(一)线程池核心知识
-
线程池原理、创建原因与方式
- 原理:通过统一
管理线程资源,实现线程复用,避免频繁创建 / 销毁线程的性能损耗,同时对线程执行流程进行调度与监控。 - 创建原因:减少线程生命周期管理开销,提升系统响应速度;控制并发线程数量,防止资源耗尽;便于线程执行状态监控与异常处理。
- 创建方式:主要有
ThreadPoolExecutor、ThreadScheduledExecutor、ForkJoinPool三种核心方式。
- ThreadPoolExecutor方式创建
package thread;import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.Executors; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit;public class ThreadPoolExecutorDemo {private static final ThreadPoolExecutor executor = new ThreadPoolExecutor(2,//corePoolSize:核心线程数5,//maximumPoolSize:最大线程数60,//keepAliveTime:非核心线程空闲存活时间TimeUnit.SECONDS,//时间单位new ArrayBlockingQueue<>(10),//任务队列(容量10)Executors.defaultThreadFactory(),//线程工厂new ThreadPoolExecutor.AbortPolicy()//拒绝策略(默认:抛异常));public static void main(String[] args) {//Lambda表达式写法 // executor.execute(() -> System.out.println("执行任务:"+Thread.currentThread().getName()));//正常匿名内部类写法executor.execute(new Runnable() {@Overridepublic void run() {System.out.println("执行任务:" + Thread.currentThread().getName());}});executor.shutdown();//关闭线程池} } - ThreadScheduledExecutor创建线程方式
package thread; import java.util.Date; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;/*** 使用Lambda表达式写法*/ public class ScheduledExecutorLambdaDemo {// 创建ScheduledExecutorService(核心线程数为2)// 实际是返回ThreadScheduledExecutor的实例private static final ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(2);public static void main(String[] args) {// 1. 延迟执行任务(延迟3秒后执行一次)System.out.println("提交延迟任务:" + new Date());scheduledExecutor.schedule(() -> {System.out.println("延迟任务执行:" + new Date());}, 3, TimeUnit.SECONDS);// 2. 周期性执行任务(初始延迟2秒,之后每4秒执行一次)// 注意:周期是以上一次任务结束时间开始计算System.out.println("提交周期性任务:" + new Date());scheduledExecutor.scheduleAtFixedRate(() -> {System.out.println("周期性任务执行:" + new Date());try {// 模拟任务执行耗时1秒Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}, 2, 4, TimeUnit.SECONDS);// 3. 固定延迟执行任务(初始延迟2秒,上一次任务结束后延迟3秒再执行)System.out.println("提交固定延迟任务:" + new Date());scheduledExecutor.scheduleWithFixedDelay(() -> {System.out.println("固定延迟任务执行:" + new Date());try {// 模拟任务执行耗时1秒Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}, 2, 3, TimeUnit.SECONDS);// 运行一段时间后关闭线程池(示例:20秒后关闭)scheduledExecutor.schedule(new Runnable() {@Overridepublic void run() {scheduledExecutor.shutdown();System.out.println("线程池已关闭");}}, 20, TimeUnit.SECONDS);// 运行一段时间后关闭线程池(示例:20秒后关闭)scheduledExecutor.schedule(() -> {scheduledExecutor.shutdown();System.out.println("线程池已关闭");}, 