JBoltAI重塑智能检索:问题重写与混合检索如何破解企业RAG应用瓶颈
当前,生成式AI技术正在席卷全球各行业。然而,传统RAG系统在实际部署中面临两大核心痛点:查询意图理解偏差和检索召回率低下。这直接导致企业AI应用效果不尽如人意——要么找不到正确答案,要么生成的内容与实际情况不符。
01 企业RAG系统的现实困境
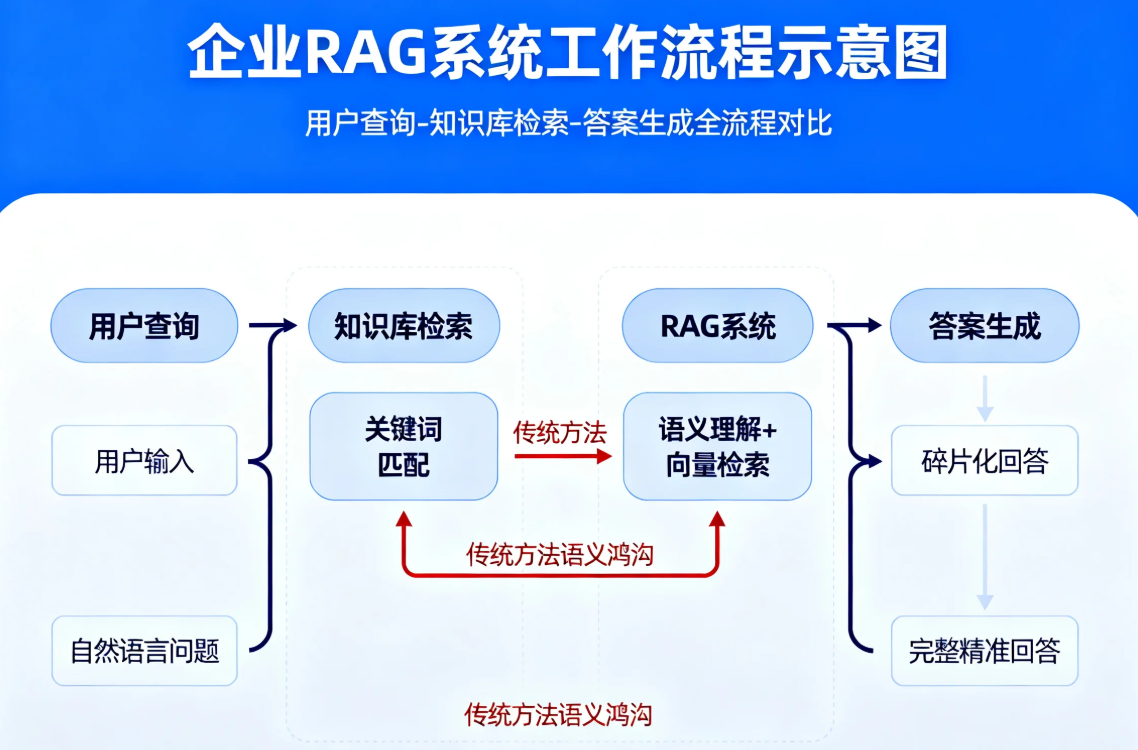
许多企业初期建设的RAG系统,往往停留在简单的“向量搜索+答案生成”层面。当用户提出问题时,系统仅仅对查询语句进行嵌入式处理,然后在向量空间中进行相似度匹配。这种方式在处理简单明确的问题时表现尚可,但面对复杂、多义或者表述不完整的查询时,效果大幅下降。
举个例子,当用户查询:“公司去年在东南亚地区的销售情况怎么样?”传统RAG系统可能直接匹配含有“东南亚”、“销售”、“去年”等关键词的文档片段。但如果知识库中存储的对应内容是“2024年东盟区域营收报告”,系统可能无法有效建立关联,导致检索失败。
问题的核心在于:用户查询的表述方式与知识库中文档的表述方式之间存在语义鸿沟。这就需要一种技术,能够自动弥合这一鸿沟,提高检索的准确性和召回率。
![]() 02 JBoltAI的问题重写技术原理
02 JBoltAI的问题重写技术原理
 02 JBoltAI的问题重写技术原理
02 JBoltAI的问题重写技术原理JBoltAI针对这一挑战,引入了问题重写技术(Query Rewrite),通过多步推理和语义扩展,显著提升了查询意图的准确表达。
问题重写的核心思想是:对原始查询进行解析、扩展和重构,生成多个不同角度、不同表述方式的查询语句,从而全面提高检索覆盖率。JBoltAI的问题重写模块主要采用以下技术方案:
java
// 问题重写处理器示例代码public class QueryRewriteProcessor {
@Autowired
private LLMIntegration llmIntegration;
public List<String> rewriteQuery(String originalQuery, QueryContext context) {
List<String> rewrittenQueries = new ArrayList<>();
// 1. 同义词扩展改写
rewrittenQueries.addAll(synonymExpansionRewrite(originalQuery));
// 2. 多角度推理改写
rewrittenQueries.addAll(perspectiveBasedRewrite(originalQuery));
// 3. 假设性文档嵌入改写
rewrittenQueries.addAll(hydeRewrite(originalQuery));
// 4. 多语言支持改写(针对跨国企业)
if (context.isMultilingual()) {
rewrittenQueries.addAll(multilingualRewrite(originalQuery, context.getTargetLanguages()));
}
return rewrittenQueries.stream()
.distinct()
.filter(query -> !query.trim().isEmpty())
.collect(Collectors.toList());
}
private List<String> hydeRewrite(String originalQuery) {
// 使用大模型生成假设性文档,然后基于假设文档提取检索查询
String hypotheticalDocument = llmIntegration.generateHypotheticalDocument(originalQuery);
