 本文介绍了一个基于YOLOv12深度学习的机动车车牌检测系统。该系统采用PyQt5构建图形界面,支持图片和视频输入,能实时检测并分割车牌区域,同时提供结果保存功能。项目使用约1300张包含多角度、多颜色变化的车牌图像进行训练,提升模型鲁棒性。代码部分详细展示了界面设计、YOLO模型调用、图像处理等核心功能实现,并提供了可选的自定义训练脚本。该系统操作简便,检测效果良好,适合作为深度学习目标检测的入门实践项目。
本文介绍了一个基于YOLOv12深度学习的机动车车牌检测系统。该系统采用PyQt5构建图形界面,支持图片和视频输入,能实时检测并分割车牌区域,同时提供结果保存功能。项目使用约1300张包含多角度、多颜色变化的车牌图像进行训练,提升模型鲁棒性。代码部分详细展示了界面设计、YOLO模型调用、图像处理等核心功能实现,并提供了可选的自定义训练脚本。该系统操作简便,检测效果良好,适合作为深度学习目标检测的入门实践项目。
视频演示
基于yolo12进行深度学习的机动车车牌检测
前言
大家好,我是Coding茶水间。
今天分享一个基于YOLOv12的深度学习项目:机动车车牌检测算法。
这个项目使用YOLOv12模型进行车牌检测和分割,支持图片和视频输入,并通过PyQt5构建了一个简洁的图形界面。
整个系统可以实时检测车牌位置,并在界面上显示原始图像和分割后的车牌区域,还支持保存结果。
项目概述
核心技术
- YOLOv12模型:Ultralytics库提供的YOLO系列最新版本,用于目标检测。模型训练后可以准确识别机动车车牌,包括传统车牌和新能源车牌。
- PyQt5:用于构建图形用户界面(GUI),界面简洁,包括选择图片/视频、分割检测和保存结果的功能。
- OpenCV:处理图像和视频帧,进行显示和保存。
- 数据集:使用了约1300张训练图像,包括不同角度、颜色、透明度和尺度变化的车牌图片,以增强模型鲁棒性。数据集分为训练集、验证集和测试集,每张图像有对应的标注文件。
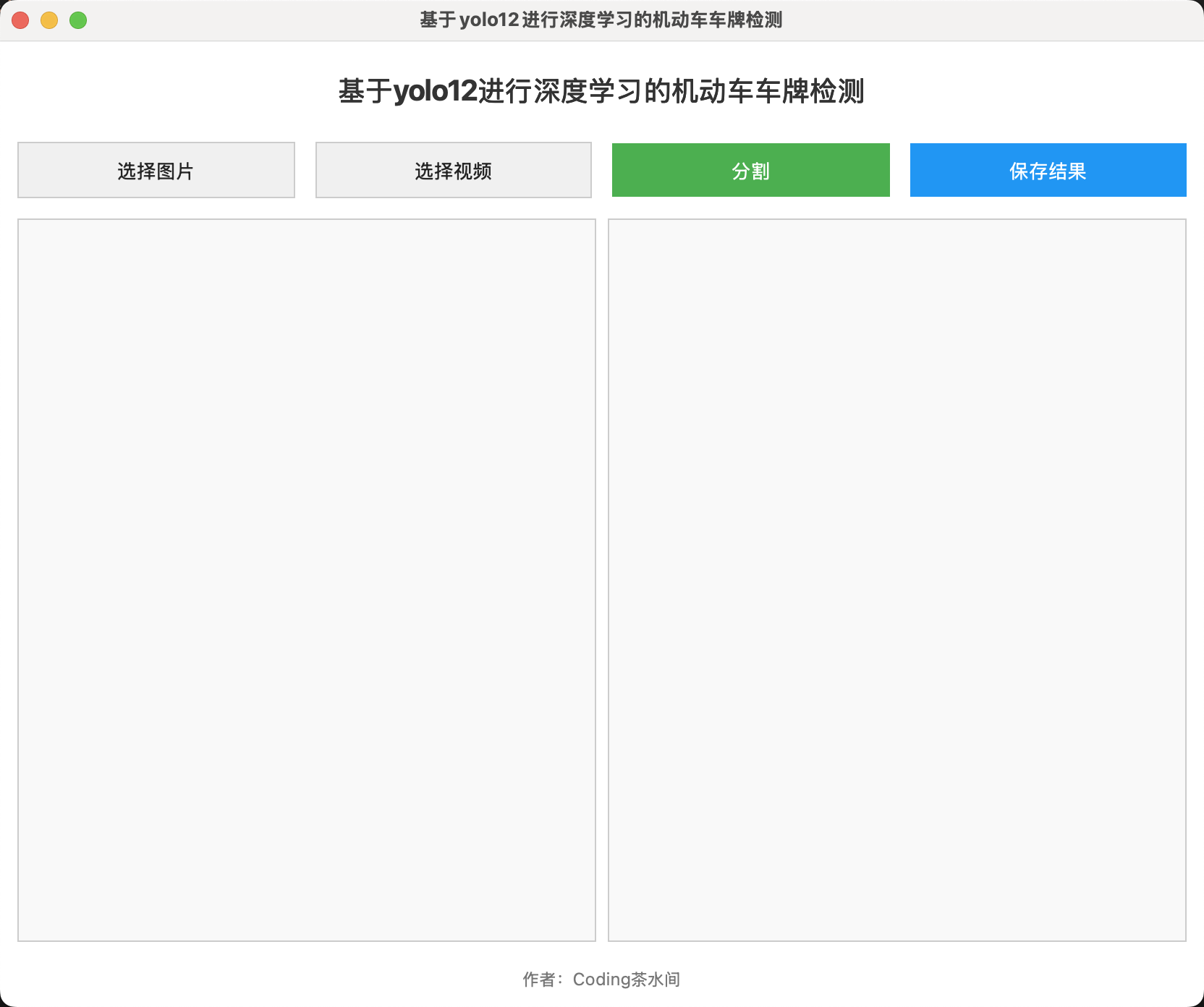
界面设计
界面布局如下:
- 顶部标题:显示项目名称。
- 按钮区域:四个按钮——“选择图片”、“选择视频”、“分割”、“保存结果”。
- 显示区域:左侧显示原始图像或视频帧,右侧显示分割后的车牌图像。
环境配置
运行本项目需要以下环境:
- Python 3.8+
- 安装依赖库:
text
pip install pyqt5 opencv-python ultralytics![]()
- 下载YOLOv12模型权重。
如果需要自己训练模型,还需准备车牌数据集(格式为YOLO标注:images和labels文件夹)。
代码实现
下面是完整的主程序代码(main.py)。代码使用PyQt5创建窗口,集成YOLO模型进行检测。
python
"""
版权所有 Coding茶水间。保留所有权利。
本代码仅限个人学习、研究之用,禁止用于任何商业用途。
未经许可,不得公开分发、复制、修改或用于盈利性项目。
"""
import sys
import cv2
from PyQt5.QtWidgets import QApplication, QMainWindow, QVBoxLayout, QHBoxLayout, QPushButton, QLabel, QFileDialog, QWidget, QMessageBox
from PyQt5.QtGui import QPixmap, QImage
from PyQt5.QtCore import Qt, QTimer
