全文链接:https://tecdat.cn/?p=43860
原文出处:拓端抖音号@拓端tecdat
分析师:Jiaxin Yao

在电商行业快速发展的背景下,订单数据与商品销售数据已成为企业优化运营、提升效益的核心资产。通过对这些数据的深度分析,不仅能挖掘销售趋势、地区消费差异,还能精准识别客户价值,为业务决策提供数据支撑。作为数据科学家,我们在过往的电商客户咨询项目中发现,许多企业虽积累了大量数据,但缺乏系统的分析方法,难以将数据转化为实际运营策略——这正是本次分析报告的核心出发点。
一、引言
本报告改编自我们为某电商客户完成的运营优化咨询项目,聚焦两类核心数据:天猫订单数据(Tmall Order Data)与日化商品销售数据(Daily Chemical Products Sales Data)。分析过程中,我们采用Python工具(Pandas用于数据处理、Pyecharts用于可视化),通过数据预处理(去重、补空、格式标准化)、描述性统计分析、时间序列分析、地区分布分析,以及RFM(Recency-Frequency-Monetary)客户价值模型,逐步拆解业务问题:先明确天猫订单的成交规律与时间/地区特征,再挖掘日化商品的销售趋势与品类差异,最终量化客户价值并提出运营建议。
值得注意的是,天猫订单与日化商品分析完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。以下为本次分析的整体脉络流程图:
二、天猫订单数据分析
天猫订单数据(tmall_order_report.csv)包含订单编号、总金额、买家实际支付金额、收货地址、订单创建时间、订单付款时间、退款金额等字段,核心目标是分析成交情况、地区分布与时间趋势,为运营策略提供方向。
1. 数据读取与初步探查
首先通过Python的Pandas库读取数据,初步了解数据结构与质量,为后续预处理奠定基础。关键代码如下(已修改变量名并翻译注释):
-
import pandas as pd
-
# 读取天猫订单数据文件,指定本地文件路径
-
tmall_order_data = pd.read_csv("D:\\OrderFromTmall\\tmall_order_report.csv")
-
# 查看数据前5行,初步探查字段结构(注:退款金额字段指客户退货后返还的金额)
-
tmall_order_data.head()
-
# 查看数据基本信息(字段类型、非空值数量),判断是否存在数据缺失或类型异常
-
tmall_order_data.info()
通过head()可观察到各字段的具体格式,如“订单创建时间”为字符串格式(后续需转为datetime);通过info()可确认是否存在空值(如订单付款时间可能为空,代表未付款订单)。
2. 数据预处理
数据预处理是保证分析准确性的关键,主要包括列名清洗、去重、空值检查与地址标准化,具体操作如下:
-
# 1. 去除列名前后的空格(避免因列名冗余导致的字段调用错误)
-
tmall_order_data.columns = tmall_order_data.columns.str.strip()
-
print("清洗后的列名:", tmall_order_data.columns.tolist())
-
# 2. 统计重复数据数量(重复订单可能由数据录入错误导致,需后续处理)
-
duplicate_count = tmall_order_data.duplicated().sum()
-
print(f"重复数据的数量: {duplicate_count}")
-
# 3. 统计各字段空值数量(空值可能影响指标计算,如未付款订单的付款时间为空)
-
null_count = tmall_order_data.isnull().sum()
-
print("各字段空值数量:\n", null_count)
-
# 4. 地址标准化:去除省份名称中的冗余词汇(如“自治区”“省”),统一地址格式
-
address_clean_dict = {
-
'自治区': '',
-
'维吾尔': '',
-
'回族': '',
-
'壮族': '',
-
'省': ''
-
}
-
for key, value in address_clean_dict.items():