return extractQueriesFromDocument(hypotheticalDocument);
}
// 其他重写方法实现...}
JBoltAI的问题重写技术不仅限于简单的同义词替换,而是深度融合了以下四种重写策略:
- 同义词扩展改写:基于领域专业词典,将查询中的关键词替换为同义词、近义词或相关术语;
- 多角度推理改写:分析查询意图,从不同角度生成多个查询变体。例如对于“销售业绩”查询,会生成“营收情况”、“业绩表现”、“销售额”等多个相关变体;
- 假设性文档嵌入改写(HyDE):通过大模型生成假设性答案文档,然后从该文档中提取关键检索词,这是一种更接近人类思维过程的查询重构方法;
- 多语言统一改写:针对跨国企业多语言知识库,提供跨语言查询重写能力,确保不同语言用户都能获取一致的知识体验。
03 混合检索:向量搜索与关键词搜索的融合
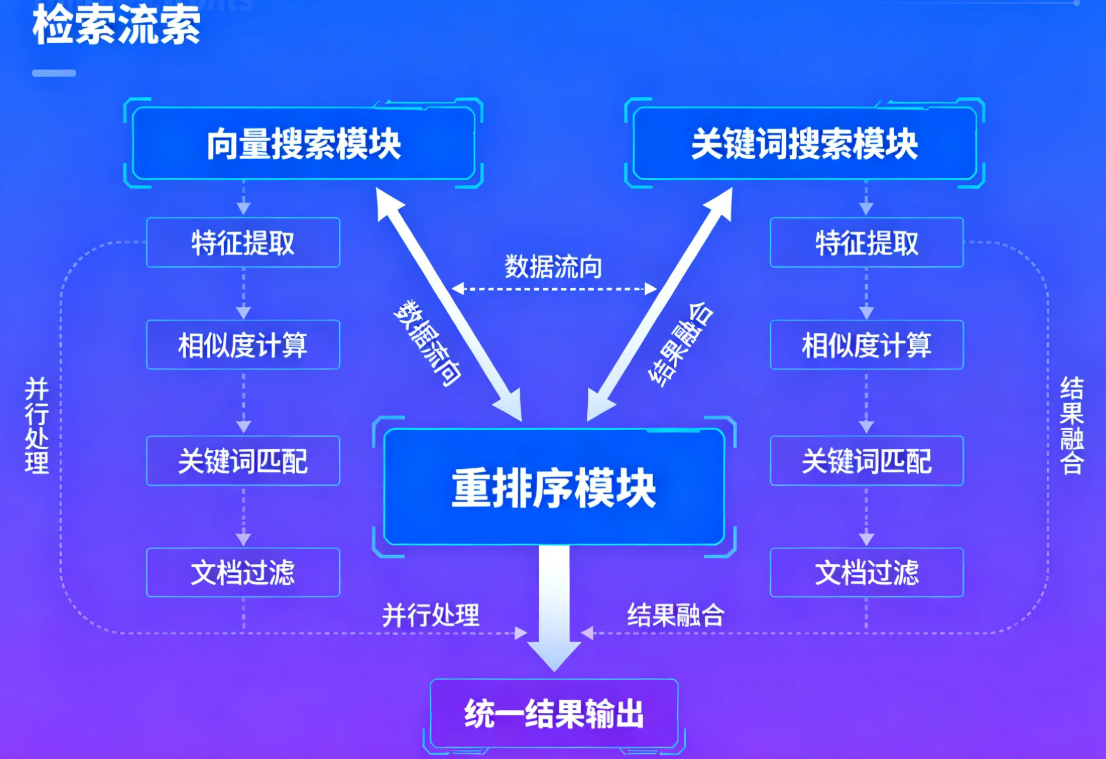
问题重写解决了查询侧的表述多样性问题,而JBoltAI的混合检索技术则从检索机制本身入手,结合了向量搜索和传统关键词搜索的优势,形成更全面的检索方案。
java
// 混合检索执行器示例代码public class HybridRetriever {
@Autowired
private VectorStore vectorStore;
@Autowired
private KeywordSearchEngine keywordSearchEngine;
public List<Document> hybridRetrieve(List<String> rewrittenQueries, HybridRetrieveConfig config) {
List<Document> allResults = new ArrayList<>();
for (String query : rewrittenQueries) {
// 并行执行向量检索和关键词检索
CompletableFuture<List<Document>> vectorFuture = CompletableFuture
.supplyAsync(() -> vectorSearch(query, config.getVectorSearchLimit()));
CompletableFuture<List<Document>> keywordFuture = CompletableFuture
.supplyAsync(() -> keywordSearch(query, config.getKeywordSearchLimit()));
// 合并结果
List<Document> vectorResults = vectorFuture.join();
List<Document> keywordResults = keywordFuture.join();
allResults.addAll(vectorResults);
allResults.addAll(keywordResults);
}
// 结果去重与重排序
return rerankAndDeduplicate(allResults, config.getReranker());
}
private List<Document> vectorSearch(String query, int limit) {
// 执行向量相似度搜索
return vectorStore.similaritySearch(query, limit);
}
private List<Document> keywordSearch(String query, int limit) {
// 执行关键词布尔搜索
return keywordSearchEngine.search(query, limit);
}
// 结果重排序与去重逻辑...}
混合检索技术的优势在于克服了单一检索方法的局限性
