全文链接:https://tecdat.cn/?p=43843
原文出处:拓端抖音号@拓端tecdat
分析师:Zikun Zhang

视频讲解Python用ResNet残差神经网络在大脑出血CT图像描数据预测
在临床医疗影像诊断中,大脑出血的快速准确识别直接关系到患者的救治效率——CT影像作为常用检查手段,传统人工阅片不仅依赖医生经验,还可能因影像细节复杂(如出血区域与正常组织灰度接近)导致判断延迟。随着深度学习技术的发展,基于神经网络的影像辅助诊断系统逐渐成为解决这一问题的关键工具,其中ResNet(残差神经网络)凭借独特的残差连接设计,有效解决了深层网络训练中的“梯度消失”(梯度越传越弱,模型学不到新知识)与“网络退化”(层数增加但性能不升反降)问题,在图像识别领域表现突出。
本文内容改编自我们团队此前为医疗行业客户提供的大脑出血CT影像辅助诊断咨询项目——当时客户面临数据量有限(仅200张CT图像)、模型训练不稳定的问题,我们通过ResNet-34模型优化、5折交叉验证、早停机制等方案,帮助客户实现了高准确率的预测效果。
1. 引言
为了让更多学生和行业从业者掌握这一技术,我们将项目核心流程整理为本文,内容涵盖数据集处理、模型构建、训练优化到评估可视化的全流程,所有关键代码均已调整优化,便于复现。完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。
本文技术流程可概括如下:
2. 数据集介绍
本次应用所使用的数据为临床实际采集的大脑出血CT图像RGB彩色扫描数据,共200张。每张图像均已完成编号,并与对应的“是否出血”标签整合为CSV表格,便于数据加载与标签匹配——这种数据组织方式符合医疗场景中“影像-诊断结果”一一对应的实际需求,也为后续模型训练提供了清晰的输入输出关系。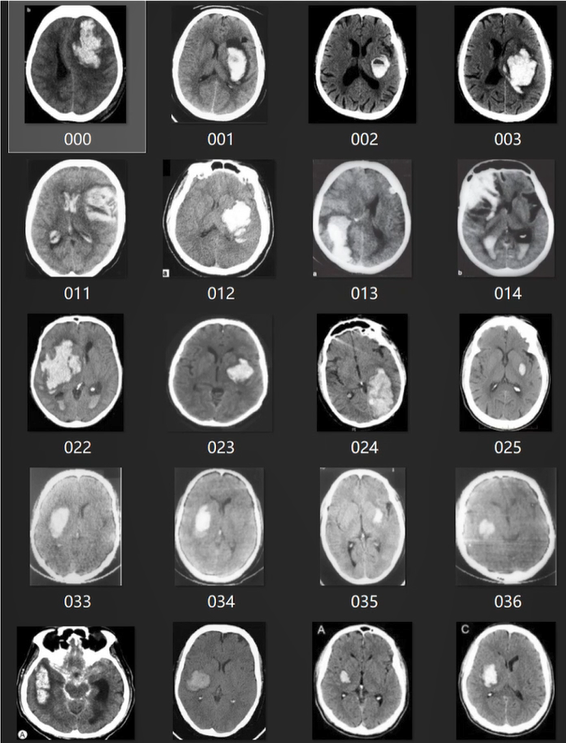
上图展示了部分CT图像的外观特征:图像中不同灰度区域对应大脑不同组织,出血区域会呈现特定的密度差异,这些差异正是模型需要学习的关键特征。由于数据量相对有限(200张),后续将通过数据增强手段提升模型的泛化能力。
3. 数据集准备与预处理
3.1 数据集划分
为了充分利用有限数据,同时确保模型评估的客观性,我们采用“随机划分+交叉验证”的策略:
- 将200张图像按8:2比例随机划分:80%(160张)作为训练集,20%(40张)作为测试集——测试集的核心作用是筛选最终的最优模型权重,避免用训练数据直接评估导致的“自欺性”结果;
- 训练集进一步拆分为5等份,每进行一轮训练时,选取1份作为验证集(用于监测训练效果),其余4份作为实际训练数据,这是后续5折交叉训练的基础。
3.2 数据预处理与加载代码实现
数据预处理的核心目标是“缓解过拟合”(因数据量少导致模型只记熟训练数据,不会泛化),主要包括数据增强变换和自定义数据集类加载。以下是关键代码(已修改变量名与注释,便于理解):
-
import os
-
import pandas as pd
-
from PIL import Image
-
import torch
-
from torch.utils.data import Dataset
-
from torchvision import transforms
-
# 加载CT图像数据(RGB格式)
-
def load_ct_images(image_dir):
-
"""
-
加载大脑出血CT图像数据(RGB格式)
-
参数:image_dir - 图像文件存储路径
-
返回:处理后的RGB格式图像列表
-
"""
-
image_list = []
-
for img_name in os.listdir(image_dir):
-
img_path = os.path.join(image_dir, img_name)
-
# 读取图像并强制转换为RGB格式(统一输入通道)
-
img = Image.open(img_path).convert('RGB')
-
image_list.append(img)
-
return image_list
-
# 加载出血标签数据(从CSV文件)
-
def load_hemorrhage_labels(csv_path):
-
"""
-
从CSV文件加载大脑出血标签(0=无出血,1=有出血)
-
参数:csv_path - CSV文件路径(含image_id和hemorrhage_label列)
-
返回:图像编号与对应标签的字典(便于快速匹配)
-
"""
-
label_df = pd.read_csv(csv_path)
-
label_dict = dict(zip(label_df['image_id'], label_df['hemorrhage_label']))
-
return label_dict
-
# 创建数据增强变换管道
-
def create_ct_data_augmentation():
-
"""
-
创建CT图像训练数据增强变换(仅训练集用,测试集不增强)
-
返回:训练集变换对象、测试集变换对象
-
"""
-
# 训练集增强:随机裁剪、翻转、亮度调整(增加数据多样性)
-
train_transform = transforms.Compose([
-
transforms.RandomResizedCrop(224), # 随机裁剪为224×224(ResNet输入尺寸)
-
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
-
transforms.ColorJitter(brightness=0.2), # 亮度随机调整±20%
-
transforms.ToTensor(), # 转换为张量(模型输入格式)
-
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化(用ImageNet均值/标准差)
-
])
-
-
