作者:孙玉梅
背景
AI 时代海量交互数据推动智能应用快速发展,但其中的个人隐私信息也带来严峻的安全挑战。数据脱敏已从可选项转变为企业合规经营的必需品。
- 合规需求日趋严格:随着 GDPR(通用数据保护条例)、《数据安全法》、《个人信息保护法》等法律法规的相继出台,个人身份信息、财务记录、医疗数据等敏感信息一旦泄露,企业不仅面临天价罚款,更会遭遇信任危机。
- 安全保障刻不容缓:通过定期敏感数据扫描和脱敏处理,可有效防止未授权访问和数据泄露,提升数据治理水平和系统整体安全性。
SLS 现有脱敏方案:多元化的数据保护体系
阿里云日志服务(SLS)早已构建了完善的数据脱敏处理体系,提供了 3 种灵活的采集+脱敏 Pipeline 组合流程,满足不同业务场景的需求:
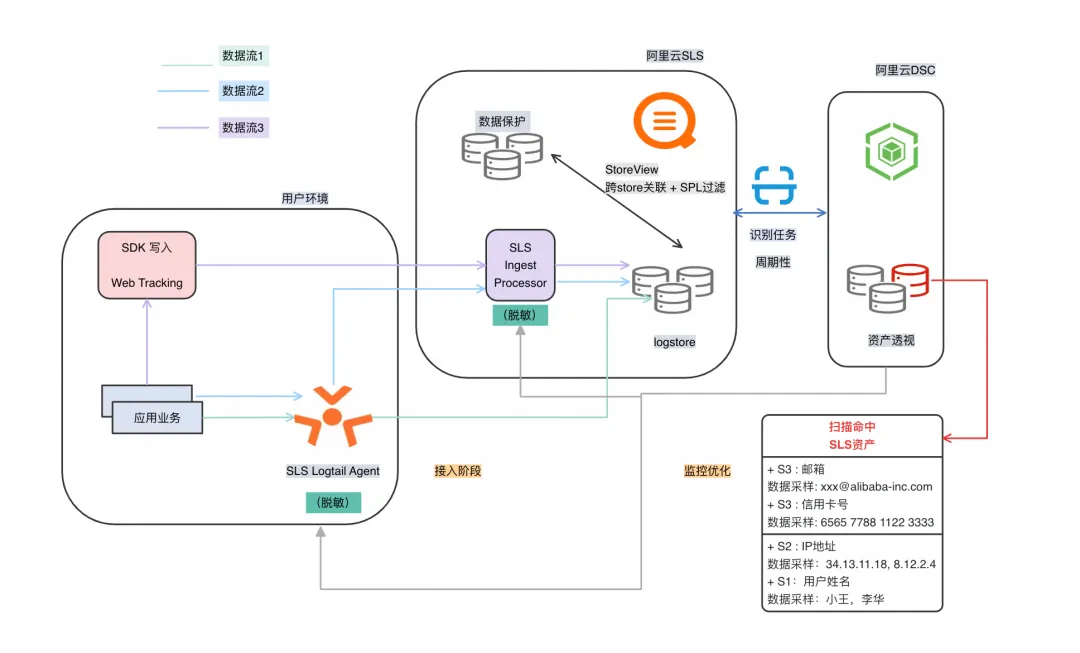
🔹 Logtail 端侧脱敏
- 处理插件模式:通过配置数据脱敏插件,基于正则匹配完成敏感字段的精准替换
- SPL 语句模式:通过多级处理语句配置 SPL 解析,实现灵活的端侧脱敏处理
🔹 Logtail + Ingest Processorer 联合脱敏
- Logtail 端专注数据采集,Ingest Processorer 承担脱敏处理,避免端侧资源过度占用
- 通过 SPL 语句使用 regexp_replace 正则表达式函数,在服务侧完成高性能脱敏处理
🔹 SDK + Ingest Processorer 组合脱敏
- 基于 SDK 接口调用完成日志写入
- 通过 IngestProcessor 里设置脱敏语句(也是使用 regexp_replace 正则表达式函数),脱敏处理在日志服务中完成,不占用端侧资源
关于这些脱敏方案的详细配置和最佳实践方案,可参考文章:云上数据安全保护:敏感日志扫描与脱敏实践详解 [ 1] 。
升级之路:mask 函数简化脱敏操作
上述三种脱敏方案已能满足绝大部分场景的需求,其核心能力主要基于正则表达式匹配。然而,尽管正则表达式功能强大,但在处理日益复杂的数据场景时,其固有的局限性也逐渐凸显:
⚡ 配置复杂度激增: 处理十多种敏感信息类型需要编写数十个复杂正则表达式,维护成本呈指数级增长。
⚡ 性能瓶颈凸显: 多重嵌套的正则表达式操作会严重拖慢实时处理性能。
