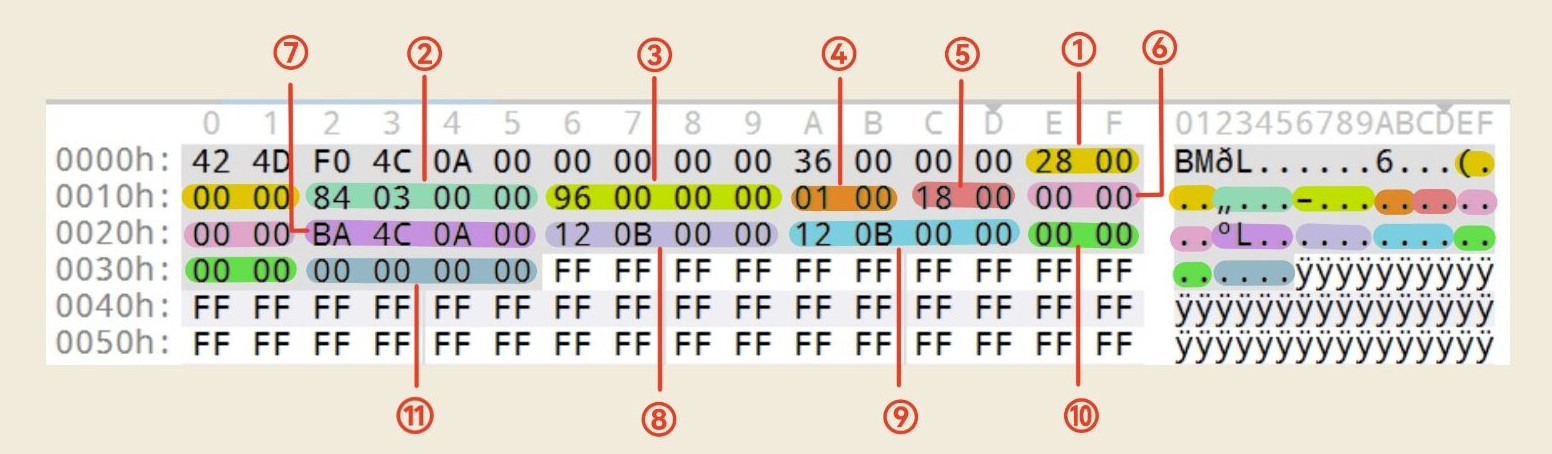
(3) 调色板(Color Palette)
- 存在条件:当
biBitCount ≤ 8(即1、4、8位色)时必需。 - 作用:定义图像中使用的颜色(类似索引表)。
- 结构:每个颜色表项为4字节,格式为:
字段名 长度(字节) 说明 rgbBlue 1 蓝色分量(0-255)。 rgbGreen 1 绿色分量(0-255)。 rgbRed 1 红色分量(0-255)。 rgbReserved 1 保留字段(必须为0)。
(4) 像素数据
- 存储规则:
- 行对齐:每行像素数据的长度必须是4字节的倍数(不足时填充0)。
- 存储方向:通常从左下角到右上角(即底到顶),除非
biHeight为负值(顶到底)。 - 颜色模式:
- 24位色:每像素3字节(BGR顺序,非RGB)。
- 32位色:每像素4字节(BGRA顺序,Alpha通道可能未使用)。
- 8位色:每像素1字节(调色板索引)。
- 1位色:每像素1位(黑白,1表示白色,0表示黑色)。
补充:
对于图示BMP文件来说,每像素位数为24,也就是3字节。对于图片的宽高和总大小,有如下公式:
其中+31目的是向上取整到32的倍数(即4字节的倍数,32位)。×4转换为字节(1字节=8位)。
示例代码,功能:已知图像总字节数和宽/高,计算高/宽。
点击查看代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
公式:ImageSize = floor((W*bpp+31)/32)*4 * H
"""
from typing import Optionaldef row_bytes(width: int, bpp: int) -> int:return ((width * bpp + 31) // 32) * 4def fix_one_side(image_size: int, bpp: int, *, width: Optional[int] = None,height: Optional[int] = None) -> Optional[int]:if width is not None and width > 0:rb = row_bytes(width, bpp)return image_size // rb if image_size % rb == 0 else Noneif height is not None and height > 0:target_rb = image_size // heightif image_size % height != 0:return Noneblocks = target_rb // 4if target_rb % 4 != 0:return Nonew_min = (blocks * 32 - 31 + bpp - 1) // bppw_max = ((blocks + 1) * 32 - 32 + bpp - 1) // bppfor w in range(w_min, w_max + 1):if row_bytes(w, bpp) == target_rb:return wreturn Noneraise ValueError("必须指定 width 或 height")def input_int(prompt: str, default: Optional[int] = None) -> int:while True:val = input(prompt).strip()if val == '' and default is not None:return defaulttry:return int(val)except ValueError:print("请输入有效整数!")def main():print("=== BMP 固定宽高反算 ===")img_size = input_int("ImageSize(字节):")bpp = input_int("biBitCount(回车默认 24):", default=24)if img_size <= 0 or bpp <= 0:print("ImageSize 和 bpp 必须为正整数!")returnfix = input("固定宽还是高?输入 w 或 h:").strip().lower()if fix == 'w':w = input_int("输入固定宽度:")h = fix_one_side(img_size, bpp, width=w)print(f"对应高度 = {h}" if h is not None else "无解!")elif fix == 'h':h = input_int("输入固定高度:")w = fix_one_side(img_size, bpp, height=h)print(f"对应宽度 = {w}" if w is not None else "无解!")else:print("请输入 w 或 h!")if __name__ == "__main__":main()
GIF
文件头是47 49 46 38也就是GIF8,文件尾是单字节3B。
TIFF
文件头是49 49 2A 00也就是II*\x00。
RIFF
文件头是52 49 46 46也就是RIFF。RIFF是一种容器格式,同一份结构可装音频(WAV)、视频(AVI)、网页(WEBP)等不同载荷。
