- 1.zookeeper下载
- 2.zookeeper安装与使用
- 3.zookeeper启动
- 4.zookeeper是什么?为什么要用它?为什么不用Hbase自带的?
1.zookeeper下载
版本无特别要求,一般最新稳定版即可。
这里给出3.8.4的下载链接。(点击即可直接下载)
zookeeper官网:https://zookeeper.apache.org/
2.zookeeper安装与使用
(0)!!! 在开始之前,确保你所有机器的用户名相同,即hadoop@master、hadoop@salve01、hadoop@salve02 等,要确保@ 前的用户名相同,避免后续不必要的错误
| 准备工作,所有机器上都要有 |
|---|
| 配置好hosts文件 |
| 安装JAVA(尽量JDK8) |
| 安装SSH |
| 所有机器上可以互相ping通 |
| master可以免密连接slave节点 |
| 用户名都相同 |
(1)在自己电脑下载好zookeeper之后,粘贴到虚拟机的Downloads里,鼠标右键,点Paste即可粘贴。
注:打开左边第二个图标,打开之后点Downloads,再粘贴
(也可以复制链接到虚拟机的浏览器,直接在虚拟机下载,省的再复制粘贴)

(2)解压文件、重命名、授权
sudo tar -zxvf ~/Downloads/apache-zookeeper-3.8.4-bin.tar.gz -C /usr/local
cd /usr/local
sudo mv ./apache-zookeeper-3.8.4-bin ./zookeeper //如果你的不是3.8.4,根据实际修改
sudo chown -R hadoop ./zookeeper
(3)配置环境变量
sudo vim ~/.bashrc
进入文件后,按上下方向键,翻到最后,插入下面语句(Ctrl+Shift+v 粘贴)
#Zookeeper
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
之后执行source ~/.bashrc 命令刷新环境变量,使配置生效。
(4)新建data和logs目录(data目录用来存放数据库快照,logs目录用来存放日志文件)
cd /usr/local/zookeeper
mkdir logs
mkdir data
注:logs目录中的.out文件为运行日志,可以查看报错信息
(5)配置文件zoo.cfg与myid
注:因为zookeeper使用的配置文件为
zoo.cfg,但是自带的是zoo_sample.cfg模板文件,因此可以使用mv命令重命名,或者直接vim编写新文件。

cd /usr/local/zookeeper/conf/
vim zoo.cfg
粘贴下列内容,之后根据自己的实际机器,修改最后几行的内容
注:最后三行, = 后面的master、slave01名字等与hosts文件中配置的相同,即Hadoop@slave01,@后面的slave01.
# The number of milliseconds of each tick
# zookeeper时间配置中的基本单位 (毫秒)
# Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,单位为毫秒
tickTime=2000 # The number of ticks that the initial synchronization phase can take
# 允许follower初始化连接到leader最⼤时⻓,它表示tickTime时间倍数
# 表示允许从服务器连接到 leader 并完成数据同步的时间,总的时间长度就是 initLimit * tickTime 秒
initLimit=10# The number of ticks that can pass between sending a request and getting an acknowledgement
# 允许follower与leader数据同步最⼤时⻓,它表示tickTime时间倍数
# 配置 Leader 与 Follower 之间发送消息、请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 syncLimit * tickTime 秒
syncLimit=5# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just example sakes.
#zookeper 数据存储⽬录及⽇志保存⽬录(如果没有指明dataLogDir,则⽇志也保存在这个⽂件中)
# Zookeeper 保存数据的数据库快照的位置
dataDir=/usr/local/zookeeper/data# 事务日志路径,若没提供的话则用 dataDir
dataLogDir=/usr/local/zookeeper/logs# the port at which the clients will connect
# Zookeeper 服务器监听的端口,以接受客户端的访问请求
#对客户端提供的端⼝号
clientPort=2181# the maximum number of client connections.
# increase this if you need to handle more clients
# 限制连接到 ZK 上的客户端数量,并且限制并发连接数量,值为 0 表示不做任何限制
#单个客户端与zookeeper最⼤并发连接数
#maxClientCnxns=60# Be sure to read the maintenance section of the administrator guide before turning on autopurge.
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance# The number of snapshots to retain in dataDir
# 自动清理日志,该参数设置保留多少个快照文件和对应的事务日志文件,默认为 3,如果小于 3 则自动调整为 3
# 保存的数据快照数量,之外的将会被清除
#autopurge.snapRetainCount=3# Purge task interval in hours
# Set to "0" to disable auto purge feature
#自动触发清除任务时间间隔,⼩时为单位。默认为0,表示不⾃动清除。
#autopurge.purgeInterval=1# server.n n是一个数字,表示这个是第几号服务器,“=”后面可跟主机地址或者IP地址,2888为集群中从服务器(follower)连接到主服务器(leader)的端口,为主服务器(leader)使用;3888为进行选举(leader)的时使用的端口
server.1=master:2888:3888
server.2=slave01:2888:3888
server.3=slave02:2888:3888🚨再次提醒!!!集群部署,需要自行配置最后几行的server,哪个机器需要zookeeper服务,就填哪个机器名。
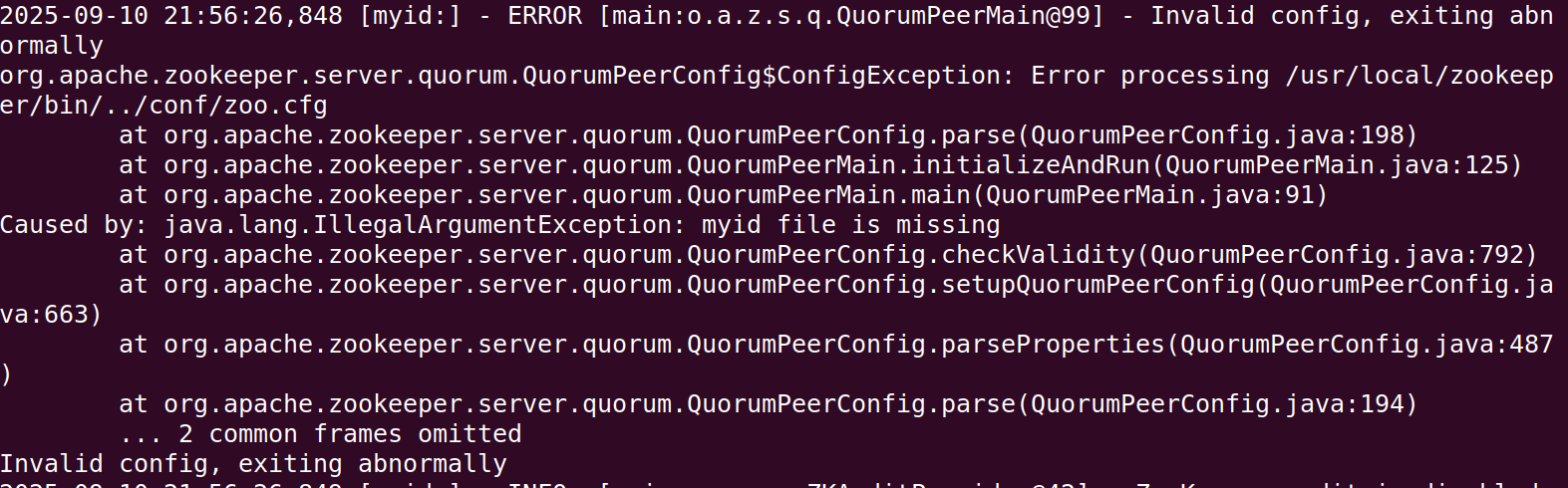
注1:配置文件时,注释单独一行写,不能写在参数后面,否则在解析时,会把注释内容也识别为参数,导致报错,日志内容如下