from ultralytics import YOLOclass MainWindow(QMainWindow):def __init__(self):super().__init__()self.setWindowTitle("基于yolo12进行深度学习的机动车车牌检测")self.setGeometry(100, 100, 800, 600)self.setStyleSheet("background-color: white;")# 主布局self.main_widget = QWidget()self.setCentralWidget(self.main_widget)self.main_layout = QVBoxLayout()self.main_widget.setLayout(self.main_layout)# 标题self.title_label = QLabel("基于yolo12进行深度学习的机动车车牌检测")self.title_label.setStyleSheet("font-size: 20px; font-weight: bold; color: #333; margin-bottom: 10px; margin-top: 10px;")self.title_label.setAlignment(Qt.AlignCenter)self.main_layout.addWidget(self.title_label)# 按钮区域self.button_layout = QHBoxLayout()self.main_layout.addLayout(self.button_layout)self.select_image_btn = QPushButton("选择图片")self.select_image_btn.setStyleSheet("QPushButton { background-color: #f0f0f0; border: 1px solid #ccc; padding: 10px; font-size: 14px; }")self.button_layout.addWidget(self.select_image_btn)self.select_video_btn = QPushButton("选择视频")self.select_video_btn.setStyleSheet("QPushButton { background-color: #f0f0f0; border: 1px solid #ccc; padding: 10px; font-size: 14px; }")self.button_layout.addWidget(self.select_video_btn)self.process_btn = QPushButton("分割")self.process_btn.setStyleSheet("QPushButton { background-color: #4CAF50; color: white; border: none; padding: 10px; font-size: 14px; }")self.button_layout.addWidget(self.process_btn)self.save_btn = QPushButton("保存结果")self.save_btn.setStyleSheet("QPushButton { background-color: #2196F3; color: white; border: none; padding: 10px; font-size: 14px; }")self.button_layout.addWidget(self.save_btn)# 展示区域(固定尺寸)self.display_layout = QHBoxLayout()self.main_layout.addLayout(self.display_layout)# 原始图像显示区域self.original_display = QLabel()self.original_display.setAlignment(Qt.AlignCenter)self.original_display.setStyleSheet("border: 1px solid #ccc; background-color: #f9f9f9;")self.original_display.setFixedSize(400, 500) # 