20, TimeUnit.SECONDS);} }package thread;import java.util.Date; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;/*** 使用匿名内部类写法*/ public class ScheduledExecutorDemo {// 创建ScheduledExecutorService(核心线程数为2)// 实际是返回ThreadScheduledExecutor的实例private final static ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(2);public static void main(String[] args) {// 1. 延迟执行任务(延迟3秒后执行一次)System.out.println("提交延迟任务:" + new Date());scheduledExecutor.schedule(new Runnable() {@Overridepublic void run() {System.out.println("延迟任务执行:" + new Date());}}, 3, TimeUnit.SECONDS);// 2. 周期性执行任务(初始延迟2秒,之后每4秒执行一次)System.out.println("提交周期性任务:" + new Date());scheduledExecutor.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println("周期性任务执行:" + new Date());try {// 模拟任务执行耗时1秒Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}, 2, 4, TimeUnit.SECONDS);// 3. 固定延迟执行任务(初始延迟2秒,上一次任务结束后延迟3秒再执行)System.out.println("提交固定延迟任务:" + new Date());scheduledExecutor.scheduleWithFixedDelay(new Runnable() {@Overridepublic void run() {System.out.println("固定延迟任务执行:" + new Date());try {// 模拟任务执行耗时1秒Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}, 2, 3, TimeUnit.SECONDS);// 运行一段时间后关闭线程池(示例:20秒后关闭)// 使用传统匿名内部类写法替代lambda表达式scheduledExecutor.schedule(new Runnable() {@Overridepublic void run() {scheduledExecutor.shutdown();System.out.println("线程池已关闭");}}, 20, TimeUnit.SECONDS);} } - ForkJoinPool创建线程
package thread;import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveTask;public class ForkJoinPoolDemo {public static void main(String[] args) {// ==================== 1. 创建ForkJoinPool的几种方式 ====================// 1.1 使用默认构造(推荐)// 核心线程数 = CPU核心数,使用默认线程工厂和异常处理器ForkJoinPool defaultPool = new ForkJoinPool();// 1.2 手动指定并行度(核心线程数)// 参数:parallelism - 并行度(通常设为CPU核心数)int parallelism = Runtime.getRuntime().availableProcessors(); // 获取CPU核心数ForkJoinPool customPool = new ForkJoinPool(parallelism);// 1.3 完整参数构造(自定义线程工厂、异常处理器等)/*ForkJoinPool fullPool = new ForkJoinPool(parallelism, // 并行度(核心线程数)ForkJoinPool.defaultForkJoinWorkerThreadFactory, // 线程工厂null, // 未捕获异常处理器(null使用默认)false // 是否为异步模式(通常用false));*/// ==================== 2. 