文件头结构如下:
| 偏移 | 长度 | 内容 | 典型值 |
|---|---|---|---|
| 0x00 | 4 | FourCC ID | RIFF |
| 0x04 | 4 | 文件总长度 − 8(即从此字段之后到文件尾的字节数) | 小端字节序 |
| 0x08 | 4 | 格式类型 | WAVE / AVI / WEBP / … |
例如:
52 49 46 46 24 08 00 00 57 41 56 45 → RIFF-WAVE (wav)
52 49 46 46 C2 02 00 00 41 56 49 20 → RIFF-AVI (avi)
52 49 46 46 26 06 00 00 57 45 42 50 → RIFF-WEBP (webp)
WEBP
文件头52 49 46 46 26 06 00 00 57 45 42 50即RIFF-WEBP,可使用 honeyview 查看。
图片LSB隐写(MSB隐写同理)
使用 Stegsolve 对数据进行分析。
首先将图片放入该工具,遍历查看通道,如在边缘有规则连续突兀的黑色点,则可能有隐写内容。对每个有隐写可能的通道进行以下判断:
- 查看通道标识(Alpha/Red/Green/Blue以及后面的数字),勾选Bit Planes。
- 竖列/横条(Row/Column),选择Extract By。

Bit Plane Order选项遍历选择,寻找有意义的数据。

简易隐写代码
点击查看代码
#!/usr/bin/env python3
from PIL import ImageCOVER_PIC = 'R-C.png' # 原图
PAYLOAD_BIN = 'flag.txt' # 待隐藏文件
STEGO_PIC = 'R-C_encrypt.png' # 生成图# 1. 每个通道要写的位平面列表
PLAN = [('G', [0,1]),('R', [2]),('B', [1])]# 2. 扫描方式
SCAN = 'col' # 'row' 行优先 | 'col' 列优先
DIR = 'forward' # 'forward'正序 | 'backward'倒序def set_bit(value, bit, plane):return (value & ~(1 << plane)) | (bit << plane)def hide():img = Image.open(COVER_PIC).convert('RGB')w, h = img.sizewith open(PAYLOAD_BIN, 'rb') as f:payload = f.read()data_bits = ''.join(f'{b:08b}' for b in payload) + '0' * 8# 生成坐标序列if SCAN == 'row':coords = [(x, y) for y in range(h) for x in range(w)]else: # colcoords = [(x, y) for x in range(w) for y in range(h)]if DIR == 'backward':coords = coords[::-1]bit_idx = 0for x, y in coords:if bit_idx >= len(data_bits):breakr, g, b = img.getpixel((x, y))for ch, planes in PLAN:for plane in planes:if bit_idx >= len(data_bits):breakbit = int(data_bits[bit_idx])if ch == 'R':r = set_bit(r, bit, plane)elif ch == 'G':g = set_bit(g, bit, plane)else: # 'B'b = set_bit(b, bit, plane)bit_idx += 1img.putpixel((x, y), (r, g, b))if bit_idx < len(data_bits):raise ValueError('图太小,塞不下')img.save(STEGO_PIC, 'PNG')print('[+] 隐藏完成 →', STEGO_PIC)print('[+] 方案: PLAN=%s | SCAN=%s | DIR=%s' % (PLAN, SCAN, DIR))if __name__ == '__main__':hide()
压缩包
题型记录
- 伪加密
修改伪加密的十六进制。 - 密码爆破
暴力破解,掩码攻击,字典攻击,使用 ARCHPR 等工具。 - CRC32碰撞
加密压缩包 + 小文件 + 给出 CRC32,穷举生成符合校验值的小文件。 - 已知明文攻击
利用加密压缩包中已知的一段明文直接算出 ZIP 的加密密钥,使用 ARCHPR 等工具。 - 附加数据/信息
使用 binwalk 和 foremost 等工具提取文件。查找有意义的附加信息,比如注释,冗余信息等。 - 数据损坏(头文件等)
根据文件结构修复数据。
文件结构
ZIP
ZIP是一种常见的文件压缩格式,由多个局部记录和一个中心目录组成,最后用一个结束标记收尾。ZIP 格式里所有文件结构字段一律采用小端序。
下图给出一个简单的文件示例。

1. 局部文件头(Local File Header,LFH)