-
tmall_order_data['收货地址'] = tmall_order_data['收货地址'].str.replace(key, value)
-
# 查看标准化后的唯一收货地址,确认格式统一(如“新疆维吾尔自治区”转为“新疆”)
-
print("标准化后的收货地址:", tmall_order_data['收货地址'].unique())
预处理后,数据格式统一、无冗余重复,可进入可视化分析阶段。
3. 数据可视化与业务分析
3.1 整体成交情况统计
通过表格展示核心成交指标,包括总订单数、已完成订单数、退款金额等,并计算成交率(已完成订单数/总订单数)与退货率(退款订单数/已完成订单数),直观反映订单质量:
-
from pyecharts import options as opts
-
from pyecharts.components import Table
-
from pyecharts.options import ComponentTitleOpts
-
# 计算天猫订单核心成交指标
-
tmall_deal_result = {}
-
tmall_deal_result['总订单数'] = tmall_order_data['订单编号'].count() # 所有订单总数
-
tmall_deal_result['已完成订单数'] = tmall_order_data['订单编号'][tmall_order_data['订单付款时间'].notnull()].count() # 付款成功的订单
-
tmall_deal_result['未付款订单数'] = tmall_order_data['订单编号'][tmall_order_data['订单付款时间'].isnull()].count() # 未付款订单
-
tmall_deal_result['退款订单数'] = tmall_order_data['订单编号'][tmall_order_data['退款金额'] > 0].count() # 产生退货的订单
-
tmall_deal_result['总订单金额'] = tmall_order_data['总金额'][tmall_order_data['订单付款时间'].notnull()].sum() # 已完成订单总金额
-
tmall_deal_result['总退款金额'] = tmall_order_data['退款金额'][tmall_order_data['订单付款时间'].notnull()].sum() # 已完成订单总退款
-
tmall_deal_result['总实际收入金额'] = tmall_order_data['买家实际支付金额'][tmall_order_data['订单付款时间'].notnull()].sum() # 实际收入(扣除退款前)
-
# 创建表格展示指标
-
tmall_deal_table = Table()
-
headers = ['总订单数', '总订单金额', '已完成订单数', '总实际收入金额', '退款订单数', '总退款金额', '成交率', '退货率']
-
rows = [
-
[
-
tmall_deal_result['总订单数'],
-
f"{tmall_deal_result['总订单金额']/10000:.2f} 万",
-
tmall_deal_result['已完成订单数'],
-
f"{tmall_deal_result['总实际收入金额']/10000:.2f} 万",
-
tmall_deal_result['退款订单数'],
-
f"{tmall_deal_result['总退款金额']/10000:.2f} 万",
-
f"{tmall_deal_result['已完成订单数']/tmall_deal_result['总订单数']:.2%}",
-
f"{tmall_deal_result['退款订单数']/tmall_deal_result['已完成订单数']:.2%}",
-
]
-
]
-
tmall_deal_table.add(headers, rows)
-