固定展示区域尺寸self.display_layout.addWidget(self.original_display)# 分割后图像显示区域self.segmented_display = QLabel()self.segmented_display.setAlignment(Qt.AlignCenter)self.segmented_display.setStyleSheet("border: 1px solid #ccc; background-color: #f9f9f9;")self.segmented_display.setFixedSize(400, 500) # 固定展示区域尺寸self.display_layout.addWidget(self.segmented_display)# 作者信息(固定高度)self.author_label = QLabel("作者:Coding茶水间")self.author_label.setStyleSheet("font-size: 12px; color: #777; margin-top: 10px;")self.author_label.setAlignment(Qt.AlignCenter)self.main_layout.addWidget(self.author_label)# 连接信号self.select_image_btn.clicked.connect(self.select_image)self.select_video_btn.clicked.connect(self.select_video)self.process_btn.clicked.connect(self.process)self.save_btn.clicked.connect(self.save_result)# 创建定时器,控制帧率self.video_timer = QTimer(self)self.video_timer.timeout.connect(self.update_frame)self.isprocess = Falseself.isPrcVideo = Trueself.mode = YOLO("runs/weights/weights/best.pt") # 加载你的模型# 初始化存储处理后的帧数组self.processed_frames = []def select_image(self):file_path, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Image Files (*.png *.jpg *.jpeg)")if file_path:pixmap = QPixmap(file_path)self.im_path = file_pathself.original_display.setPixmap(pixmap.scaled(self.original_display.size(), Qt.KeepAspectRatio))self.isPrcVideo = Falsedef select_video(self):file_path, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Video Files (*.mp4 *.avi *.mov)")if file_path:# 清除原有显示内容if hasattr(self, 'video_capture'):self.video_capture.release()if hasattr(self, 'video_timer'):self.video_timer.stop()# 初始化 OpenCV 视频捕获self.video_capture = cv2.VideoCapture(file_path)# 检查视频是否成功打开if not self.video_capture.isOpened():QMessageBox.warning(self, "错误", "无法打开视频文件!")returnself.isprocess = Falseself.isPrcVideo = Trueself.video_timer.start(30) # 根据帧率设置定时器间隔def update_frame(self):# 读取下一帧ret, frame = self.video_capture.read()if ret:# 将 OpenCV 帧转换为 QImageif self.isprocess:ori_frame = frame.copy()results = self.mode.predict(frame)frame = results[0].plot()# 存储处理后的帧self.processed_frames.append(frame.copy()) # 提取车牌边界框并显示在右侧窗口if hasattr(results[0], 'boxes') and len(results[0].boxes) > 0:# 获取边界框坐标box = results[0].boxes.xyxy[0].cpu().numpy()x1, y1, x2, y2 = map(int, box)# 裁剪车牌区域cropped_plate = ori_frame[y1:y2, x1:x2]# # 转换为RGB格式cropped_plate = cv2.cvtColor(cropped_plate, cv2.COLOR_BGR2RGB)# 显示裁剪后的车牌h, w, ch = cropped_plate.shapebytes_per_line = ch * wq_image_plate = QImage(cropped_plate.data, w, h, bytes_per_line, QImage.Format_RGB888)self.plate_pixmap = QPixmap.fromImage(q_image_plate)self.segmented_display.setPixmap(self.plate_pixmap.scaled(self.segmented_display.width(), self.segmented_display.height(),Qt.KeepAspectRatio, Qt.SmoothTransformation))frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)h, w, ch = frame.shapebytes_per_line = ch * wq_image = QImage(frame.data, w, h, bytes_per_line, QImage.Format_RGB888)self.video_pixmap = QPixmap.fromImage(q_image)self.original_display.setPixmap(self.video_pixmap.scaled(self.original_display.width(), self.original_display.height(),Qt.KeepAspectRatio, Qt.SmoothTransformation))else:self.video_timer.stop()passdef process(self):if self.isPrcVideo:if hasattr(self, 'video_capture') and self.video_capture is not None:# 重置视频到第一帧self.video_capture.set(cv2.CAP_PROP_POS_FRAMES, 0)self.processed_frames = []self.isprocess = Trueif hasattr(self, 'video_timer'):self.video_timer.stop()self.video_timer.start(30)else:QMessageBox.warning(self, "错误", "请先选择视频!")else:if