大家好,我是Java烘焙师。如何更新缓存和DB、做到性能和一致性的取舍,是一个很常见的话题。下面结合笔者的经验和思考,系统性地总结一下缓存更新模式,讲透讲明白。
1、旁路缓存(cache-aside)
实现方案
- 查询:先查缓存,查不到缓存时再查DB,并把DB内容写入缓存、设置合适的过期时间
- 更新:先更新DB,再删缓存;做到极致则需引入延迟双删机制
之所以不是先删缓存、再更新DB,是因为在这两个操作间隙,如果有其它查询请求,则会把DB旧值写到缓存。
之所以不是先更新DB、再更新缓存,是因为写DB和缓存无法保证一致性,并且可能因为2个并发写的时序问题而把旧数据写到缓存。
之所以延迟双删,是因为在极端情况下,读线程会把DB旧值写到缓存。需要同时满足几个条件:缓存已过期,并且读线程先查询到DB旧值,然后写线程更新DB、删除缓存之后,读线程才把DB旧值写入缓存。如下图所示。

因此第一次删除缓存后,延迟一小段时间再删除,就能保证缓存和DB的最终一致。下图是引入了延迟双删机制的cache-aside架构图。
cache-aside查询场景:
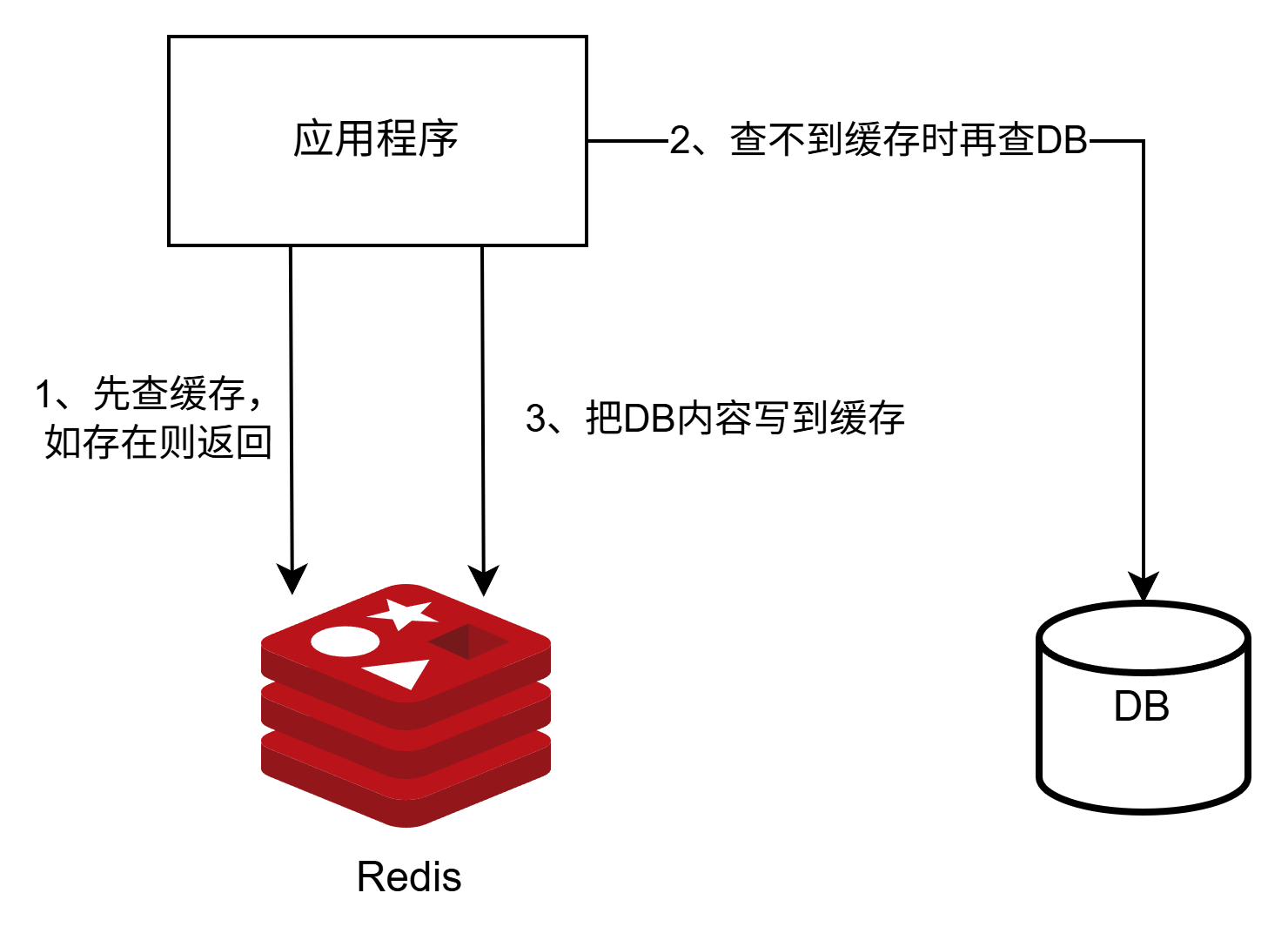
cache-aside更新场景:

适用场景
- 绝大部分场景
优点
- 当数据量大时,可按需加载到缓存
缺点
- 如果存在热点key,在失效后,会有大量查询请求穿透缓存,直接打到DB,造成DB CPU使用率飙升
旁路缓存优化:主动预刷新缓存
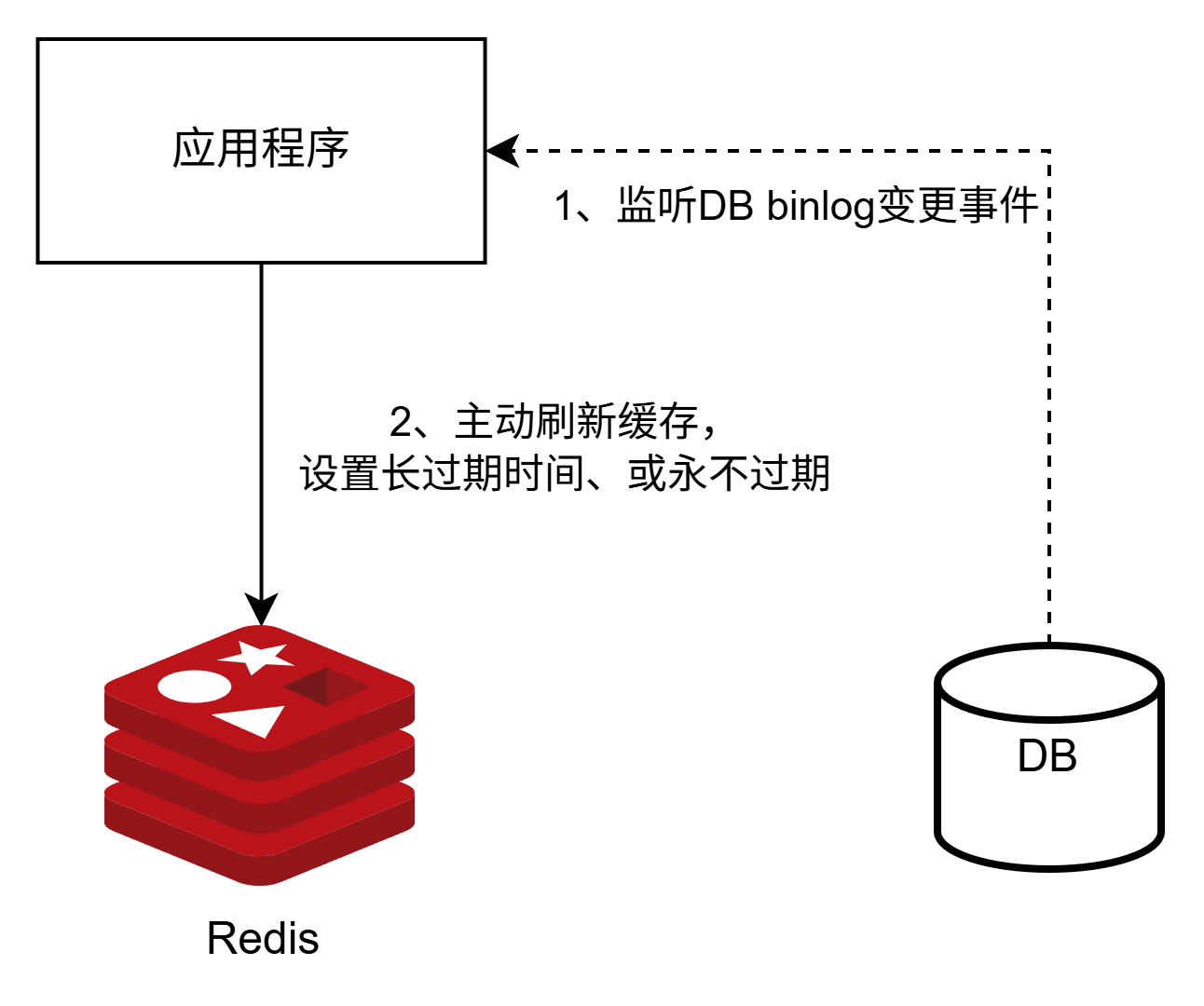
