- DINOv3
- TL;DR
- Method
- Data
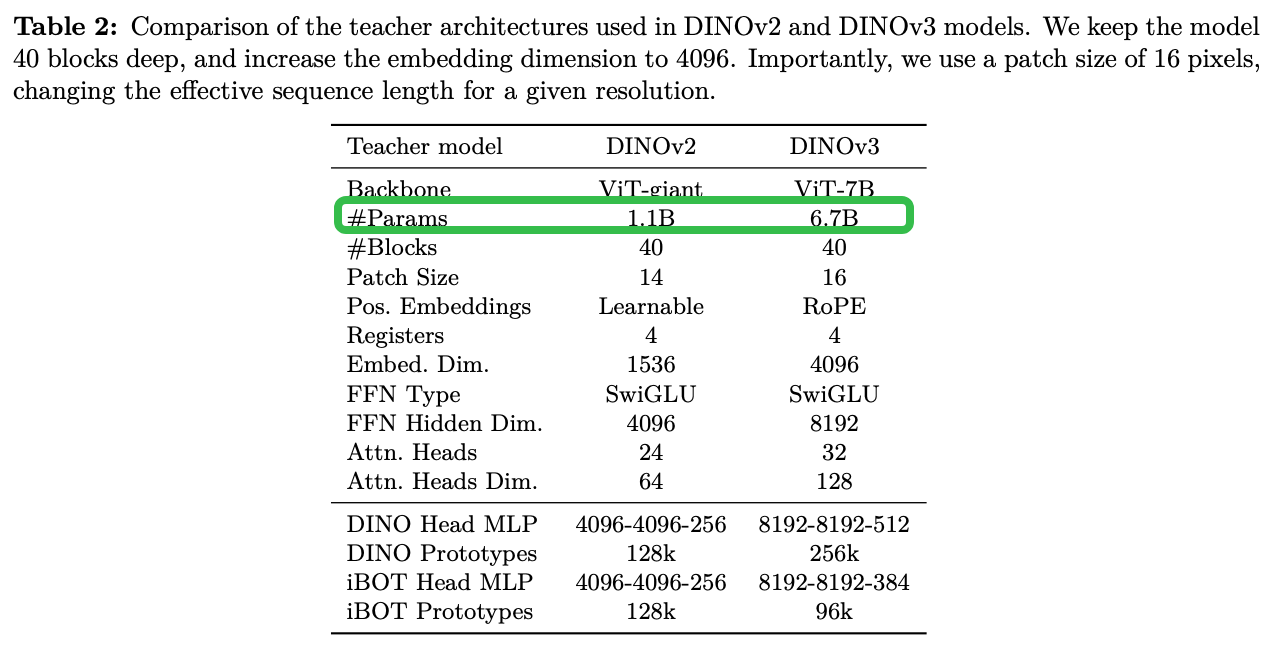
- Architecture
- Learning Objective
- Gram Anchoring Objective
- Leveraging Higher-Resolution Features
- post-hoc strategies
- Experiment
- 相关链接
DINOv3
link
时间:25.08
单位:Meta
相关领域:Self Supervised Learning
作者相关工作:
被引次数:7
项目主页:https://ai.meta.com/dinov3/
TL;DR
Dinov3主要改进:
- careful data preparation, design, and optimization;
- 提出Gram anchoring,解决long-term training过程dense feature效果变差问题;
- 提出post-hoc strategies,增强模型在分辨率、模型大小和与文本对齐方面的灵活性;
Method
Data
- 大规模数据集:利用大规模的未标注数据集,如 Instagram 上的 17B 亿张图片,通过自动数据筛选方法(如基于聚类的筛选)获得1.7B高质量数据;
- 通过给定任务中的seed数据,在数据池中检索出相关数据集,并结合相关任务上的公开数据集;
- 数据混合:结合不同的数据集部分,包括通过聚类筛选的数据、基于检索筛选的数据和原始公开数据集,以平衡数据的多样性和实用性;
Architecture
Learning Objective
具体包括以下三个部分:
✅ (1) DINO损失(\(L_{DINO}\))
作用:用于图像级别的特征学习。
原理:通过对比不同视角(crop)下的图像,鼓励模型对同一图像的不同部分产生一致的特征表示。
机制:使用Sinkhorn-Knopp归一化(来自SwAV)来替代DINOv2中的centering操作,提升稳定性。
✅ (2) iBOT损失(\(L_{iBOT}\))
作用:用于局部(patch)级别的特征学习。