⚡ 场景适配困难: JSON、URI、纯文本的混合日志格式中,难以用统一正则配置高效处理。
为此,SLS 推出全新的脱敏函数(mask)。
mask 函数脱敏方案介绍
mask 函数能够对结构化和非结构化日志中的海量敏感数据进行精准识别和脱敏。该函数目前已在 SLS 数据处理器(Ingest Processor)中上线,后续将逐步扩展到 LoongCollector 等更多应用场景,为用户提供更加便捷、高效、智能的数据脱敏体验。下面介绍如何在 SLS IngestProcessor 中使用 mask 脱敏函数。
mask 脱敏函数
函数语法
mask(field, varchar params)
- 参数说明:

模式介绍:
keyword 模式:智能识别任意文本中符合"key":"value"、'key':'value'或key=value 等常见 KV 对格式的敏感信息。
buildin 模式:支持邮箱、手机号(国内)、身份证、固话(国内)、IP、信用卡 6 种内置规则。
- SPL 使用示例
* | extend content = mask(content,'[
{"mode":"buildin", "types" : ["EMAIL", "PHONE"]},
{"mode":"keyword", "keys":["userName"], "maskChar":"*", "keepPrefix":2,"keepSuffix":1},
]')
数据处理器
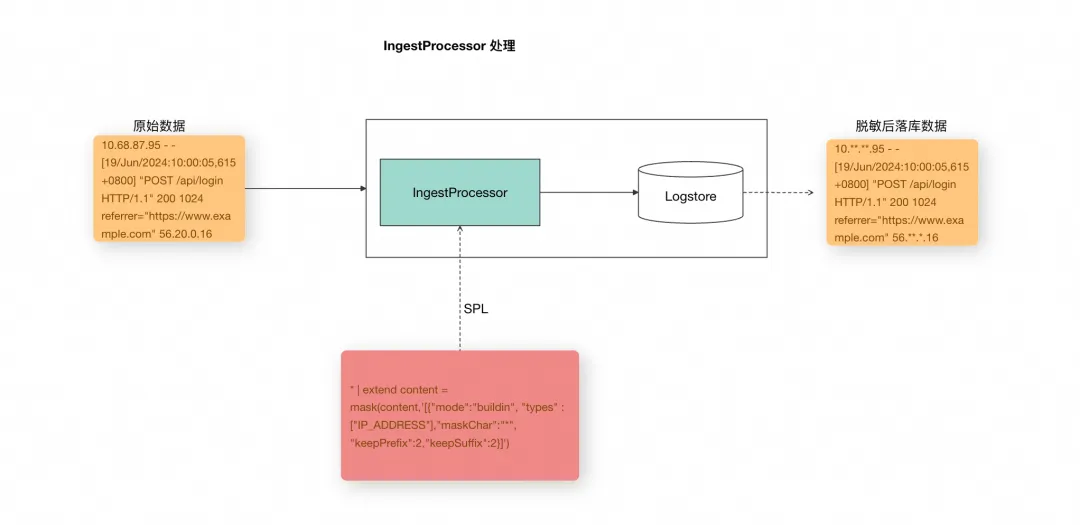
IngestProcessor [ 2] 可以对数据进行预处理,例如数据过滤、字段提取、字段扩展、数据脱敏等场景。下图是使用数据处理器对原始数据,利用 SPL 配置脱敏函数规则,对 IP 地址进行脱敏处理的示例图。
性能对比
我们在 SLS Ingestion 端到端环境中与正则脱敏方式进行了对比测试。
- 测试数据规模:数据包大小从 70KB 到 7MB
- 脱敏复杂度:分别配置 1 个 keyword、3 个 keyword、100 多 keyword + 6 个 buildin 规则
- 性能指标:平均处理延迟(ms)
测试结果如下:
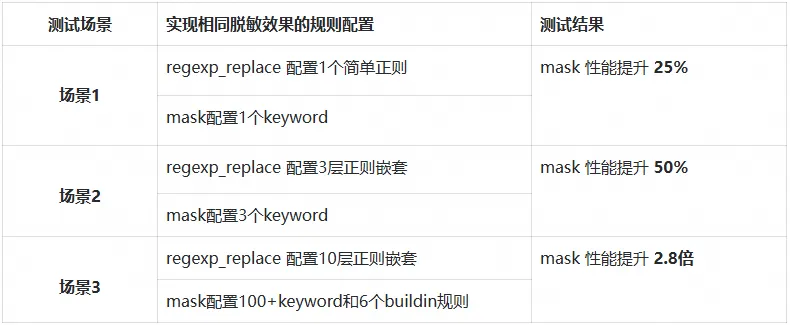