self.im_path:im0 = cv2.imread(self.im_path)results = self.mode.predict(im0)self.img_result = results[0].plot()# 显示原始图像img_result2 = cv2.cvtColor(self.img_result, cv2.COLOR_BGR2RGB)h, w, ch = img_result2.shapebytes_per_line = ch * wq_image = QImage(img_result2.data, w, h, bytes_per_line, QImage.Format_RGB888)self.video_pixmap = QPixmap.fromImage(q_image)self.original_display.setPixmap(self.video_pixmap.scaled(self.original_display.width(), self.original_display.height(),Qt.KeepAspectRatio, Qt.SmoothTransformation))# 提取车牌边界框并显示在右侧窗口if hasattr(results[0], 'boxes') and len(results[0].boxes) > 0:# 获取边界框坐标box = results[0].boxes.xyxy[0].cpu().numpy()x1, y1, x2, y2 = map(int, box)# 裁剪车牌区域cropped_plate = im0[y1:y2, x1:x2]#保存最后裁剪结果self.result_cropped = cropped_plate# 转换为RGB格式cropped_plate = cv2.cvtColor(cropped_plate, cv2.COLOR_BGR2RGB)# 显示裁剪后的车牌h, w, ch = cropped_plate.shapebytes_per_line = ch * wq_image_plate = QImage(cropped_plate.data, w, h, bytes_per_line, QImage.Format_RGB888)self.plate_pixmap = QPixmap.fromImage(q_image_plate)self.segmented_display.setPixmap(self.plate_pixmap.scaled(self.segmented_display.width(), self.segmented_display.height(),Qt.KeepAspectRatio, Qt.SmoothTransformation))else:# 如果没有检测到车牌,显示提示信息self.segmented_display.setText("未检测到车牌区域")else:QMessageBox.warning(self, "错误", "请先选择图片或视频!")def save_result(self):if self.isPrcVideo:if len(self.processed_frames) > 0:# 弹出保存视频对话框file_path, _ = QFileDialog.getSaveFileName(self, "保存视频", "", "Video Files (*.mp4 *.avi *.mov)")if file_path:# 获取第一帧的尺寸height, width, _ = self.processed_frames[0].shape# 初始化视频写入器fourcc = cv2.VideoWriter_fourcc(*'mp4v')video_writer = cv2.VideoWriter(file_path, fourcc, 30.0, (width, height))# 写入所有帧for frame