作用:告诉解压器“一个文件开始了”,给出压缩参数、文件名与扩展区,并指明紧随其后的压缩数据该如何解读。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ① | 4 | 签名 0x04034B50 | 定位块起点;必小端 |
| ② | 2 | 解压最低版本 | 20=Deflate;45=ZIP64;需≤制作版本 |
| ③ | 2 | 通用标志位(Local标志) | bit0是否加密/bit3是否有数据描述符/bit11 UTF-8;如果bit0=1,代表已加密;如果bit3=1,代表⑦⑧⑨置空,后面有数据描述符 Data Descriptor |
| ④ | 2 | 压缩方法 | 0存储/8 Deflate/12 BZip2/93 Zstd;与中心目录必须一致 |
| ⑤ | 2 | 最后修改时间 | MS-DOS 编码;可填0表示“无时间” |
| ⑥ | 2 | 最后修改日期 | 同上 |
| ⑦ | 4 | CRC-32 | 若bit3=1先填0,真值后补;否则必须有效 |
| ⑧ | 4 | 压缩后大小 | ZIP64时填0xFFFFFFFF;真值在ZIP64 Extra |
| ⑨ | 4 | 未压缩大小 | 同上规则 |
| ⑩ | 2 | 文件名长度 N | 下文文件名占 N 字节 |
| ⑪ | 2 | 扩展区长度 M | 下文 Extra 占 M 字节 |
| ⑫ | N | 文件名 | UTF-8/CP437;与中心目录同名必须逐字节相同 |
| ⑬ | M | 扩展区 | Tag+Size 子块链;可放 ZIP64、时间戳等 |
| ⑭ | * | 压缩数据 | 紧跟 Extra 后,长度=⑧,是真正的压缩数据 |
2. 可选数据描述符(Data Descriptor)
作用:当局部文件头里无法预先给出 CRC/大小时,在压缩流之后立即补录实际值,供校验与分配缓冲。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ⑮ | 4 | 可选签名 0x08074B50 | 仅当标志位 bit3=1 且压缩器愿意写时出现;可省略 |
| ⑯ | 4 | CRC-32 | 必须与中心目录、实际流一致;用于校验 |
| ⑰ | 4 | 压缩后大小 | 与局部头/中心目录字段最终值相等 |
| ⑱ | 4 | 未压缩大小 | 同上;三值一起完成“后置描述” |
3. 中心目录记录(Central Directory File Header,CDFH)
作用:为每个文件建立“索引卡片”,保存全局唯一且完整的元数据,并给出局部头偏移,实现随机访问与完整性校验。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ⑲ | 4 | 签名 0x02014B50 | 定位中心目录条目 |
| ⑳ | 2 | 制作工具版本 | 高字节=系统标识;低字节=PKZip版本 |
| ㉑ | 2 | 解压最低版本 | 必须≥局部头同字段;不一致即格式错 |
| ㉒ | 2 | 通用标志位(Central标志) | 需与局部头完全相同;bit0 状态决定是否加密;bit3 状态决定是否存在数据描述符 Data Descriptor |
| ㉓ | 2 | 压缩方法 | 必须与局部头相同;否则解压器可拒读 |
| ㉔ | 2 | 最后修改时间 | 与局部头保持一致;用于覆盖时对比新旧 |
| ㉕ | 2 | 最后修改日期 | 同上 |
| ㉖ | 4 | CRC-32 | 若与局部头/流计算结果不符即视为损坏 |
| ㉗ | 4 | 压缩后大小 | ZIP64时填0xFFFFFFFF;真值放ZIP64 Extra |
| ㉘ | 4 | 未压缩大小 | 同上规则 |
| ㉙ | 2 | 文件名长度 N | 必须与局部头 N 相等 |
| ㉚ | 2 | 扩展区长度 M | 可含ZIP64、时间戳、Unix权限等 |
| ㉛ | 2 | 注释长度 K | 可为0 |
| ㉜ | 2 | 起始磁盘号 | 多卷时分卷序号;单卷填0 |
| ㉝ | 2 | 内部文件属性 | 最低位=1表示文本文件;其余保留 |
| ㉞ | 4 | 外部文件属性 | Unix高16位存st_mode;Windows通常0 |
| ㉟ | 4 | 局部头偏移量 | 关键定位字段;ZIP64时填0xFFFFFFFF,真值放ZIP64 Extra |
| ㊱ | N | 文件名 | 与局部头同名字段必须逐字节相同 |
| ㊲ | M | 扩展区 | 同局部头,但可额外加入ZIP64、NTFS、Unix等 |
| ㊳ | K | 文件注释 | 可选;UTF-8/CP437;总长度受EOCD限制 |
4. 中央目录结束标记(End of Central Directory Record,EOCD)
作用:标志 ZIP 文件正式结束,给出中心目录的大小与偏移,让解压器一次性“倒跳”到目录区,并校验整体完整性。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ㊴ | 4 | 签名 0x06054B50 | 定位整个ZIP尾部 |
| ㊵ | 2 | 当前磁盘号 | 多卷时当前卷序号;单卷0 |
| ㊶ | 2 | 中央目录所在磁盘号 | 与上相同即为单卷;否则需跨卷读取 |
| ㊷ | 2 | 本磁盘条目数 | 与总条目数相等即为无分卷 |