为了解决热点缓存失效问题,可考虑设置TTL为较长时间,并主动预刷新热点key。
根据数据量大小区分:
- 如果数据量较大,则针对热点key,配置白名单。做得更好的话,是自动发现、并更新热点key白名单。
- 如果数据量较小,则可以考虑全部加载到缓存中,永不过期。如:一些全局的配置数据。
根据触发刷新缓存的时机区分:
- 定时拉取:程序自行实现,根据热点key白名单,定时查DB、并更新缓存
- 异构数据:监听mysql变更,DB变化时触发更新缓存
更推荐异构数据的方式,好处是:缓存更新及时,并且做成通用功能之后、无需额外开发。
2、异步写回DB模式(write-back)
实现方案
- 查询:只查询缓存
- 更新:先写入缓存,然后发消息、消息链路异步写入DB,或定时任务兜底写入DB

适用场景
查询qps很高、极其热点的数据,优先保证性能。
场景举例:
- 计数统计:有的页面会滚动刷新访问人次、使用人次
- 爆品库存扣减:redis扣减库存,然后异步落库,而不是常规地操作DB扣减库存
优点
- 支撑高qps、热点场景
缺点
- 短期内会出现缓存和DB数据不一致情况,需要消息触发、或兜底定时任务写回DB
3、read/write through模式
实现方案
不论是cache-aside、还是write-back模式,都需要应用程序自己来控制读写缓存、DB。而read/write through模式是把控制权交给底层存储服务。
存储服务维护缓存、持久化数据,应用程序无需感知,这也是优点了。不过完全依赖于存储服务是否靠谱,实际业务场景并不常见。