tmall_deal_table.set_global_opts(title_opts=ComponentTitleOpts(title='天猫订单整体成交情况'))
-
tmall_deal_table.render_notebook()
该表格可帮助企业快速掌握订单整体质量,如退货率过高时需排查商品质量或物流问题。
3.2 地区成交情况分析
通过地图与柱状图结合,展示各地区订单分布,挖掘地区消费差异:
-
from pyecharts.charts import Map, Bar
-
# 按收货地址分组,统计已完成订单的数量
-
tmall_area_order = tmall_order_data[tmall_order_data['订单付款时间'].notnull()].groupby('收货地址').agg({'订单编号':'count'})
-
# 转换为地图所需格式(地址+订单数)
-
area_data = [list(i) for i in zip(tmall_area_order.index, tmall_area_order['订单编号'])]
-
# 1. 绘制全国地区分布地图
-
area_map = Map()
-
area_map.add('订单量', area_data, maptype='china', is_map_symbol_show=False) # 不显示地图标记点
-
area_map.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 显示省份名称
-
area_map.set_global_opts(
-
visualmap_opts=opts.VisualMapOpts(min_=0, max_=10000), # 颜色深浅对应订单量范围
-
title_opts=opts.TitleOpts(title='天猫订单地区分布'),
-
legend_opts=opts.LegendOpts(is_show=False) # 隐藏图例(单系列无需图例)
-
)
-
area_map.render('天猫订单地区分布.html')
-
# 2. 绘制柱状图展示各地区具体订单数
-
x_data = tmall_area_order.index.tolist() # 收货地址
-
y_data = tmall_area_order['订单编号'].tolist() # 订单数量
-
area_bar = Bar()
-
area_bar.add_xaxis(x_data)
-
area_bar.add_yaxis("订单数量", y_data)
-
area_bar.set_global_opts(
-
title_opts=opts.TitleOpts(title="不同收货地址的订单数量"),
-
xaxis_opts=opts.AxisOpts(name="收货地址", axislabel_opts=opts.LabelOpts(rotate=45)), # 旋转X轴标签避免重叠
-
yaxis_opts=opts.AxisOpts(name="订单数量"),
-
datazoom_opts=opts.DataZoomOpts() # 添加缩放功能,便于查看多地区数据
-
)
-
area_bar.render('天猫订单数量柱状图.html')
对应的可视化结果如下: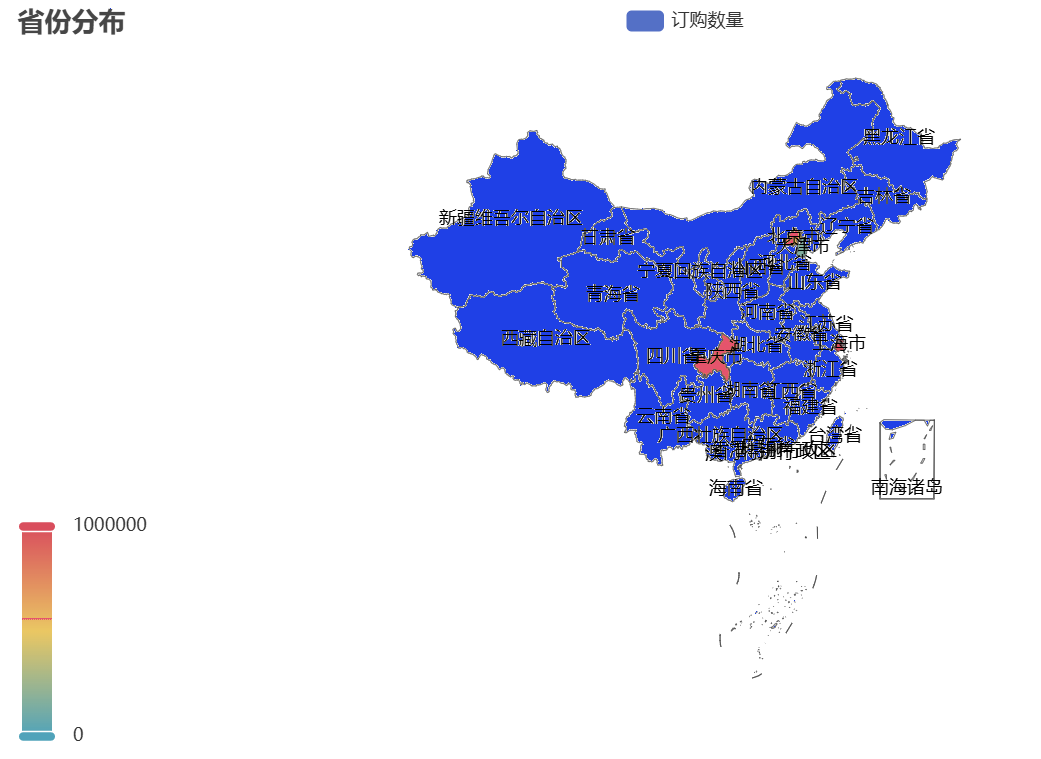
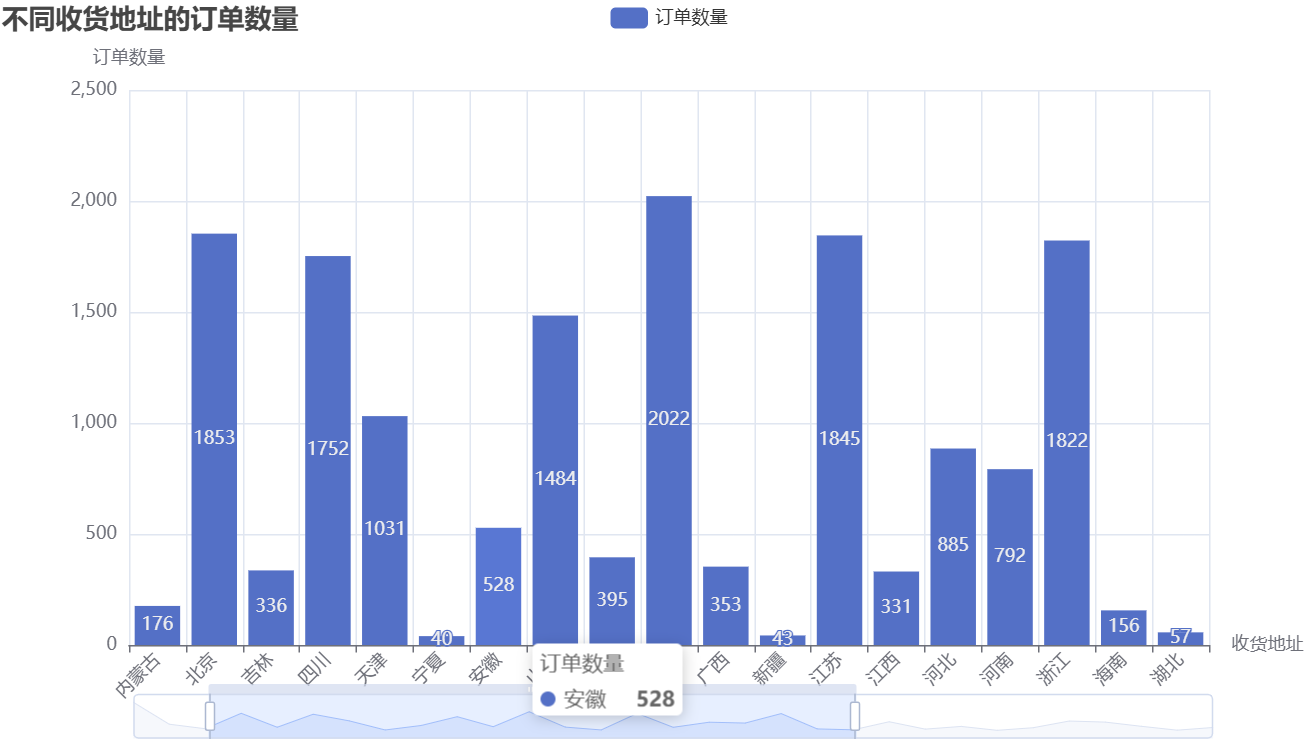
从图中可观察到,华东、华南等沿海省份订单量显著高于其他地区——这与这些地区经济水平高、消费能力强的特征相符。企业可针对高订单量地区加大推广,同时关注低订单量地区的市场潜力(如通过优惠活动拓展下沉市场)。
相关文章

Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
原文链接:https://tecdat.cn/?p=42219
3.3 时间趋势分析
从“每日”和“每小时”两个维度分析订单趋势,结合业务场景解读规律:
3.3.1 每日订单量走势
-
from pyecharts.charts import Line
-