| ㊸ | 2 | 总条目数 | 应与中心目录实际条数一致;不符即损坏 |
| ㊹ | 4 | 中央目录大小 | 字节数;用于从EOCD向前跳→定位第一条CDFH |
| ㊺ | 4 | 中央目录偏移 | 相对于文件开头;ZIP64时填0xFFFFFFFF,需看ZIP64 EOCD |
| ㊻ | 2 | 注释长度 L | 可为0 |
| ㊼ | L | 存档注释 | 可选;常被用来隐藏文本或版权信息 |
win11自带zip压缩和WINRAR的标准zip压缩区别可能在于⑳导致②③④㉒㉓不同等,最后导致压缩后的内容不同。
本人使用win11自带zip压缩(未加密)时得到的文件的通用标志位③为0x08,压缩方法④为0x08(Deflate);而使用WINRAR的标准zip压缩(未加密)时得到的文件的通用标志位③为0x00,当文件内容很少时,压缩方法④为0x00(直接存储),压缩数据为明文,当文件内容较多时,压缩方法④为0x08(Deflate)。
关于zip伪加密
ZIP 伪加密并不是真的把文件用密码加密,而是在未加密压缩包的基础上篡改了标志位,让解压软件误认为这个包被加密了,从而弹出输密码的对话框;但实际上数据区没有任何加密处理,只要把被篡改的标志位改回来就能直接解压。
伪加密情况如下表:
| 类型 | Local标志③ | Central标志㉒ | 现象 |
|---|---|---|---|
| 无加密 | 00 00 |
00 00 |
直接打开 |
| 真加密 | 09 00 |
09 00 |
要密码且必须正确 |
| 伪加密1 | 00 00 |
09 00 |
需要密码,使用win11自带解压工具和WINRAR都无法解压 |
| 伪加密2 | 09 00 |
00 00 |
使用win11自带解压工具和WINRAR都可以正常解压 |
| 伪加密3 | 09 00 |
09 00 |
实际数据未加密,但是两个bit1都被篡改为1,不清楚怎么肉眼判断加密真伪,ZipCenOp.jar可以检测真伪,可以尝试修改bit1=0,如果成功解压就是伪加密 |
标志只要为奇数(bit1=1)即可,常见把
00 00→09 00或01 00,改完保存即可伪造加密。上表中的
09 00也可为01 00,00 00也可为08 00(bit3不同,bit1相同),得到的实验现象相同,详情见③㉒的描述;但是注意特殊情况,如果在原文件的 Local标志 的bit3=1的情况下,修改其为bit3=0,解压出的文件会损坏,无法正常解压;Central标志 的bit3不会影响。猜测文件损坏原因是Local标志的bit3原本是1,CRC和文件大小在真实压缩数据末尾给出,而⑦⑧⑨处全部置空,但是修改成了0,CRC和文件大小都为0,所以解压错误。Central标志bit3的改变,在测试中没有表现出对文件的损坏,可能是样本太小或者其他原因。
RAR
RAR 文件在十六进制层面由若干“块(Block)”串成,每块都以 2 字节 CRC 打头,随后 1 字节类型、2 字节标志、2 字节本块长度,再跟变长载荷。所有多字节字段均按 little-endian 存放。下面按 RAR 4.x(目前仍最常用)与 RAR 5.0 两条线分别给出完整格式说明,并给出可抓取的“指纹”与常见调试技巧。
一个RAR文件由一系列标记块(Marker Block)、归档头(Archive Header)、文件头(File Header)、服务信息块(Service Blocks) 以及压缩数据组成。所有块都遵循一个通用的块头结构。
RAR 4.x 格式
旧格式,签名: 0x52 0x61 0x72 0x21 0x1A 0x07 0x00
- 标记头(MARK_HEAD)
作用:位于文件开头,标识这是一个RAR4归档文件。
| 序号 | 长度 (字节) | 名称 | 含义与注意要点 |
|---|---|---|---|
| ① | 4 | 签名(Magic Number) | 0x52 0x61 0x72 0x21 (Rar!) |
| ② | 2 | 类型(Block Type) | 0x72 = 归档头(MARK_HEAD),0x73 = 文件头(FILE_HEAD) |
| ③ | 2 | 标志(Flags) | 小端。0x8000 表示第1卷,0x4000 表示注释存在等。 |
| ④ | 2 | 大小(Size) | 小端。整个块的大小,包括头和数据。 |
| ⑤ | 4 | 保留字段 | 必须为 0x00。 |
- 文件头(FILE_HEAD)
作用:描述一个被压缩文件的元数据。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ① | 4 | 打包大小(Pack Size) | 小端。压缩后数据的大小。 |
| ② | 4 | 解包大小(Unpack Size) | 小端。解压后原始数据的大小。 |
| ③ | 1 | 主机操作系统 | 0x00: MS-DOS 0x01: OS/2 0x02: Windows 0x03: Unix |
| ④ | 4 | 文件CRC32 | 未压缩文件的CRC校验值。 |
| ⑤ | 4 | 文件修改时间 | MS-DOS格式的日期和时间。 |
| ⑥ | 1 | 压缩版本 | 解压所需RAR版本(主版本*10 + 次版本)。 |
| ⑦ | 1 | 压缩方法 | 0x30: 存储 0x31: 最快压缩 0x32: 快速压缩 0x33: 标准压缩 0x34: 良好压缩 0x35: 最好压缩 |