注2:配置文件时,
dataDir和dataLogDir的配置路径,不要用环境变量来代替绝对路径,例如dataDir=$ZOOKEEPER_HOME/data是错误的。 ZooKeeper 的配置文件(zoo.cfg)本身不支持解析环境变量(如$ZOOKEEPER_HOME),会把它当作普通字符串处理,导致无法正确识别路径。导致报错,日志内容如下
(6)压缩文件,并发送到其他机器上
cd /usr/local
tar -zcvf ~/zookeeper.tar.gz ./zookeeper/
scp ~/zookeeper.tar.gz hadoop@slave01:/home/hadoop/
scp ~/zookeeper.tar.gz hadoop@slave02:/home/hadoop/
(7)在slave01和slave02进行解压缩,并配置环境变量
sudo tar -zxvf ~/zookeeper.tar.gz -C /usr/local/
sudo vim ~/.bashrc
粘贴下面的环境变量
#Zookeeper
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
之后执行source ~/.bashrc 命令刷新环境变量,使配置生效。
(8)配置myid文件(所有机器上都要做,包括master、slave)
vim /usr/local/zookeeper/data/myid
myid填写数字,就是zoo.cfg文件中填写的主机名前的数字。只填一个数字就行。


(9)常用命令
zkServer.sh start //启动zookeeper
zkServer.sh stop //停止zookeeper
zkServer.sh status //查看zookeeper运行状态(至少启动两个节点再去查看,不然选举失败,状态也是不正常)
zkServer.sh version //查看zookeeper版本
zkServer.sh restart //重启zookeeperzookeeper客户端:
zkCli.sh //进入zookeeper客户端
quit //退出客户端
deleteall //删除文件夹及其子文件夹(例:deleteall /hbase)
3.zookeeper启动
在每个机器上都单独输入 zkServer.sh start ,来启动zookeeper。
至少启动两个,然后输入zkServer.sh status 查看启动状态。
注:Hmaster与leader不在同一机器上,是正常现象。实际生产环境中,甚至会刻意将 HMaster 和 ZooKeeper Leader 部署在不同机器。
- 避免 “单点故障放大”
如果二者在同一台机器,一旦该机器宕机,会同时导致 HBase 失去主管理节点、ZooKeeper 集群失去 Leader(需重新选举),双重故障会大幅延长集群恢复时间;分开部署则只会影响单一组件,风险更可控。 - 减少资源竞争
HMaster 需处理 HBase 的 Region 分配、元数据更新等计算;ZooKeeper Leader 需处理大量分布式锁请求(如 HBase 依赖 ZooKeeper 实现 Master 选举、RegionServer 心跳)。二者分开部署可避免 CPU、内存、网络资源的相互抢占,提升各自性能。 - 符合 “组件解耦” 设计
分布式架构的核心原则是 “组件解耦”,HBase 本身就是依赖 ZooKeeper 提供的分布式协调能力(而非依赖其物理节点),只要 HMaster 能通过网络正常连接 ZooKeeper 集群(配置hbase.zookeeper.quorum指向 ZooKeeper 集群地址),就无需关心 ZooKeeper Leader 具体在哪台机器。
示例如下
master节点