原理:通过掩码部分图像块(类似BERT的mask建模),让模型预测被遮挡部分的特征,从而学习更细粒度的空间信息。
机制:在patch级别上进行自监督重建,增强模型对图像局部结构的理解。
✅ (3) Koleo正则化(\(L_{Koleo}\))
作用:防止特征坍缩(collapse),即所有图像特征趋同。
原理:鼓励一个batch内的图像特征在特征空间中均匀分布,避免过度聚集。
实现:在小批量(16个样本)上计算,跨GPU分布式实现。
Gram Anchoring Objective
**Motivation: **模型变大后,随着训练延长,global特征变好,但是dense特征变差。作者通过Figure 6分析红点与其它区域的相似性,发现训练后期同一物体训练后期patch-level的相似性在变差,而patch-level特征与cls token相似性在变高(参见Figure 5a)。
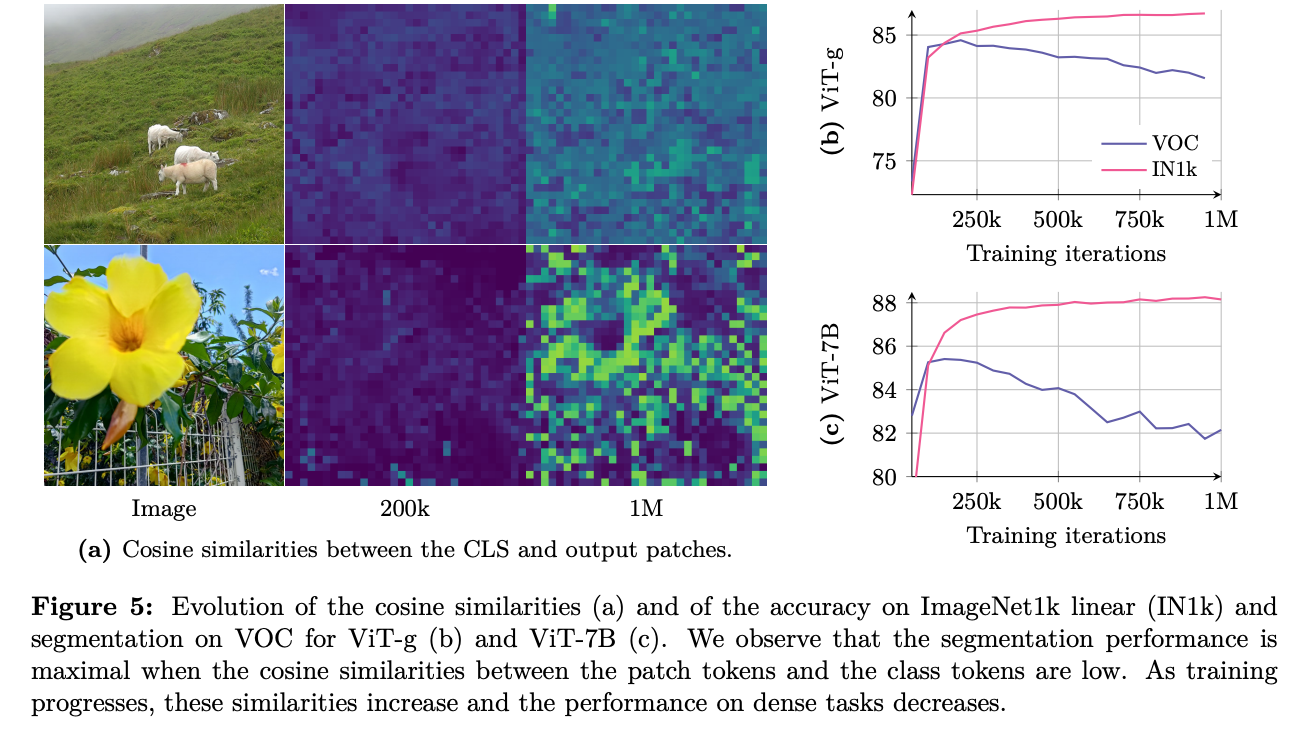

方法:
Q:什么是Gram Matrix?
G = X·Xᵀ,patch i 与 patch j 的cosine 相似度所构成的矩阵。
Q:Gram Matrix如何提升dense特征的表征能力?
早期某个 checkpoint(当作教师)的 Gram 矩阵 Gᵗ 当作锚点,让学生矩阵 Gˢ 去逼近它,教师权重每 10k 步更新一次。
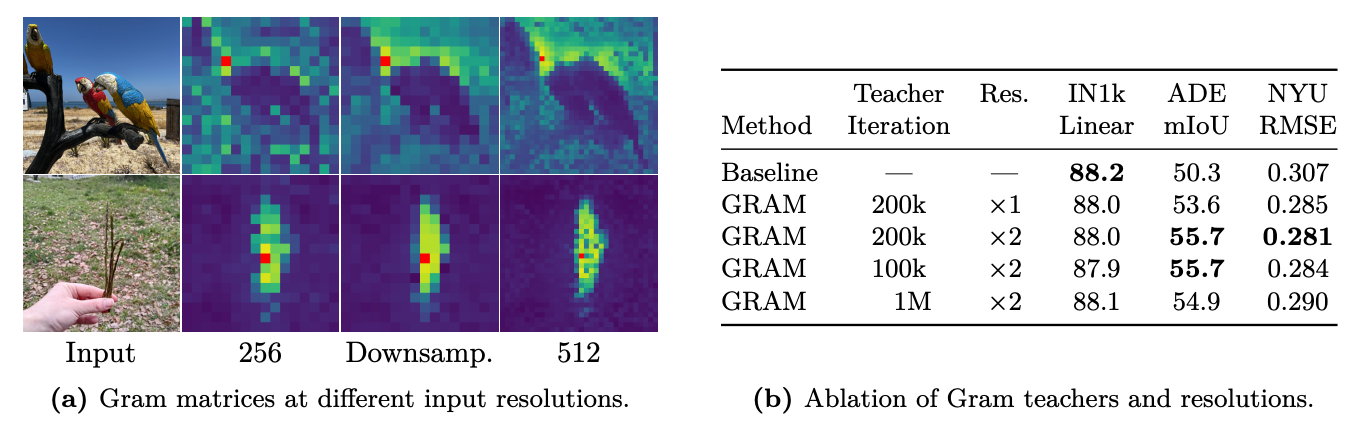
Leveraging Higher-Resolution Features
做法:高分辨率教师 → 下采样 Gram 矩阵
只让教师模型吃高分辨率图,得到patch特征后,将特征图下采样回原始分辨率,在下采样后的特征上计算 Gram 矩阵,作为新的锚点 Gᵗ:
学生仍在原始分辨率上训练,损失函数形式不变,计算量只增加 <10%。
![]()
post-hoc strategies
事后(post-hoc)给它配一个文本编码器,让视觉特征既能做密集任务,又能零样本做开放词汇分类、检索、分割,而整个视觉 backbone 始终冻结。
总体策略:LiT(Locked-image Tuning),图像编码器冻结,只训文本编码器。
Q:文本对齐的什么视觉特征?