4、持续优化
搭积木方式,根据实际情况做优化。
多级缓存:进一步降低缓存、DB的热点风险
- 增加本地缓存,如caffeine
- 或增加DB以外的异构数据,当查不到缓存时再查异构数据、查不到异构数据时最终查DB。异构数据可以是HBase、ES等
通过逻辑层面来实现生效、过期的效果,而非系统层面
- 架构设计必须适配业务,比如通过逻辑过期解决不一致、缓存集中过期的问题,如缓存记录业务开始时间、结束时间,TTL可设置稍长些、并且通过增加随机时长来避免key集中失效。这样就能实现到时间点就变的场景,如活动开始、结束。
强一致场景,只查DB、已DB数据为准
- 特别地,对一致性有强要求的场景:只查DB、不查缓存,以DB数据为准。如下单时查询DB里的价格,避免缓存数据非最新。
更进一步,考虑使用rocksdb,代替redis
- rocksdb相当于是自带缓存的持久化数据库,值得专门写一篇文章介绍原理、区别,后面有空整理。
结论
- 绝大部分场景,使用旁路缓存模式(cache-aside)。更进一步,对部分热点key做主动预刷新,可监听DB变更、或定时刷新。
- 高qps、极热key场景,使用异步写回DB模式(write-back),优先保证性能,可接受短时间内DB与缓存不一致。
- 持续优化:
- 增加多级缓存、异构数据,来降低缓存、DB的热点风险
- 通过逻辑层面来实现生效、过期的效果
- 强一致场景,只查DB、已DB数据为准
延伸阅读:笔者之前写的缓存相关文章,欢迎围观。
- 架构师必备:本地缓存原理和应用
- Spring cache源码分析