mask 脱敏函数相比正则方式具有更高的处理效率,特别适用于大数据量和复杂脱敏需求的场景。
使用案例
声明:下述案例中所有原始日志均为 AI 模拟构造的数据。
案例一:交易数据脱敏实践
在金融科技、区块链等场景下,交易日志往往以复杂的嵌套 JSON 格式记录,其中包含了大量的用户钱包地址、IP、电话号码等高度敏感信息。mask 函数的 keyword 模式可以精准地深入 JSON 结构,对指定字段进行脱敏,同时保持日志的整体结构和可读性。
需求
DeFi 平台每日处理数万笔链上交易,每笔交易都会生成包含用户钱包地址、交易哈希、用户画像等敏感信息的详细日志。为了满足数据保护法规要求,同时保证业务分析和故障排查的需要,需要对交易确认日志中的 钱包地址、地址信息、来源 IP、手机号、交易哈希等敏感字段进行脱敏,保留前后各 3 位字符以便业务追溯。
- 原始日志:
2025-08-20 18:04:40,998 INFO blockchain-event-poller-3 [10.0.1.20] [com.service.listener.TransactionStatusListener:65] [TransactionStatusListener#handleSuccessfulTransaction]{"message":"On-chain transaction successfully confirmed","confirmationDetails":{"transactionHash":"0x2baf892e9a164b1979","status":"success","blockNumber":45101239,"gasUsed":189543,"effectiveGasPrice":"58.2 Gwei","userProfileSnapshot":{"wallet":"0x71C7656EC7a5f6d8A7C4","sourceIp":"203.0.113.55","phone":"19901012345","address":"上海市浦东新区文明路1000号","birthday":null}}}
脱敏配置
- SPL:使用 keyword 模式,一次性处理多个敏感字段
*| extend content = mask(content,'[