| ⑧ | 2 | 文件名长度(Name Size) | 小端。下文文件名占 N 字节。 |
| ⑨ | 4 | 文件属性(File Attributes) | 操作系统相关的文件属性。 |
| ⑩ | N | 文件名 | 通常为ANSI/OEM(如CP437) 编码,以零字节终止。长度由字段⑧定义。 |
| ⑪ | V | 可选附加数据 | 如解压后为0x30 0x40 0x50 0x74,则表示有** authenticity verification **。 |
| - | * | 压缩数据 | 紧跟在文件头之后,长度 = 字段①的打包大小。 |
- 结束头(ENDARC_HEAD)
作用:标记整个RAR4归档的结束。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ① | 2 | 头部CRC | 头部数据的CRC校验。 |
| ② | 2 | 类型(Block Type) | 0x7B = 结束头(ENDARC_HEAD) |
| ③ | 2 | 标志(Flags) | 小端。0x8000 表示此归档有后续卷。 |
| ④ | 2 | 保留字段 | 必须为 0x00。 |
RAR 5.0 格式
新格式,签名: 0x52 0x61 0x72 0x21 0x1A 0x07 0x01 0x00
- 通用块头结构(Common Block Header)
作用:每一个RAR5块的起始部分,用于标识块的类型、大小和关键属性。这是RAR5的核心变化。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ① | 4 | 头部CRC32 | 小端。整个块头(从字段②开始到块头结束)的CRC32校验和。如果块标志的BIT3被设置,则此值为0。 |
| ② | 2 | 块大小(Block Size) | 小端。整个块的总大小,包括块头和块体。 |
| ③ | 1 | 块类型(Block Type) | 0x01: 归档头 0x02: 文件头 0x03: 服务头 0x04: 归档加密头 0x05: 结束标记 0x06: 服务信息结束标记 |
| ④ | 1 | 块标志(Block Flags) | 位掩码。 BIT0 ( 0x01): 后跟数据区域。 BIT1 ( 0x02): 取决于块类型的额外区域。 BIT2 ( 0x04): 此块使用“区域”结构(数据大小在ADD_SIZE中定义)。 BIT3 ( 0x08): 块头CRC32(字段①)为0。 BIT4 ( 0x10): 后续块是上一块的延续。 |
| ⑤ | 4 | 额外大小(Add Size) | 小端。如果BIT2被设置,此字段表示数据区域的大小。否则通常为0。 |
- 归档头块(Archive Header - Type:
0x01)
作用:标识整个RAR5归档的开始,并包含全局的归档属性。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ①-⑤ | 7 | 通用块头 | CRC32(4) + SIZE(2) + TYPE=0x01(1) + FLAGS(1) + ADD_SIZE(4) |
| ⑥ | 4 | 归档标志(Archive Flags) | 小端。 BIT0 ( 0x0001): 卷属性(分卷)。 BIT1 ( 0x0002): 存在恢复记录。 BIT2 ( 0x0004): 归档被锁定。 |
| ⑦ | 4 | 保留字段 | 必须为0。 |
- 文件头块(File Header - Type:
0x02)
作用:描述一个被压缩文件的元数据。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ①-⑤ | 7 | 通用块头 | CRC32(4) + SIZE(2) + TYPE=0x02(1) + FLAGS(1) + ADD_SIZE(4)。BIT0通常为1。 |
| ⑥ | 8 | 未压缩大小(Unpacked Size) | 小端编码。支持64位大小。若为0xFFFFFFFFFFFFFFFF,则大小在EXTRA区域中定义。 |
| ⑦ | 4 | 文件属性(File Attributes) | 操作系统相关的文件属性。 |
| ⑧ | 4 | 未压缩文件的CRC32 | 小端。用于校验解压后的数据。 |
| ⑨ | 4 | 压缩数据块的偏移(File Offset) | 小端。从本文件块开始到其数据区域的偏移量。 |
| ⑩ | 4 | 压缩方法、字典大小与固实标志 | 小端。一个复合字段,包含压缩方法(低5位)、字典大小(中19位)和固实标志(高1位)。 |
| ⑪ | 2 | 主机操作系统 | 小端。 0: Windows 1: Unix |
| ⑫ | 4 | 文件名长度(Name Size) | 小端。下文文件名占 N 字节。 |
| ⑬ | N | 文件名 | UTF-8编码,不以零字节终止。长度由字段⑫定义。 |
| ⑭ | V | 额外区域(Extra Area) | 可选。如果BIT2被设置,则存在。结构为TAG(2) + SIZE(2) + DATA(SIZE)。用于存储时间戳、NTFS ACLs等。 |
| - | * | 压缩数据 | 位置 = 文件头起始位置 + 字段⑨。长度 = 字段⑤ (ADD_SIZE)。 |