示例:使用ForkJoinPool计算数组总和 ====================int[] array = new int[1000];for (int i = 0; i < array.length; i++) {array[i] = i + 1; // 填充1~1000}// 创建任务(继承RecursiveTask,有返回值)SumTask task = new SumTask(array, 0, array.length);// 提交任务并获取结果Integer result = customPool.invoke(task);System.out.println("数组总和:" + result); // 预期结果:500500// 关闭线程池customPool.shutdown();}// 自定义分治任务(计算数组指定区间的和)static class SumTask extends RecursiveTask<Integer> {private static final int THRESHOLD = 100; // 任务拆分阈值(小于此值直接计算)private int[] array;private int start;private int end;public SumTask(int[] array, int start, int end) {this.array = array;this.start = start;this.end = end;}@Overrideprotected Integer compute() {// 如果任务足够小,直接计算if (end - start <= THRESHOLD) {int sum = 0;for (int i = start; i < end; i++) {sum += array[i];}return sum;}// 否则拆分任务int mid = (start + end) / 2;SumTask leftTask = new SumTask(array, start, mid);SumTask rightTask = new SumTask(array, mid, end);// 并行执行子任务leftTask.fork(); // 拆分左任务rightTask.fork(); // 拆分右任务// 合并结果return leftTask.join() + rightTask.join();}} }
- 原理:通过统一
-
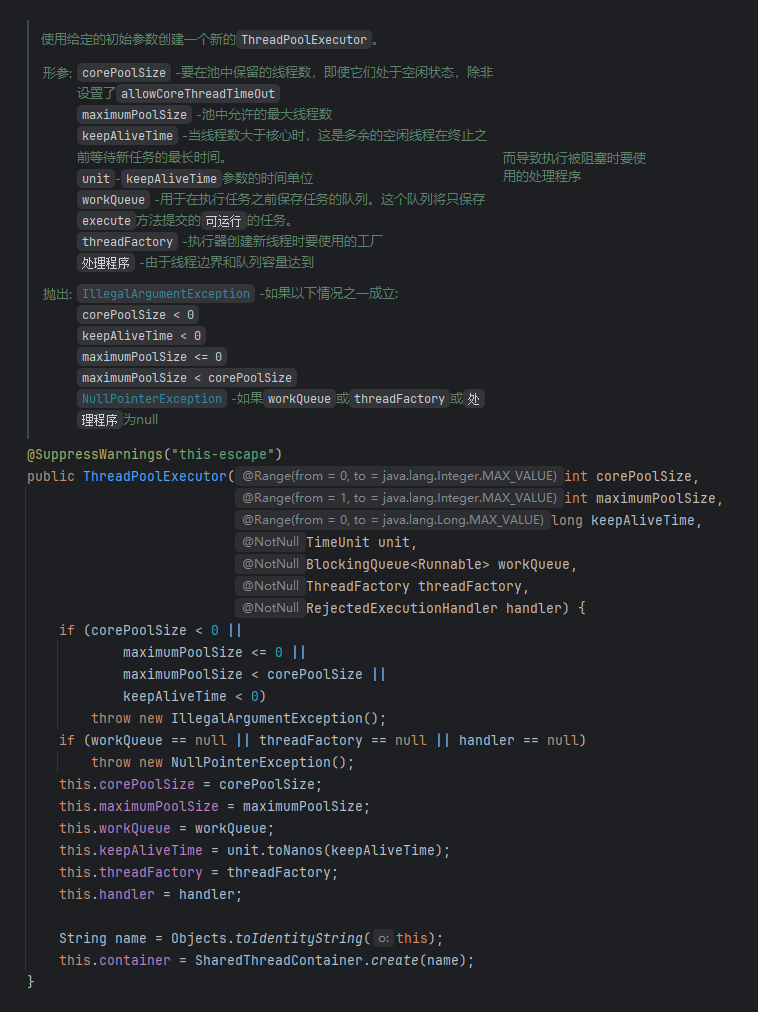
线程池核心参数与大小配置
![Snipaste_2025-09-16_11-05-08]()
- 核心参数:
ThreadPoolExecutor的核心参数包括corePoolSize(核心线程数)、maximumPoolSize(最大线程数)、keepAliveTime(空闲线程存活时间)、TimeUnit(存活时间单位)、workQueue(任务缓存队列)、threadFactory(线程创建工厂)、RejectedExecutionHandler(任务拒绝策略)。 - 参数工作逻辑:
- 线程数 <
corePoolSize:直接创建线程处理请求。 - 线程数 ≥
corePoolSize:将请求存入workQueue,空闲核心线程从队列取任务。 workQueue满:创建非核心线程,直至线程数达maximumPoolSize。- 线程数>
maximumPoolSize:触发RejectedExecutionHandler处理拒绝任务。
- 线程数 <
- 线程池大小配置策略:
- CPU 密集型任务:配置为
CPU核心数 + 1,减少线程切换损耗。 - IO 密集型任务:可选
CPU核心数 × 2,或按(线程等待时间/CPU时间 + 1) × CPU核心数计算。 - 混合型任务:拆分为
CPU 密集型与IO 密集型子任务,分别用独立线程池处理。
- CPU 密集型任务:配置为
- 核心参数:
(二)线程生命周期与安全
-
线程生命周期:包含
新建、可运行、运行、阻塞/等待、终止五个阶段,状态定义在Thread.State枚举中。状态枚举 核心含义 进入方式示例 NEW线程对象 已创建(new Thread()),但未调用start(),未分配系统资源Thread t = new Thread(); RUNNABLE调用start()后,线程具备运行条件(要么正在 CPU 执行,要么等待 CPU 调度)t.start(); BLOCKED竞争同步锁失败(如进入synchronized代码块但锁被占用),被迫阻塞线程 A 未释放锁时,线程 B 进入同一synchronized块 WAITIN无限期 等待被唤醒,无超时时间,需其他线程主动触发唤醒t.wait()、Thread.join()(无参) TIMED_WAITING限时等待,超时后自动唤醒,无需其他线程干预Thread.sleep(1000)、t.wait(1000) TERMINATED线程 执行完run()或因异常终止,生命周期彻底结束run()方法执行完毕、未捕获异常抛出 ![image]()
补充:3 种 “阻塞 / 等待状态” 的关键区别(避免混淆)
状态类型 唤醒条件 是否释放已持有锁 典型场景 BLOCKED锁被释放(其他线程解锁) 是(仅释放竞争的锁) 竞争 synchronized锁WAITING其他线程调用 notify()/notifyAll(),或join()的线程结束是(释放所有已持有锁) 调用无参 wait()、join()TIMED_WAITING超时自动唤醒,或提前被 notify()是(释放所有已持有锁) sleep()、有参wait() -
僵死进程:子进程退出时,父进程未处理其
SIGCHLD信号,导致子进程残留僵死状态,需等待父进程 “回收”,此类进程即为僵死进程。 -
线程安全实现方式
- 互斥同步(阻塞式)
通过锁定共享资源,保证同一时间只有一个线程访问。- synchronized 关键字:
隐式锁,自动获取和释放。package thread;public class SynchronizedDemo {private int count;// 修饰方法public synchronized void increment() {count++;}// 修饰代码块public void increment() {synchronized (this) { count++; }}} - ReentrantLock 显式锁:手动控制锁的获取和释放,支持中断、超时等高级特性。