{"mode":"keyword","keys":["wallet","address","sourceIp","phone","transactionHash","sourceIp"], "maskChar":"*","keepPrefix":3,"keepSuffix":3}
]')
- 配置数据处理器
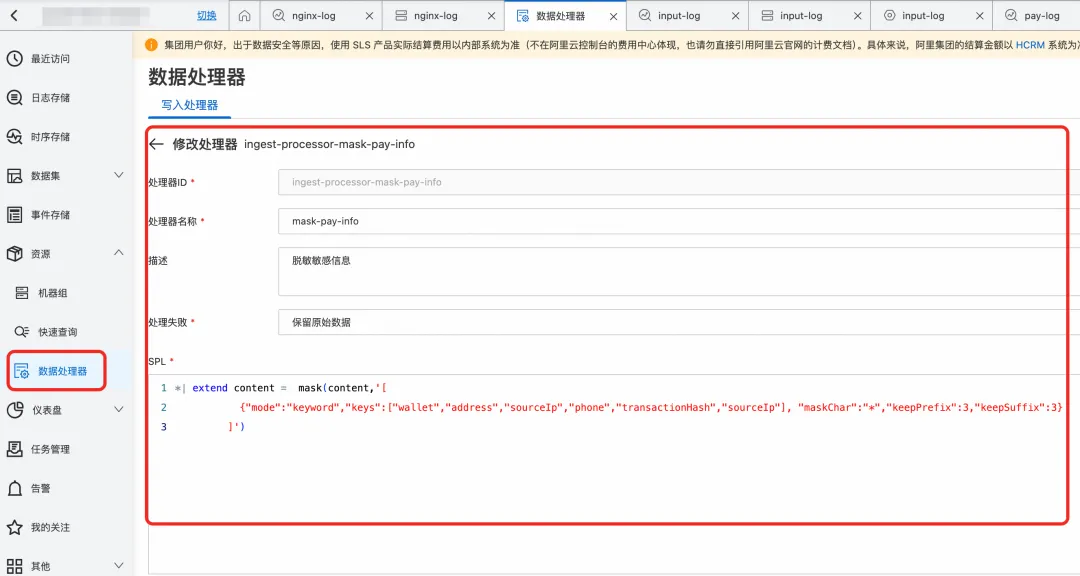
脱敏效果
如下是脱敏后的 logstore 中日志展示,可以看到通过一条配置精准脱敏了所有敏感字段,既保护了用户隐私安全,又保留了完整的业务逻辑和可追溯性。

案例二:大模型交互日志脱敏
大模型交互日志是典型的非结构化数据,用户输入内容完全不可控,可能包含各类 PII 信息。传统的脱敏方案在面对如此多样化、非结构化的文本时,往往需要维护数十个正则表达式,不仅准确率低,还极易出现遗漏。mask 函数的 buildin 模式此时便能大显身手,仅需在函数中配置开启的脱敏 types,即可自动发现并脱敏文本中符合内置规范的各类敏感数据,为 AI 应用提供强大的安全屏障。
需求
智能客服平台每日处理超过 10 万次用户咨询,用户经常在求助时无意中透露手机号、身份证、银行卡等敏感信息。需要自动识别并脱敏用户输入中的手机号、邮箱、 IP 地址、身份证号和信用卡号等敏感信息,在保护隐私的同时保留语义完整性,为后续的 AI 训练和分析提供安全、可用的数据。
- 原始日志:这是一条用户向 AI 客服求助的完整对话记录,包含了几乎所有常见的 PII 类型
你好,我需要紧急帮助!我是你们平台的长期付费用户,我的账户好像被锁定了,而且一笔年度会员续费失败了。我非常着急,因为我今晚需要使用你们的高级功能来完成一个项目
以下是我的全部信息,请你们的系统管理员或技术支持立刻为我核实并解决问题:
姓名 张伟
注册手机号是 19901012345
注册邮箱是 zhangwei.service@example.com
我最近一次登录的IP地址 203.0.113.55
身份证号是 110105199003070033
用于支付的信用卡信息如下:
信用卡类型 Visa
卡号是 4539-1488-0343-6467
持卡人姓名 ZHANG WEI
有效期 12/25
CVV码 123
请尽快处理,万分感谢!我真的非常需要你们的帮助!