- 向量搜索擅长捕捉语义相似性,能够找到概念相关但表述不同的内容;
- 关键词搜索擅长捕捉精确匹配,对于术语、代码、特定名称等精确匹配效果更好。
04 技术实现最佳实践
基于JBoltAI构建高效RAG系统时,我们总结出以下最佳实践:
1. 领域自适应的查询重写
不同行业和领域需要定制化的重写策略。JBoltAI支持领域词典导入和重写规则配置,确保重写后的查询符合领域特点。
java
// 领域自适应重写配置示例@Configurationpublic class DomainSpecificRewriteConfig {
@Bean
public QueryRewriteProcessor medicalDomainRewriteProcessor() {
QueryRewriteProcessor processor = new QueryRewriteProcessor();
processor.setDomainDictionary(loadMedicalDictionary());
processor.addRewriteRule(new MedicalQueryRewriteRule());
processor.addRewriteRule(new SymptomBasedRewriteRule());
return processor;
}
private DomainDictionary loadMedicalDictionary() {
// 加载医学领域专业词典
DomainDictionary dictionary = new DomainDictionary();
dictionary.addSynonyms("heart attack", Arrays.asList("myocardial infarction", "cardiac arrest"));
dictionary.addSynonyms("MRI", Arrays.asList("magnetic resonance imaging"));
// 更多领域术语...
return dictionary;
}}
2. 分层检索与渐进式细化
对于大规模知识库,采用分层检索策略:先检索粗粒度结果,再基于初步结果进行细化查询,平衡检索效率与准确性。
3. 多模型融合的重新排序
结合多种排序信号(向量相似度、关键词匹配度、文档新鲜度、用户偏好等),通过学习排序模型(LTR)优化最终结果排序。
[配图占位和描述-开始]
JBoltAI RAG系统整体架构图,展示从查询输入到答案输出的完整流程,包括问题重写、混合检索、答案生成等模块,架构图风格,专业技术图解,蓝绿色调
[配图占位和描述-结束]
05 未来展望:智能检索的发展趋势
随着AI技术的不断发展,JBoltAI也在持续演进其检索能力。未来重点发展方向包括:
- 多模态检索扩展:支持图像、视频、音频等非文本内容的联合检索,实现真正的多模态知识管理;
- 时序感知检索:引入时间维度感知,理解知识的时间相关性和演变规律,为决策提供更准确的趋势分析;
- 自适应检索系统:系统能够根据用户反馈和交互模式自动调整检索策略,形成个性化检索体验;
- 因果推理增强:将因果推理融入检索过程,不仅找到相关文档,还能理解信息之间的因果关系。
赋能企业知识管理新范式
JBoltAI通过问题重写和混合检索技术的创新性结合,有效解决了企业RAG应用中的检索瓶颈问题,实现了召回率与准确率的双重提升。这不仅技术上的突破,更是对企业知识管理范式的重新定义。
企业知识管理正从传统的“分类-归档-检索”模式,向“理解-扩展-精准匹配”的智能模式转变。JBoltAI作为这一转变的推动者,正在帮助各行业企业释放知识资产的潜在价值,赋能数智化转型。
正如DeepSeek团队所言:“AI不是要取代人类,而是要赋予每个人超能力。” JBoltAI的智能检索技术,正是赋予企业“知识超能力”的关键工具。