- 结束标记块(End of Archive - Type:
0x05)
作用:标记整个RAR5归档的结束。
| 序号 | 长度 | 名称 | 含义与注意要点 |
|---|---|---|---|
| ①-⑤ | 7 | 通用块头 | CRC32(4) + SIZE(2) + TYPE=0x05(1) + FLAGS(1) + ADD_SIZE(4)。此块无数据,BIT0为0。 |
| ⑥ | 4 | 结束标志 | 必须为0x40 0x7F 0x73 0x52(小端解读为0x52737F40)。 |
核心差异总结 (RAR4 vs RAR5)
| 特性 | RAR 4.x | RAR 5.0 |
|---|---|---|
| 全局签名 | 52 61 72 21 1A 07 00 |
52 61 72 21 1A 07 01 00 |
| 块结构 | 非统一。每种头类型有独立结构。 | 统一。所有块都以通用块头开始,极大增强了扩展性。 |
| 大小字段 | 32位。文件大小、打包大小等均为4字节,限制单个文件最大4GB。 | 64位。核心字段(如未压缩大小)升级为8字节,支持超大文件。 |
| 文件名编码 | 主要使用 ANSI/OEM (如CP437),兼容性差。 | 强制使用 UTF-8,更好地支持国际字符。 |
| 压缩方法 | 方法字段简单。 | 方法、字典大小、固实标志合并为一个复合字段,设计更紧凑。 |
| 数据定位 | 压缩数据紧接在文件头之后。 | 文件头中包含明确的数据偏移(File Offset) 字段,指向数据区域。 |
| 加密算法 | 使用私有算法。 | 使用 AES-256 加密,更安全。 |
| 恢复记录/校验和 | 使用私有格式。 | 使用 Blake2sp 哈希算法进行校验,更现代、更安全。 |
调试/取证速查表
- 快速判断版本:看偏移 0x06 是 0x00→4.x,0x01→5.0。
- 找文件头:4.x 直接搜
74并回退 2 字节 CRC;5.0 搜类型字节02并回退 4 字节 CRC32。 - 改加密位:4.x 把 HEAD_FLAGS 最低位清 0;5.0 需改 Extra 记录里的加密标志字节。
- 恢复记录:4.x 类型 0x78 含 (224,208) Reed-Solomon 码;5.0 把恢复数据放在服务头块内,需官方 unrar 库解析。
- 结束块:4.x 固定 7 字节
C4 3D 7B 00 40 07 00;5.0 结束块类型字节为 5,后接 vint 长度 0x0C。
CRC32碰撞
一般是ZIP压缩包,核心原理如下:
- ZIP 内每个文件头存一份 CRC32(明文校验值,4 B)。
- CRC32 输出空间仅 2³²;当文件极短(≤6 B)时,明文空间 ≤ 校验空间,可暴力逆推原文。
- CRC32 满足线性性:
CRC(A⊕B) = CRC(A)⊕CRC(B),因此也能构造“不同内容、相同 CRC”的碰撞块,但 CTF 几乎只用“短文件逆推”。
有Github的项目可以用来解题,使用简单示例python crc32.py reverse crc32密文。
https://github.com/theonlypwner/crc32
彩虹表项目
https://github.com/Emersonksc/crc32-6b-table
判断是否可以爆破
- 看加密包内文件大小
4-6 B → 可爆破 - 看字符集
已知 Base64/大写/数字可大幅缩空间。
常出现的题型如下表所示:
| # | 出题点 | 典型特征 | 关键点 | 解法 |
|---|---|---|---|---|
| 1 | 极短单文件爆破 | 加密 zip 内仅 4 B/5 B/6 B 单个文件 | CRC32 空间≥明文空间 | zipinfo.CRC 或 7z l -slt 直接读 CRC 十六进制,Python itertools.product 穷举 4-6 位,秒级出结果。 |
| 2 | 多包分段拼接 | 几十个 zip,每包 4 B 文件,CRC 不同 | 批量逆推→按序号拼 flag | 循环批量运行代码,得若干 4-6 位字符串,按文件序号拼成 flag。 |
关于多包 4/5/6 B 爆破解密,flag 被切成 N 段 4 B 小块,分别塞进 N 个加密 zip;批量暴力破解,最后按包序号拼接。
给出的代码有以下功能:支持一个文件夹内多个 zip,支持每个 zip 里任意数量被压缩文件,指定字节长度 4/5/6 与 “CRC 列表”/“zip 文件夹” 两种模式。
点击查看代码
#!/usr/bin/env python3
import os, zipfile, zlib, itertools, string# ========== 用户只需改这里 ==========
BYTES = 4 # 4 或 5 或 6
MODE = 'zip' # 'crc' 列表模式 或 'zip' 文件夹模式
# -----------------------------------
# MODE='crc' 时用下面的列表(十六进制)
CRC_LIST = [0x12345678, 0x9abcdef0]
# MODE='zip' 时用下面的文件夹
ZIP_DIR = 'zipzip'