脱敏配置
- SPL 配置:使用 buildin 模式,智能识别多种敏感信息类型。
- 配置说明:
- 第一条规则:对 IP 地址和邮箱进行完全脱敏(默认用
*全部替换) - 第二条规则:对手机号、身份证号、信用卡号进行部分脱敏,保留前 3 位后 4 位
- 第一条规则:对 IP 地址和邮箱进行完全脱敏(默认用
* | extend content = mask(content,'[
{"mode":"buildin","types":["IP_ADDRESS","EMAIL","LANDLINE_PHONE"]},
{"mode":"buildin","types":["PHONE","IDCARD","CREDIT_CARD"], "maskChar":"*","keepPrefix":3,"keepSuffix":4}
]')
脱敏效果
通过内置的脱敏规则,智能识别并脱敏了文本中的敏感信息,在完全保护用户隐私的同时,保持了对话内容的语义完整性和可读性。

案例三:Nginx日志中敏感URI参数脱敏实践
访问日志详细记录了用户的每一次访问行为,是故障排查、性能优化和安全审计的重要依据。然而,URI 参数中往往包含用户 ID、会话 Token、API 密钥等高度敏感信息,是数据泄露的高危区域。用户 ID、会话 Token 等参数往往直接暴露在 URL 中。mask 的 keyword 模式能精准识别 key=value 格式,对 URI 中的特定参数进行定向“打码”。
需求
某电商平台的 API 网关每日处理数千万次请求,现需要对 URI 里的 uid 和 token 参数进行脱敏,保留前后各 2 位字符。
- 原始日志:这是一条典型的 API 访问日志 URI,包含了用户身份信息和会话认证信息
uri: "uid=user12345&token=bf81639a41d604&from=web"
脱敏配置
使用 keyword 模式,定位 URI 参数进行选择性脱敏。
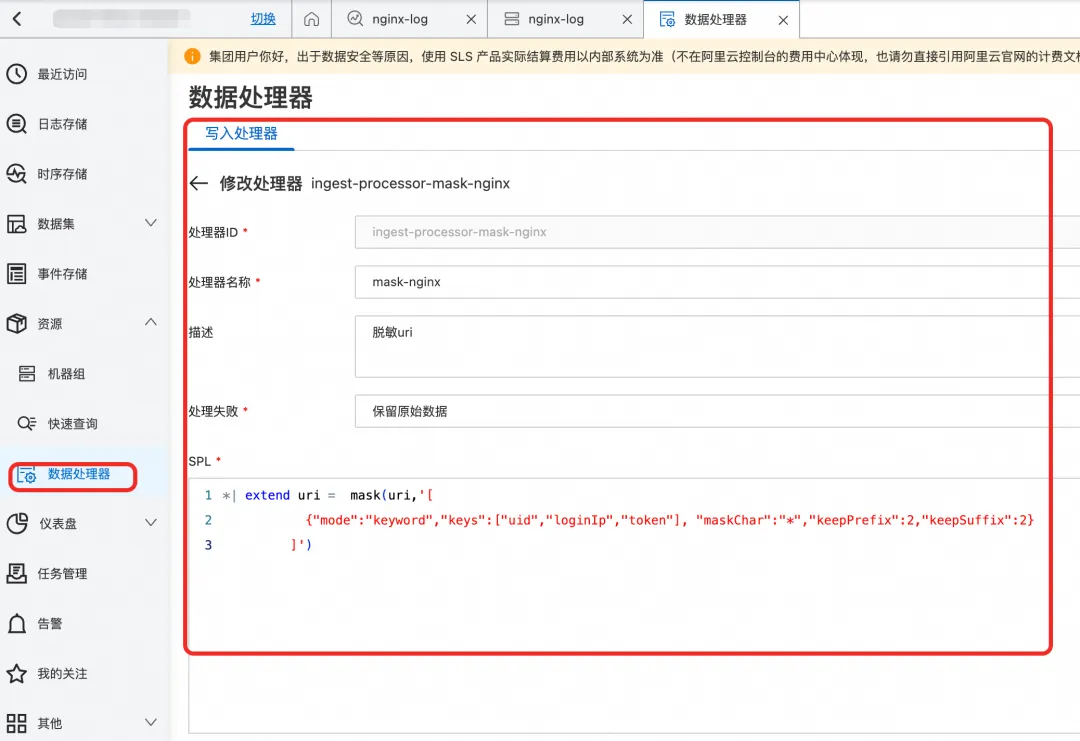
脱敏效果

实现了选择性精准脱敏,敏感参数被安全隐藏,非敏感参数完整保留,在保护隐私的同时最大化保持了日志的分析价值。
- uid 参数:从 user12345 脱敏为 us*******45。
- token 参数:从 bf81639a41d604 脱敏为 bf**********04,防止会话劫持。
- from 参数:保持 web 不变,维持业务分析价值。
相关链接:
[1] 云上数据安全保护:敏感日志扫描与脱敏实践详解
https://developer.aliyun.com/article/1645590
[2] IngestProcessor
https://help.aliyun.com/zh/sls/sls-write-processor/
点击此处,了解更多产品详情。