package thread;import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock;public class ReentrantLockDemo {private int count = 0;private final Lock lock = new ReentrantLock();public void increment() {lock.lock();try {count++;} finally {lock.unlock(); // 必须手动释放}} }
- synchronized 关键字:
- 非阻塞同步(无锁式)
基于CAS(Compare-And-Swap)机制,无线程阻塞,效率更高。package thread;import java.util.concurrent.atomic.AtomicInteger;public class AtomicIntegerDemo {private static final AtomicInteger atomicCount = new AtomicInteger(0);public static void increment() {// 原子操作,底层依赖CASatomicCount.incrementAndGet();} } - 无同步方案
- 线程封闭:变量仅在单个线程内使用(如局部变量)。
- 不可变对象:用
final修饰共享对象,避免被修改(如 String)。 - ThreadLocal:为每个线程创建
独立变量副本,彻底避免共享。package thread;public class ThreadLocalDemo {private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);public static void increment() {threadLocal.set(threadLocal.get() + 1); // 每个线程操作自己的副本} }
- 互斥同步(阻塞式)

(三)关键字与锁
-
volatile 关键字
- 核心原理:
通过底层硬件指令(如 x86 的 Lock 前缀)实现两个核心保障:- 可见性:写操作会将变量从 CPU 缓存刷回主内存,读操作会直接从主内存加载,确保所有线程看到的变量值一致。
- 有序性:通过
内存屏障(Memory Barrier)禁止编译器和 CPU 对指令重排序,避免多线程下的执行顺序混乱(如 DCL 单例中的指令重排问题)。
- 局限性:
不保证原子性,例如 i++ 这类复合操作(读 - 改 - 写)在多线程下仍会出现数据不一致。 - 典型使用场景:
package thread;public class VolatileDemo {// 1. 私有静态变量,用volatile修饰防止指令重排序private static volatile VolatileDemo instance;// 2. 私有构造方法,防止外部直接实例化private VolatileDemo() {// 可选:防止反射破坏单例if (instance != null) {throw new RuntimeException("禁止通过反射创建实例");}}// 3. 公共静态方法,提供全局访问点public static VolatileDemo getInstance() {// 第一次检查:未加锁,快速判断(提高性能)if (instance == null) {// 加锁:只在第一次初始化时进入同步块synchronized (VolatileDemo.class) {// 第二次检查:防止多线程并发时重复创建if (instance == null) {// 这里涉及三个操作:// 1. 分配内存空间// 2. 初始化对象// 3. 将instance引用指向内存空间// volatile保证这三个步骤不会被重排序instance = new VolatileDemo();}}}return instance;}// 可选:防止反序列化破坏单例(如果需要序列化)private Object readResolve() {return instance;} }
- 核心原理:
-
ThreadLocal 线程本地存储
- 核心原理:
为每个线程创建变量的独立副本,线程只操作自己的副本,彻底避免共享。底层通过线程的ThreadLocalMap存储数据(ThreadLocal 实例作为 key,变量副本作为 value)。 - 适用场景:
变量需要 “线程私有” 但又需跨方法传递的场景,例如:- 数据库连接(
Connection):每个线程持有自己的连接,避免并发冲突。 - Web 开发中的
Session:每个请求线程独立处理自己的会话信息。
- 数据库连接(
- OOM 风险与避免:
线程池中的线程会被复用,若 ThreadLocal 变量不清理,会导致变量副本随线程长期存在,引发内存泄漏。