# ===================================CHARSET = string.ascii_letters + string.digits + '{}_'def crack(target_crc, length):"""返回第一个碰撞成功的字符串"""for cand in itertools.product(CHARSET, repeat=length):if zlib.crc32(''.join(cand).encode()) & 0xffffffff == target_crc:return ''.join(cand)return Nonedef main():results = []if MODE == 'crc':for crc in CRC_LIST:print(f"[+] 正在爆破 CRC 0x{crc:08x}")res = crack(crc, BYTES)if res:print(f" -> 成功: {res}")results.append(res)else:print(f" -> 失败")else:# 文件夹模式:多 zip,每个 zip 里多文件zips = sorted([f for f in os.listdir(ZIP_DIR) if f.lower().endswith('.zip')])for zf in zips:zpath = os.path.join(ZIP_DIR, zf)with zipfile.ZipFile(zpath) as z:# 按文件名顺序爆破for info in sorted(z.infolist(), key=lambda x: x.filename):crc = info.CRCprint(f"[+] 正在破解 {zf} :: {info.filename} CRC=0x{crc:08x}")res = crack(crc, BYTES)if res:print(f" -> 成功: {res}")results.append(res)else:print(f" -> 失败")print("\n=== FLAG ===")print(''.join(results))if __name__ == '__main__':main()
已知明文攻击原理
该题型使用 ARCHPR 工具破解。
zip压缩文件所设定的密码,首先被转换成3个32bit的key,所以可能的key的组合是2^96,这是个天文数字,如果用暴力穷举的方式是不太可能的,除非密码比较短或者有个厉害的字典。
压缩软件用这3个key加密所有包中的文件,也就是说,所有文件的key是一样的,如果我们能够找到这个key,就能解开所有的文件。
如果找到【加密压缩包中的任意一个文件】,这个文件和压缩包里的文件是一样的,我们把这个文件用同样的压缩软件同样的压缩方式进行【无密码的压缩】,得到的文件就是的Known plaintext(已知明文)。 用这个无密码的压缩包和有密码的压缩包进行比较,分析两个包中相同的那个文件,抽取出【两个文件的不同点】,就是那3个key了,如此就能得到key。
两个相同文件在压缩包中的字节数应该相差12个byte,就是那3个key了。
虽然还是无法通过这个key还原出密码,但是已经可以用这个key解开所有的文件,所以已经满足的要求了,可以得到解压后的文件了(但是没有得到密码本身)。
已知明文攻击原理 引用自:https://geekdaxue.co/read/jianouzuihuai@ctf/ltxa3h#72xuy
流量分析
.pcap/.pcapng 文件一般使用 Wireshark 分析。
Wireshark的基本使用
使用显示过滤器(Display Filter)
- 基础协议过滤
| 目的 | 命令 |
|---|---|
| 只看 HTTP 流量 | http |
| 只看 TCP 流量 | tcp |
| 只看 UDP 流量 | udp |
| 只看 DNS 流量 | dns |
| 只看 ICMP 流量 | icmp |
- 按 IP 地址过滤
| 目的 | 命令 |
|---|---|
| 包含某 IP 的流量 | ip.addr == 192.168.1.100 |
| 只看源 IP | ip.src == 192.168.1.100 |
| 只看目标 IP | ip.dst == 192.168.1.100 |
| 排除某 IP | !(ip.addr == 192.168.1.100) |
- 按端口过滤
| 目的 | 命令 |
|---|---|
| 看端口 80(HTTP) | tcp.port == 80 |
| 看端口 443(HTTPS) | tcp.port == 443 |
| 看端口 22(SSH) | tcp.port == 22 |
| 看端口范围 | tcp.port >= 3000 && tcp.port <= 4000 |
| 看源端口 | tcp.srcport == xxx |
| 看目标端口 | tcp.dstport == xxx |
- Web 流量分析
| 目的 | 命令 |
|---|---|
| 看所有 GET 请求 | http.request.method == "GET" |
| 看所有 POST 请求 | http.request.method == "POST" |
| 看 URI 中含 “flag” 的请求 | http.request.uri contains "flag" |
| 看响应中包含某字符串 | http contains "flag" |
| 看状态码为 200 的响应 | http.response.code == 200 |