# 将订单创建时间转为datetime格式,按“年-月-日”分组统计每日订单数
-
tmall_order_data['订单创建时间'] = pd.to_datetime(tmall_order_data['订单创建时间'])
-
tmall_daily_order = tmall_order_data.groupby(
-
tmall_order_data['订单创建时间'].apply(lambda x: x.strftime("%Y-%m-%d"))
-
).agg({'订单编号':'count'}).to_dict()['订单编号']
-
# 绘制每日订单量折线图
-
daily_order_line = Line()
-
daily_order_line.add_xaxis(list(tmall_daily_order.keys()))
-
daily_order_line.add_yaxis("订单量", list(tmall_daily_order.values()))
-
daily_order_line.set_series_opts(
-
label_opts=opts.LabelOpts(is_show=False), # 隐藏数据标签避免杂乱
-
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max", name="最大值")]) # 标记峰值
-
)
-
daily_order_line.set_global_opts(title_opts=opts.TitleOpts(title="天猫每日订单量走势"))
-
daily_order_line.render('天猫每日订单量走势.html')
可视化结果如下: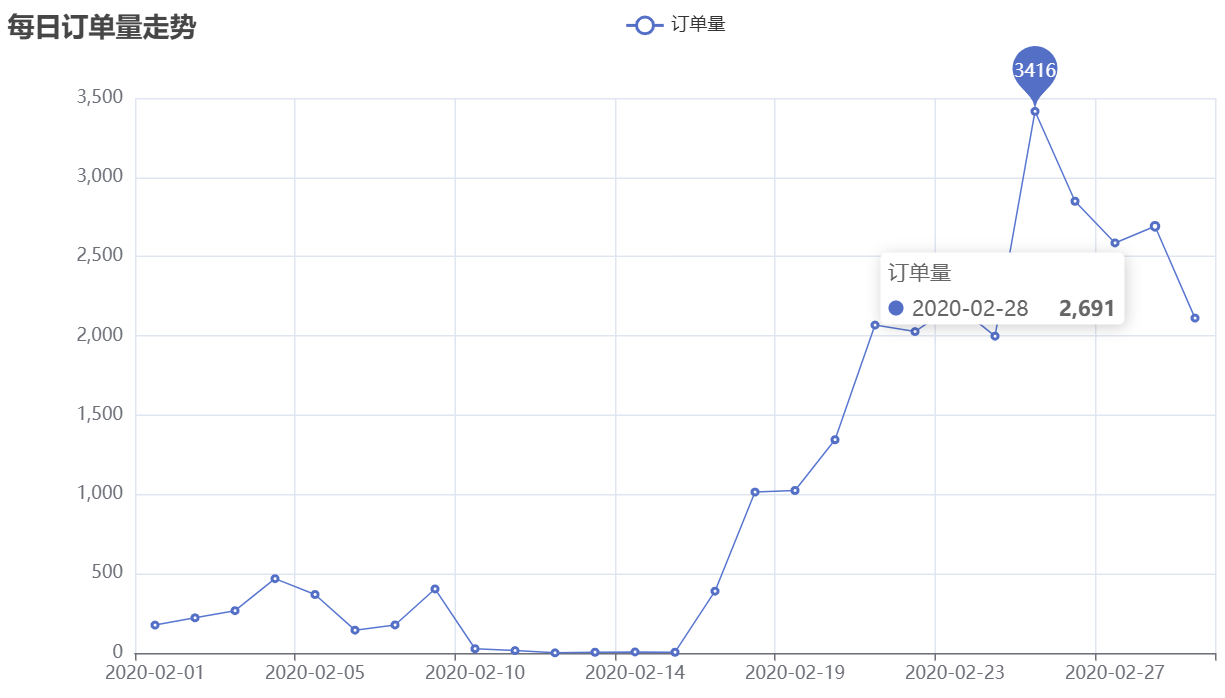
从图中可清晰看到,2月份上半月订单量显著偏低——这与当时新冠疫情的影响直接相关:疫情导致物流停运、企业复工延迟,消费者下单意愿下降;随着疫情控制好转、物流与复工逐步恢复,2月下半月订单量快速增长。这一规律提示企业,需关注突发公共事件对订单的影响,提前制定应急预案(如疫情时增加线上客服、优化库存)。
3.3.2 每小时订单量走势
-
# 按“小时”分组统计订单数,分析一天内的下单高峰
-
tmall_hourly_order = tmall_order_data.groupby(
-
tmall_order_data['订单创建时间'].apply(lambda x: x.strftime("%H"))
-
).agg({'订单编号':'count'}).to_dict()['订单编号']
-
# 绘制每小时订单量柱状图
-
hourly_order_bar = Bar()
-
x_data = list(tmall_hourly_order.keys())
-
y_data = list(tmall_hourly_order.values())
-
hourly_order_bar.add_xaxis(x_data)
-
hourly_order_bar.add_yaxis("订单量", y_data)
-
hourly_order_bar.set_global_opts(title_opts=opts.TitleOpts(title="天猫每小时订单量走势"))
-
hourly_order_bar.set_series_opts(
-
label_opts=opts.LabelOpts(is_show=False),
-
markpoint_opts=opts.MarkPointOpts(
-
data=[
-
opts.MarkPointItem(type_="max", name="峰值"),
-
opts.MarkPointItem(name="第二峰值", coord=[x_data[15], y_data[15]], value=y_data[15]),
-
opts.MarkPointItem(name="第三峰值", coord=[x_data[10], y_data[10]], value=y_data[10]),
-
]
-
),
-
)
-
hourly_order_bar.render('天猫每小时订单量走势.html')