解决方法: 使用后主动调用remove()清理:package thread;import java.text.SimpleDateFormat; import java.util.Date; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit;public class ThreadLocalDateFormatDemo {// 1. 创建ThreadLocal,初始化SimpleDateFormat(指定格式)private static final ThreadLocal<SimpleDateFormat> DATE_FORMATTER = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));// 2. 创建线程池(模拟多线程环境)private static final ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(2);public static void main(String[] args) {// 3. 提交10个任务,测试线程安全for (int i = 0; i < 10; i++) {final int taskId = i;scheduledExecutor.submit(() -> {try {// 模拟任务执行时间Thread.sleep(100);// 调用工具方法格式化日期String formattedDate = formatDate(new Date());System.out.printf("任务%d:%s(线程:%s)%n", taskId, formattedDate, Thread.currentThread().getName());} catch (InterruptedException e) {Thread.currentThread().interrupt();}});}// 4. 关闭线程池scheduledExecutor.shutdown();try {scheduledExecutor.awaitTermination(1, TimeUnit.MINUTES);} catch (InterruptedException e) {scheduledExecutor.shutdownNow();}}// 5. 日期格式化工具方法(线程安全)public static String formatDate(Date date) {// 获取当前线程的SimpleDateFormat副本SimpleDateFormat sdf = DATE_FORMATTER.get();try {// 格式化日期(每个线程操作自己的副本,避免并发问题)return sdf.format(date);} finally {// 6. 清理ThreadLocal,避免线程池复用导致的内存泄漏DATE_FORMATTER.remove();}} }
- 核心原理:
-
synchronized 与 volatile 区别
对比维度 volatile synchronized 作用范围 仅修饰变量 修饰方法、代码块(可锁定对象 / 类) 线程阻塞 无阻塞(纯内存语义) 可能阻塞(锁竞争时进入 BLOCKED 状态) 原子性 不保证(仅可见性 / 有序性) 保证(临界区操作原子执行) 性能开销 极低(接近普通变量) 较高(锁获取 / 释放有开销) 适用场景 状态标志、简单通信 复杂逻辑的互斥同步(如计数器、资源竞争) 一句话总结:
volatile是 “轻量级” 的线程通信工具,synchronized是 “重量级” 的互斥同步工具。 -
synchronized 锁粒度与死锁
锁粒度:synchronized 的锁定范围由 “锁定对象” 决定,分为:- 对象锁:锁定实例对象(
this),修饰非静态方法或synchronized(this) { ... }代码块,仅影响该实例的线程访问。 - 类锁:锁定类对象(
XXX.class),修饰静态方法或synchronized(XXX.class) { ... }代码块,影响所有实例的线程访问。
package thread;public class LockGranularity {// 对象锁(锁定当前实例)public synchronized void instanceMethod() { ... }// 类锁(锁定 LockGranularity.class)public static synchronized void staticMethod() { ... }public void blockDemo() {Object lock = new Object();synchronized (lock) { // 锁定指定对象(局部锁,粒度更细)...}} }死锁及避免
- 死锁场景: 多线程循环等待对方释放锁,且永不释放自己的锁。
例如:线程 1持有锁 A等待锁 B,线程 2持有锁 B等待锁 A。 - 死锁避免策略:
- 固定锁顺序: 所有线程按相同顺序获取锁(如先获取编号小的锁)。
- 设置超时时间: 使用
ReentrantLock.tryLock(timeout),超时则释放已持有的锁。 - 减少锁持有时间: 仅在必要代码段加锁,避免长时间持有锁。
package thread;public class ThreadDemo01 {// 定义锁的顺序(A的优先级高于B)private static final Object LOCK_A = new Object();private static final Object LOCK_B = new Object();// 所有线程都先获取LOCK_A,再获取LOCK_Bpublic void method1() {synchronized (LOCK_A) {synchronized (LOCK_B) {// 业务逻辑}}}public void method2() {synchronized (LOCK_A) { // 遵循相同顺序,避免死锁synchronized (LOCK_B) {// 业务逻辑}}} }
- 对象锁:锁定实例对象(