| 看状态码为 404 或 500 | http.response.code == 404 or http.response.code == 500 |
- DNS 流量分析(找隐藏域名)
| 目的 | 命令 |
|---|---|
| 看所有 DNS 查询 | dns.qry.name |
| 看查询中包含某关键词 | dns.qry.name contains "flag" |
| 看 DNS 响应中含某 IP | dns.resp.addr == 1.2.3.4 |
- TCP 异常流量(攻击行为)
| 目的 | 命令 |
|---|---|
| 看 TCP 重传 | tcp.analysis.retransmission |
| 看 TCP 乱序 | tcp.analysis.out_of_order |
| 看 TCP RST 包 | tcp.flags.reset == 1 |
| 看 TCP SYN 扫描 | tcp.flags.syn == 1 and tcp.flags.ack == 0 |
- 高级组合过滤
| 目的 | 命令示例 |
|---|---|
| 看192.168.1.100访问外部Web的所有请求 | ip.src == 192.168.1.100 && tcp.dstport == 80 |
| 看所有非HTTPS的出站流量 | ip.src == 192.168.1.100 && tcp.dstport != 443 |
- 文件提取相关
| 目的 | 命令 |
|---|---|
| 看 HTTP 上传文件(POST) | http.request.method == "POST" and http.content_type contains "multipart" |
| 看 HTTP 下载文件(如 .zip) | http.response and http.content_type contains "application/zip" |
- 按 TCP 负载魔术签名过滤
| 文件类型 | 魔术签名(十六进制) | Wireshark 过滤器 |
|---|---|---|
| PNG | 89 50 4E 47 |
tcp.payload[0:4] == 89:50:4e:47 |
| JPG/JFIF | FF D8 FF E0 |
tcp.payload[0:4] == ff:d8:ff:e0 |
| GIF89a | 47 49 46 38 39 61 |
tcp.payload[0:6] == 47:49:46:38:39:61 |
| ZIP(含 docx/jar/apk) | 50 4B 03 04 |
tcp.payload[0:4] == 50:4b:03:04 |
使用统计分析流量包
- 统计 → 会话(Conversations) → TCP,按 Bytes 排序,分析大文件传输。
追踪流(Follow Stream)
- 右键任包 → Follow → TCP Stream / HTTP Stream → 拼出完整数据流。
- 如果看到“乱码”→ 把下方下拉框改成 Raw → Save Data 存成二进制,再 file 一下即可识别格式(图片、zip、mp3…)。
提取文件(两种方法)
- 自动导出
File → Export Objects → HTTP/DICOM/SMB…
一键列出所有可导出文件,按 Size 排序最快。 - 手动 carving
选中 PNG/JPG 起始包 → Follow TCP Stream → Raw → Save → 改后缀 .png。
如果文件被分片,用tcp.stream eq X过滤后再 Export。
解密 HTTPS
- 有 server 私钥
Edit → Preferences → Protocols → TLS → (RSA keys list) 填 IP:Port:protocol:key.pem。 - 有浏览器 key log(最通用)
设置环境变量SSLKEYLOGFILE=C:\tmp\keys.log,再抓包;
同一窗口把 keys.log 路径填进 TLS → (Pre)-Master-Secret log filename。
成功会看到 TLS 层出现 “Decrypted TLS” 标签,http2 也直接展开。
时间线与统计
- Statistics → Flow Graph → TCP flows
一眼看握手、重传、RST。 - Statistics → I/O Graph
画吞吐曲线,找“突发流量”藏文件瞬间。 - Analyze → Expert Information
红色报错常是“异常包”,提示 CTF 作者埋的彩蛋。
快捷键
Ctrl+F 字符串搜索,选 “Packet bytes” 搜 flag{。
Ctrl+N/P 跳到下一/前一个对话(过滤后)。
Ctrl+Shift+X Follow Stream 直接导出原始数据。
Ctrl+Q 退出(习惯先保存:File → Save As → “解题编号.pcapng”)。
做题基本思路
http contains "flag"- 筛选
tcp→ 会话(Conversations) 看最大流 → Follow → Save Data → file → 找 flag。 - 若全是 TLS → 看有没有 key log → 无则搜 SNI / Certificate 找域名提示。