视觉侧输入:CLS token + 平均 patch token
Q:文本Transformer如何训练?
标准 Transformer 从头训,文本编码器 从零初始化,采用 BERT-base 规模(12 层,768 dim)。
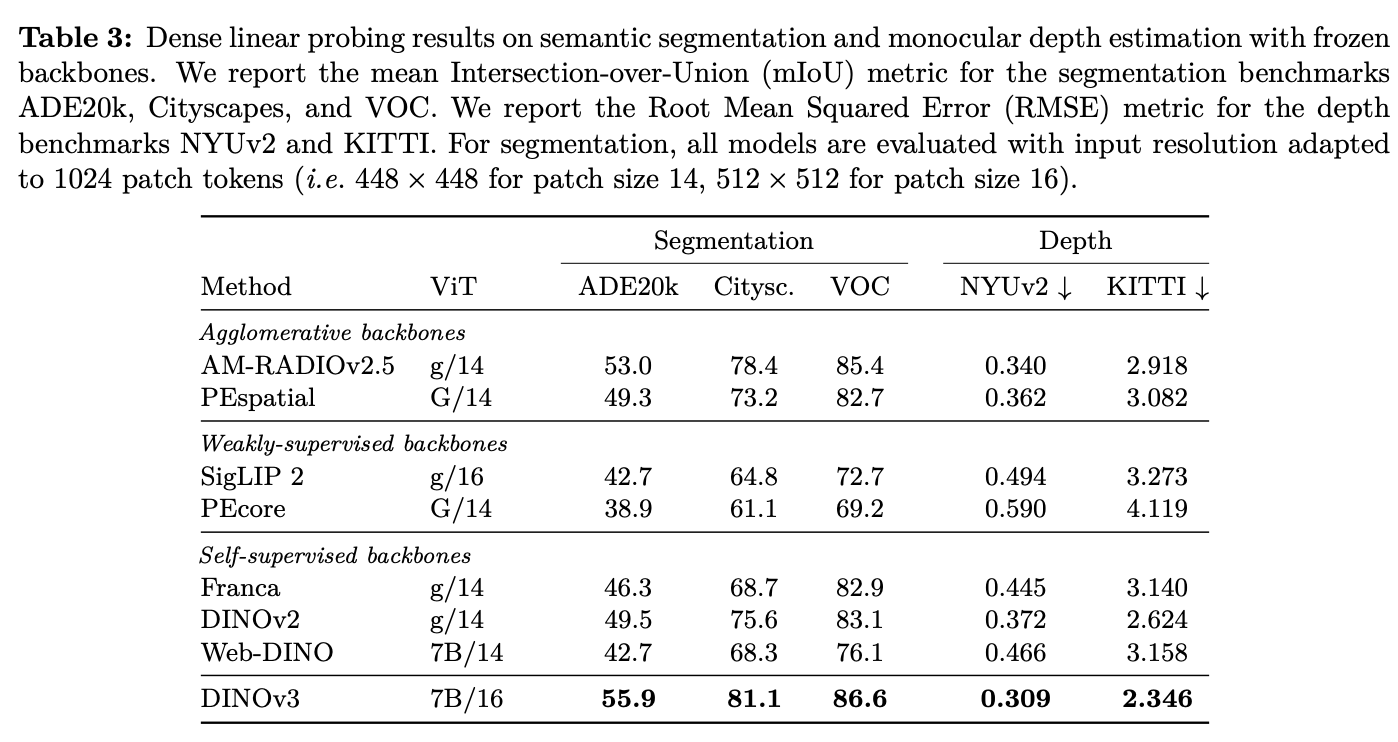
Experiment

相关链接
https://zhuanlan.zhihu.com/p/1940400858836742367