in self.processed_frames:video_writer.write(frame)# 释放资源video_writer.release()QMessageBox.information(self, "成功", "视频保存成功!")else:QMessageBox.warning(self, "错误", "请先处理视频!")else:if self.im_path:file_path, _ = QFileDialog.getSaveFileName(self, "保存图片", "", "Image Files (*.png *.jpg *.jpeg)")if file_path:cv2.imwrite(file_path, self.result_cropped)QMessageBox.information(self, "成功", "图片保存成功!")else:QMessageBox.warning(self, "错误", "请先选择图片或视频!")if __name__ == "__main__":app = QApplication(sys.argv)window = MainWindow()window.show()sys.exit(app.exec_())代码关键部分解释
- 初始化界面:在__init__中设置布局、按钮和显示区域。加载YOLO模型:self.mode = YOLO("runs/weights/weights/best.pt")。
- 选择图片/视频:使用QFileDialog打开文件,选择后显示在左侧。
- 分割处理:点击“分割”按钮,对于图片,直接使用YOLO预测,绘制边界框并裁剪车牌显示在右侧。对于视频,使用定时器逐帧处理,存储处理帧。
- 保存结果:对于图片,保存裁剪车牌;对于视频,保存处理后的视频文件。
- 视频处理:使用QTimer控制帧率(30ms间隔),在update_frame中预测并更新显示。
使用方法
- 运行代码:python main.py。
- 图片检测:
- 点击“选择图片”,选一张含车牌的图像。
- 点击“分割”,左侧显示标注后的图像,右侧显示裁剪车牌(带置信度)。
- 点击“保存结果”,保存裁剪车牌。
- 视频检测:
- 点击“选择视频”,选一个视频文件(首次会播放原视频)。
- 点击“分割”,处理视频,实时标注车牌并显示裁剪区域。
- 点击“保存结果”,保存处理后的视频。
训练模型(可选)
如果想自己训练:
- 准备数据集:images文件夹放图片,labels文件夹放YOLO格式标注(.txt文件,每行:class x_center y_center width height)。
- 我们这里也提供了训练脚本:
# -*- coding: utf-8 -*- """ 该脚本用于执行YOLO模型的训练。它会自动处理以下任务: 1. 动态修改数据集配置文件 (data.yaml),将相对路径更新为绝对路径,以确保训练时能正确找到数据。 2. 从 'pretrained' 文件夹加载指定的预训练模型。 3. 使用预设的参数(如epochs, imgsz, batch)启动训练过程。要开始训练,只需直接运行此脚本。 """ import os import yaml from pathlib import Path from ultralytics import YOLOdef main():"""主训练函数。该函数负责执行YOLO模型的训练流程,包括:1. 配置预训练模型。2. 动态修改数据集的YAML配置文件,确保路径为绝对路径。3. 加载预训练模型。4. 使用指定参数开始训练。"""# --- 1. 配置模型和路径 ---# 要训练的模型列表models_to_train = [{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}]# 获取当前工作目录的绝对路径,以避免相对路径带来的问题current_dir = os.path.abspath(os.getcwd())# --- 2. 