-
# 计算下单到付款的平均时间(单位:分钟)
-
order_pay_interval = tmall_order_data['订单付款时间'] - tmall_order_data['订单创建时间']
-
avg_pay_time = order_pay_interval[order_pay_interval.notnull()].apply(lambda x: x.seconds / 60).mean()
-
print(f"下单到付款的平均时间:{avg_pay_time:.2f} 分钟")
可视化结果如下: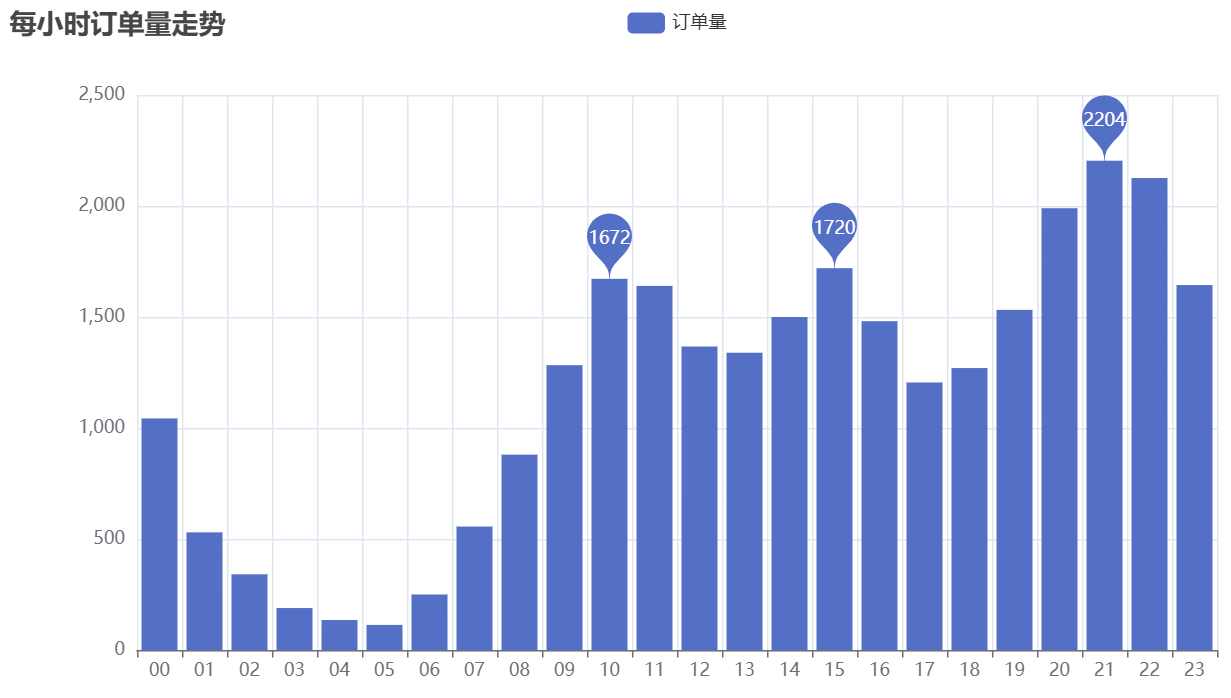
分析发现,一天内存在三个下单高峰:10点(上午工作间隙)、15点(下午空闲时段)、21点(晚上休息时段),其中21点是全天订单量最高的时段。结合“下单到付款平均时间”,企业可在高峰时段优化客服排班(如安排夜班客服处理21点咨询),同时简化付款流程(如默认地址、快速支付),减少客户因等待或操作复杂放弃付款的情况。
三、日化商品销售数据分析
日化商品销售数据包含“销售订单表”与“商品信息表”,需通过表关联分析商品销售趋势、地区差异与客户价值,为品类运营与客户分层提供依据。
1. 数据读取与预处理
1.1 数据读取
-
import pandas as pd
-
# 读取日化商品的销售订单表与商品信息表(Excel文件的两个sheet)
-
daily_chem_order = pd.read_excel("D:\\OrderFromTmall\\日化.xlsx", sheet_name='销售订单表')
-
daily_chem_product = pd.read_excel("D:\\OrderFromTmall\\日化.xlsx", sheet_name='商品信息表')
-
# 初步探查销售订单表结构
-
print("销售订单表前5行:")
-
print(daily_chem_order.head())
-
print("\n销售订单表信息:")
-
print(daily_chem_order.info())
1.2 数据预处理
针对销售订单表与商品信息表分别进行清洗,确保数据质量:
-
# 1. 销售订单表预处理
-
# 去重:删除重复订单(避免重复统计)
-
daily_chem_order.drop_duplicates(inplace=True)
-
daily_chem_order.reset_index(drop=True, inplace=True) # 重建索引
-
# 补空:用后向填充(bfill)和前向填充(ffill)处理缺失值
-
daily_chem_order.fillna(method='bfill', inplace=True)
-
daily_chem_order.fillna(method='ffill', inplace=True)
-
# 日期格式标准化:处理“2021-01-01”后的脏数据(数据应在2019.1-2019.9区间)
-
daily_chem_order['订单日期'] = daily_chem_order['订单日期'].apply(
-
lambda x: pd.to_datetime(x, format='%Y#%m#%d') if isinstance(x, str) else x
-
)
-
daily_chem_order = daily_chem_order[daily_chem_order['订单日期'] < '2021-01-01'] # 过滤脏数据
-
# 数值格式标准化:去除“个”“元”等单位,转为数值类型
-
daily_chem_order['订购数量'] = daily_chem_order['订购数量'].apply(
-
lambda x: x.strip('个') if isinstance(x, str) else x
-
).astype('int')
-
daily_chem_order['订购单价'] = daily_chem_order['订购单价'].apply(
-
lambda x: x.strip('元') if isinstance(x, str) else x
-