slave01节点

slave02节点

4.zookeeper是什么?为什么要用它?为什么不用Hbase自带的?
(1)ZooKeeper 是一款开源的分布式协调服务,核心作用是帮分布式系统(由多个独立服务组成的系统)解决配置同步、节点管理、分布式锁等协调问题,让系统运行更稳定、有序。
(2)
- 分布式数据库 HBase 用它管理集群节点 ——ZooKeeper 实时监控 HBase 的主节点(Master)和从节点(RegionServer)状态,若主节点故障,能快速从备用节点中选新主节点,避免数据库服务中断;
- 电商秒杀场景中,多个服务同时抢库存易超卖,此时用 ZooKeeper 实现 “分布式锁”—— 同一时间只允许一个服务操作库存,确保库存数据准确。
可以类似于:学校运动会的总调度员”:
学校运动会有多个项目(对应分布式系统里的多个服务),每个项目需要知道比赛时间、场地安排(对应服务需要的配置信息),还要避免不同项目抢同一跑道(对应服务抢同一资源),且得实时掌握每个项目是否正常进行(对应监控服务节点状态)。
这时总调度员(ZooKeeper)的作用就是:提前把统一的赛程表(配置)发给所有项目组,协调好各项目的场地使用(分布式锁),一旦某个项目出问题(比如裁判缺席),立刻通知替补人员顶上(节点故障切换),确保整个运动会(分布式系统)不混乱、不中断。
(3)HBase 自带 ZooKeeper与独立zookeeper的区别
简单来说就是单独的zookeeper更加灵活、高效、安全
| 对比维度 | HBase 自带 ZooKeeper | 单独的 ZooKeeper |
|---|---|---|
| 部署与维护成本 | 低:无需单独下载部署,依赖 HBase 脚本启动 / 停止,配置简化(仅需在 HBase 配置文件中指定 ZooKeeper 参数)。 | 高:需单独下载、配置(如zoo.cfg)、启动,需独立监控和运维,新增组件学习成本。 |
| 独立性与生命周期 | 弱绑定:ZooKeeper 随 HBase 启动而启动、随 HBase 停止而停止,无法单独重启或升级;HBase 故障可能直接影响 ZooKeeper。 | 完全独立:ZooKeeper 可单独启动、停止、升级,生命周期与 HBase 无关;HBase 重启 / 故障不影响 ZooKeeper 运行。 |
| 扩展性 | 有限:仅支持单机模式或小规模伪集群(默认不支持 ZooKeeper 集群,需手动修改配置但兼容性差),无法满足大规模集群需求。 | 灵活:支持单机、伪集群、完全分布式集群(3 + 节点,满足高可用),可根据业务规模扩容 ZooKeeper 节点。 |
| 稳定性与可靠性 | 较低:ZooKeeper 与 HBase 共享资源(CPU、内存、磁盘),HBase 高负载时可能导致 ZooKeeper 响应缓慢;无独立监控,故障排查困难。 | 较高:资源隔离(独立服务器 / 容器),避免 HBase 负载影响;可单独配置监控(如 Zabbix、Prometheus),故障定位更高效。 |
| 多组件兼容性 | 差:仅为 HBase 服务,无法被其他分布式组件(如 Kafka、Spark)复用,导致集群中存在多个 “孤立” ZooKeeper 实例,资源浪费且管理复杂。 | 好:可作为 “全局协调服务”,为 HBase、Hadoop、Kafka 等多个组件提供统一协调,减少资源冗余,简化集群管理。 |
| 版本与升级灵活性 | 低:ZooKeeper 版本与 HBase 绑定(如 HBase 2.5.0 默认自带 ZooKeeper 3.5.9),升级 ZooKeeper 需先升级 HBase,无法单独适配高版本 ZooKeeper 的新特性(如动态配置)。 | 高:ZooKeeper 版本可独立选择(需与 HBase 兼容,如 HBase 2.x 支持 ZooKeeper 3.4.x/3.5.x),可单独升级 ZooKeeper,无需依赖 HBase 版本迭代。 |
| 适用场景 | 小规模测试、开发环境、单机伪集群(追求快速搭建,无需高可用)。 | 生产环境、大规模 HBase 集群、多组件协同的分布式集群(需高可用、稳定性和扩展性)。 |