动态配置数据集YAML文件 ---# 构建数据集yaml文件的绝对路径data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml')# 读取原始yaml文件内容with open(data_yaml_path, 'r', encoding='utf-8') as f:data_config = yaml.safe_load(f)# 将yaml文件中的 'path' 字段修改为数据集目录的绝对路径# 这是为了确保ultralytics库能正确定位到训练、验证和测试集data_config['path'] = os.path.join(current_dir, 'train_data')# 将修改后的配置写回yaml文件with open(data_yaml_path, 'w', encoding='utf-8') as f:yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)# --- 3. 循环训练每个模型 ---for model_info in models_to_train:model_name = model_info['name']train_name = model_info['train_name']print(f"\n{'='*60}")print(f"开始训练模型: {model_name}")print(f"训练名称: {train_name}")print(f"{'='*60}")# 构建预训练模型的完整路径pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)if not os.path.exists(pretrained_model_path):print(f"警告: 预训练模型文件不存在: {pretrained_model_path}")print(f"跳过模型 {model_name} 的训练")continuetry:# 加载指定的预训练模型model = YOLO(pretrained_model_path)# --- 4. 开始训练 ---print(f"开始训练 {model_name}...")# 调用train方法开始训练model.train(data=data_yaml_path, # 数据集配置文件epochs=100, # 训练轮次imgsz=640, # 输入图像尺寸batch=16, # 每批次的图像数量name=train_name, # 模型名称)print(f"{model_name} 训练完成!")except Exception as e:print(f"训练 {model_name} 时出现错误: {str(e)}")print(f"跳过模型 {model_name},继续训练下一个模型")continueprint(f"\n{'='*60}")print("所有模型训练完成!")print(f"{'='*60}")if __name__ == "__main__":# 当该脚本被直接执行时,调用main函数main()![]()
- 参数:epochs(训练轮次)、batch(批次大小)等。
- 训练后,权重文件在runs/detect/train/weights/best.pt。
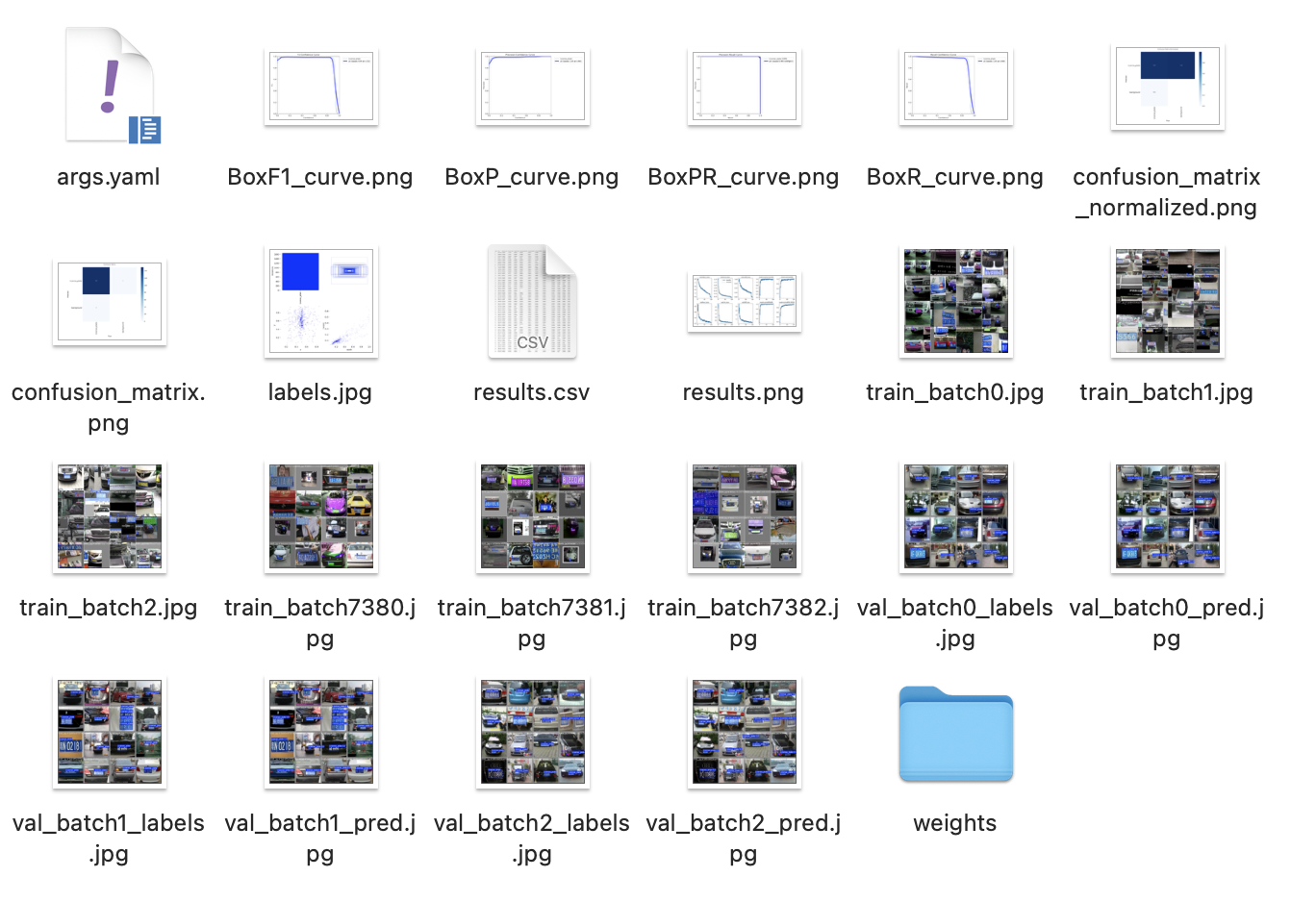
训练结果示例:F1分数、召回率等指标可在runs文件夹查看。
效果展示
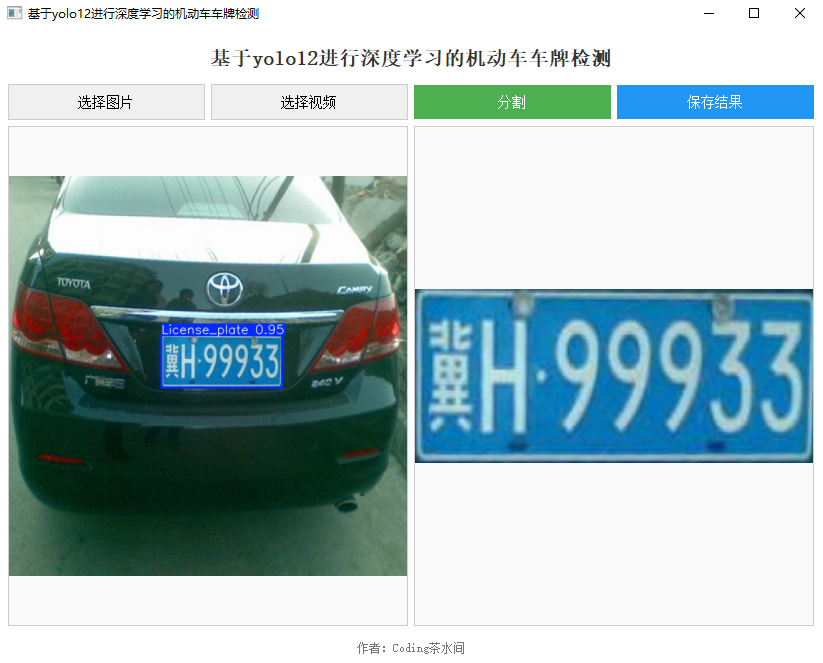
- 图片效果:输入一张车牌图像,输出蓝色框标注 + 置信度 + 单独车牌图像。
- 视频效果:实时检测前景明显的车牌,支持新能源车牌。
- 数据集示例:1300+张训练图像,包含多角度、多颜色变化。
结语
这个基于YOLOv12的车牌检测项目简单高效,适合入门深度学习目标检测。如果你有自己的车牌数据集,可以用这套代码训练和验证。欢迎交流改进思路!