).astype('float')
-
daily_chem_order['金额'] = daily_chem_order['金额'].astype('float')
-
# 地址标准化:同天猫订单数据处理逻辑
-
address_clean_dict = {'自治区': '', '维吾尔': '', '回族': '', '壮族': '', '省': ''}
-
for key, value in address_clean_dict.items():
-
daily_chem_order['所在省份'] = daily_chem_order['所在省份'].str.replace(key, value)
-
# 客户编码清洗:去除“编号”冗余词
-
daily_chem_order['客户编码'] = daily_chem_order['客户编码'].str.replace('编号', '')
-
# 2. 商品信息表预处理(主要检查重复与空值)
-
print("商品信息表重复数据数量:", daily_chem_product[daily_chem_product.duplicated()].count()[0])
-
print("商品信息表空值数量:\n", daily_chem_product.isnull().sum())
-
# 无重复与空值,无需额外清洗
2. 数据可视化与业务分析
2.1 每月订购情况分析
通过双轴柱状图展示每月订购数量与金额,分析月度销售趋势:
-
from pyecharts.charts import Bar
-
# 提取订单月份,按月份分组统计订购数量与金额
-
daily_chem_order['订单月份'] = daily_chem_order['订单日期'].apply(lambda x: x.month)
-
monthly_order_stats = daily_chem_order.groupby('订单月份').agg({'订购数量': 'sum', '金额': 'sum'}).to_dict()
-
# 准备绘图数据(数量单位:万件,金额单位:亿元)
-
x_data = [f'{key} 月' for key in monthly_order_stats['订购数量'].keys()]
-
y1 = [round(val/10000, 2) for val in monthly_order_stats['订购数量'].values()] # 订购数量(万件)
-
y2 = [round(val/10000/10000, 2) for val in monthly_order_stats['金额'].values()] # 金额(亿元)
-
# 绘制双轴柱状图
-
monthly_order_bar = Bar()
-
monthly_order_bar.add_xaxis(x_data)
-
monthly_order_bar.add_yaxis("订购数量(万件)", y1)
-
monthly_order_bar.add_yaxis("金额(亿元)", y2)
-
monthly_order_bar.set_global_opts(title_opts=opts.TitleOpts(title="日化商品每月订购情况"))
-
monthly_order_bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 显示数值标签
-
monthly_order_bar.render('日化商品每月订购情况.html')
可视化结果如下: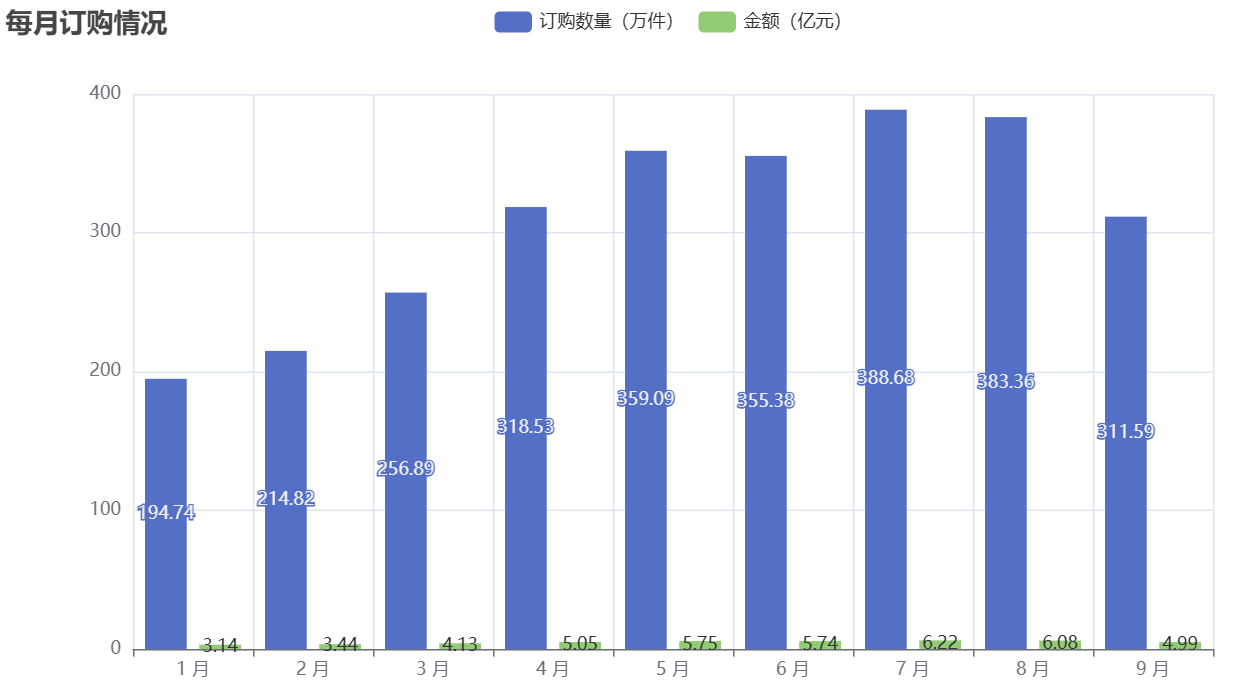
从图中可观察到,日化商品销售存在明显的月度波动(如夏季月份销量可能高于冬季,因夏季洗漱、防晒类日化品需求增加)。企业可根据月度趋势调整库存,避免旺季缺货或淡季积压。
2.2 市区订购数量TOP20分析
通过横向柱状图展示订购量前20的市区,定位高价值区域:
-
# 按所在地市分组统计订购数量,取前20并按升序排列(便于横向柱状图展示)
-
city_order_top20 = daily_chem_order.groupby('所在地市').agg({'订购数量': 'sum'}).sort_values(
-
by='订购数量', ascending=False
-
)[:20].sort_values(by='订购数量').to_dict()['订购数量']
-
# 绘制横向柱状图
-
city_order_bar = Bar()
-
city_order_bar.add_xaxis(list(city_order_top20.keys()))
-
city_order_bar.add_yaxis("订购量(万件)", [round(v/10000, 2) for v in city_order_top20.values()],
-
label_opts=opts.LabelOpts(position="right", formatter='{@[1]} 万'))
-
city_order_bar.reversal_axis() # 反转坐标轴,改为横向柱状图
-
city_order_bar.set_global_opts(title_opts=opts.TitleOpts("日化商品市区订购数量排行 TOP20"))
-
city_order_bar.render('日化商品市区订购数量排行 TOP20.html')
可视化结果如下: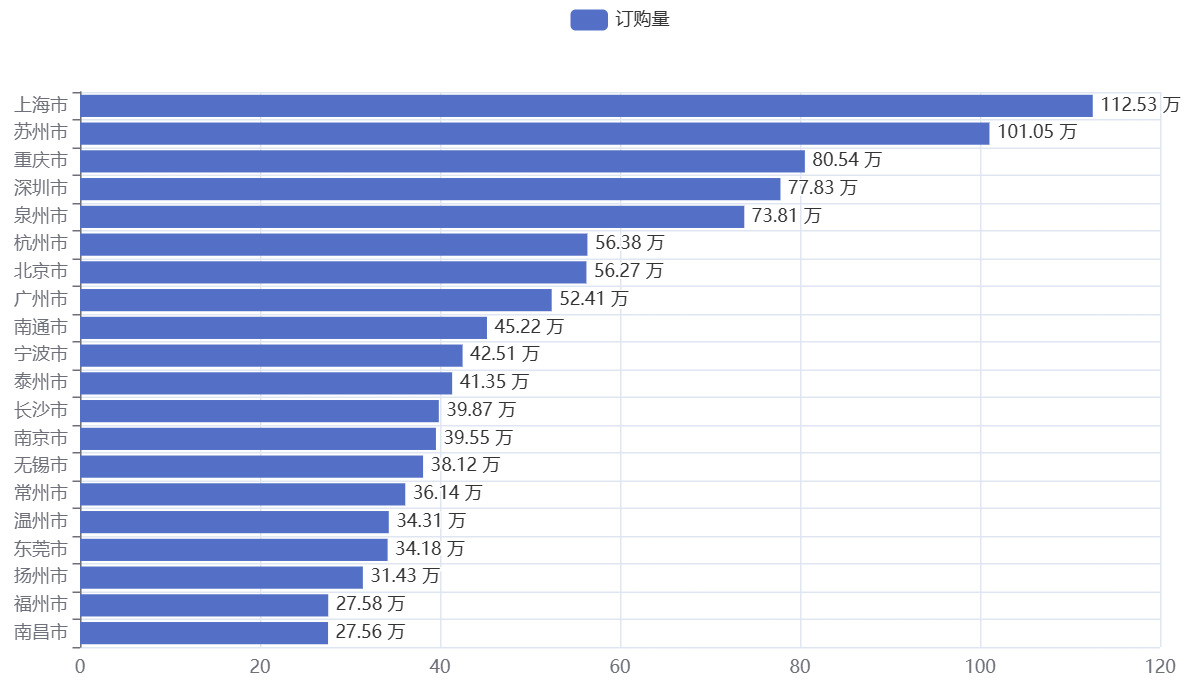
TOP20市区多为一线城市或新一线城市(如北京、上海、广州等),这些地区消费能力强、日化品需求大。企业可针对这些市区推出定制化推广活动(如联名产品、满减优惠),进一步提升销量。
2.3 省份订购数量分布分析
通过地图展示各省份订购量,把握全国区域差异:
-
from pyecharts.charts import Map
-
# 按所在省份分组统计订购数量
-
province_order = daily_chem_order.groupby('所在省份').agg({'订购数量': 'sum'}).to_dict()['订购数量']
-
# 绘制省份分布地图
-
province_order_map = Map()
-
province_order_map.add("订购数量", list(province_order.items()), "china", is_map_symbol_show=False)
-
province_order_map.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
-
province_order_map.set_global_opts(
-
title_opts=opts.TitleOpts(title='日化商品不同省份订购数量分布'),
-
visualmap_opts=opts.VisualMapOpts(max_=1000000) # 颜色范围对应订购量
-
)
-
province_order_map.render('日化商品不同省份订购数量分布.html')
可视化结果如下: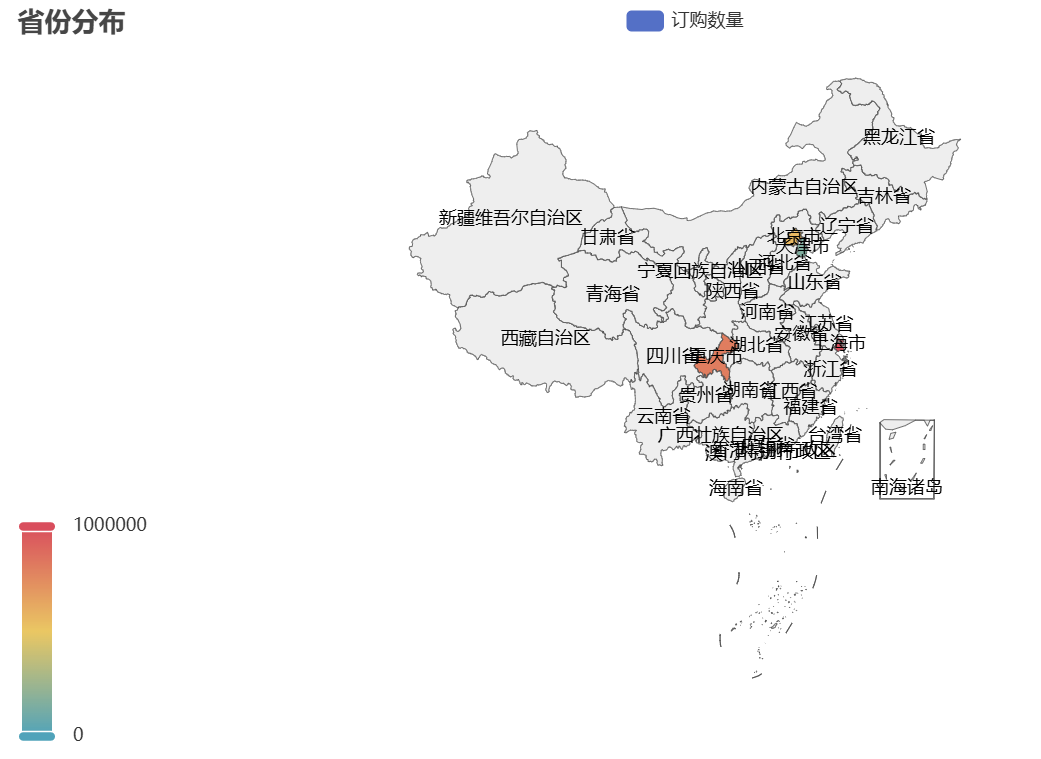
该地图与天猫订单地区分布趋势一致,华东、华南省份订购量领先。企业可在这些省份加强渠道布局(如与本地商超合作),同时针对西北、西南等低订购量省份,推出性价比更高的产品以拓展市场。
2.4 不同商品品类订购分析
通过表关联(销售订单表+商品信息表),分析不同品类的销售情况:
-
# 表关联:通过“商品编号”关联销售订单与商品信息,获取商品分类
-
daily_chem_merged = pd.merge(daily_chem_order, daily_chem_product, on='商品编号', how='inner')
-
# 按“商品大类-商品小类”分组,统计订购数量并按大类排序
-
category_order = daily_chem_merged.groupby(['商品大类', '商品小类']).agg({'订购数量': 'sum'}).sort_values(
-
by=['商品大类', '订购数量'], ascending=[True, False]
-
)
-
print("不同商品品类订购数量:")
-
print(category_order)
关联分析后可发现,日化商品中某类小类(如护肤品中的面膜、清洁用品中的洗衣液)订购量显著高于其他品类——这提示企业可加大该类商品的生产与推广,同时优化低销量品类(如调整配方、包装),提升整体品类效益。
3. RFM模型挖掘客户价值
RFM模型通过“最近购买时间(Recency)”“消费频率(Frequency)”“消费金额(Monetary)”三个维度量化客户价值,帮助企业实现客户分层运营:
-
# 计算RFM核心指标(按客户编码分组)
-
daily_chem_rfm = daily_chem_order.groupby('客户编码').agg({
-
'订单日期': 'max', # R:最近一次购买时间
-
'订单编码': 'count', # F:消费频率(订单次数)
-
'金额': 'sum' # M:消费金额
-
})
-
# 重命名字段,便于后续处理
-
daily_chem_rfm.columns = ['最近一次购买时间', '消费频率', '消费金额']
-
# 将R、F、M转为百分比排名(0-1区间),消除量纲影响
-
daily_chem_rfm['R_rank'] = daily_chem_rfm['最近一次购买时间'].rank(pct=True)
-
daily_chem_rfm['F_rank'] = daily_chem_rfm['消费频率'].rank(pct=True)
-
daily_chem_rfm['M_rank'] = daily_chem_rfm['消费金额'].rank(pct=True)
-
# 客户价值打分:权重M=50%、F=30%、R=20%(金额直接关联收入,权重最高)
-
daily_chem_rfm['customer_score'] = daily_chem_rfm['R_rank'] * 20 + daily_chem_rfm['F_rank'] * 30 + daily_chem_rfm['M_rank'] * 50
-
daily_chem_rfm['customer_score'] = daily_chem_rfm['customer_score'].round(1)
-
# 按分数降序排列,查看高价值客户
-
daily_chem_rfm_sorted = daily_chem_rfm.sort_values(by='customer_score', ascending=False)
-
print("客户价值分数TOP10:")
-
print(daily_chem_rfm_sorted.head(10))
根据customer_score可将客户分为三类:
- 高价值客户(score≥80):最近购买时间近、消费频率高、金额大——企业需提供专属服务(如VIP客服、定制优惠),维持客户忠诚度;
- 中价值客户(50≤score<80):消费频率或金额中等——企业可通过满减活动提升消费金额,增加购买频率;
- 低价值客户(score<50):最近购买时间远、频率低、金额小——企业可通过优惠券激活,引导再次购买。
通过RFM模型,企业能将有限的运营资源精准投向高价值客户,同时激活低价值客户,实现运营效率最大化。
四、总结
本报告以天猫订单数据与日化商品销售数据为核心,通过Python工具完成数据预处理、可视化分析与RFM模型应用,最终形成三大核心结论:
- 时间趋势规律:天猫订单受疫情影响呈现“2月上半月低、下半月高”的特征,一天内存在10点、15点、21点三个下单高峰——企业需针对性调整客服排班与应急预案;
- 地区消费差异:华东、华南等沿海省份订单量领先,一线城市市区是日化商品高价值区域——企业可加强这些地区的推广与渠道布局;
- 客户价值分层:通过RFM模型将日化商品客户分为高、中、低价值三类——企业可针对不同层级客户制定差异化运营策略,提升资源利用效率。
本次分析改编自实际电商咨询项目,所有代码与数据已分享至交流社群。未来可进一步结合用户画像数据(如年龄、性别),实现更精准的商品推荐与运营优化,助力企业在电商竞争中持续提升效益。
关于分析师
在此对 Jiaxin Yao 对本文所作的贡献表示诚挚感谢,她在浙江工业大学攻读数据科学与大数据技术专业,专注微博情感分析领域。擅长 Python、VMware(略熟悉 R 语言)、深度学习、数据采集 。