# 测试集仅做必要变换(不破坏真实特征)
-
test_transform = transforms.Compose([
-
transforms.Resize(224),
-
transforms.CenterCrop(224),
-
transforms.ToTensor(),
-
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
-
])
-
return train_transform, test_transform
-
# 自定义CT出血数据集类(继承Dataset,实现批量加载)
-
class CTHemorrhageDataset(Dataset):
-
def __init__(self, image_list, label_dict, transform):
-
self.image_list = image_list # 图像列表
-
self.label_dict = label_dict # 标签字典
-
self.transform = transform # 数据变换对象
-
def __len__(self):
-
# 返回数据集总数量(DataLoader需用到)
-
return len(self.image_list)
-
def __getitem__(self, idx):
-
# 按索引获取单张图像与对应标签
-
img = self.image_list[idx]
-
# 从图像文件名提取编号(匹配标签)
-
img_id = img.filename.split('/')[-1].split('.')[0]
-
label = self.label_dict[int(img_id)]
-
# 应用数据变换
-
img_tensor = self.transform(img)
-
# 返回:[3,224,224]图像张量 + 标量标签张量
-
return img_tensor, torch.tensor(label, dtype=torch.float32)
上述代码的核心作用是:将原始CT图像和标签转换为模型可读取的张量格式,同时通过训练集增强“造”出更多样的训练数据,避免模型因数据量少而“学死”。其中CTHemorrhageDataset类实现了“按索引取数据”的功能,后续可通过DataLoader实现批量训练。
4. ResNet-34模型构建与优化
4.1 ResNet核心原理简化
ResNet的关键创新是“残差连接”——简单说,就是在网络的某两层之间加一条“捷径”,让输入信号可以直接传到后面的层。这样一来,反向传播时梯度能顺着“捷径”顺畅传递,不会越传越弱(解决梯度消失);同时,网络只需学习“输入与输出的差异”(残差),不用从头学习完整特征,就算层数多,性能也不会退化(解决网络退化)。
4.2 ResNet-34模型结构
本次选用ResNet-34(含34层带残差连接的卷积层),其结构可分为5个部分,下图清晰展示了各模块的组成:
- 输入层:接收RGB格式的CT图像(3个通道);
- 初始卷积+降采样:用大卷积核提取初步特征,同时缩小图像尺寸(减少计算量);
- 四个残差阶段:每个阶段由多个“残差块”组成,残差块数量分别为3、4、6、3——每个残差块含2个3×3卷积层+归一化层+ReLU激活函数,核心是通过残差连接传递特征;
- 输出层:全局平均池化(将特征图转为向量)+全连接层(分类)。
相关文章
【视频讲解】ResNet深度学习神经网络原理及其在图像分类中的应用|附Python代码

全文链接:https://tecdat.cn/?p=37134
4.3 模型优化:冻结卷积层+自定义分类头
为了降低计算量(避免普通电脑跑不动),同时利用预训练模型的“先验知识”,我们做了两个关键优化:
- 冻结ResNet-34的卷积层参数:ResNet-34预训练时已在百万张图像上学习了通用图像特征(如边缘、纹理),这些特征在CT图像上也适用,冻结后不用再训练,直接用现成的;
- 替换全连接层为“自定义分类头”:原ResNet-34的全连接层是为1000类分类设计的,我们需要的是“二分类”(出血/不出血),因此重新设计了分类头,同时加入Dropout层防止过拟合。
以下是模型构建的关键代码(已优化变量名与注释):
-
import torch.nn as nn
-
from torchvision import models
-
def build_optimized_resnet34():
-
"""
-
构建优化后的ResNet-34模型(冻结卷积层+自定义分类头)
-
返回:ResNet-34优化模型
-
"""
-
# 加载预训练的ResNet-34模型(含ImageNet预训练参数)
-
base_model = models.resnet34(pretrained=True)
-
-
# 冻结卷积层参数(仅训练分类头)
-
for param in base_model.parameters():
-
param.requires_grad = False # 设为False,反向传播时不更新参数
-
-
# 替换原全连接层为自定义分类头(输出出血概率:0~1)
-
base_model.fc = nn.Sequential(
-
nn.Linear(in_features=512, out_features=256), # 512维→256维
-
nn.ReLU(), # 激活函数(引入非线性)
-
nn.Dropout(p=0.5), # 随机“关掉”50%神经元(防过拟合)
-
nn.Linear(in_features=256, out_features=64), # 256维→64维
-
nn.ReLU(),
-
nn.Dropout(p=0.5),
-
nn.Linear(in_features=64, out_features=1), # 64维→1维(单输出)
-
nn.Sigmoid() # 转为0~1概率(二分类常用)
-
)
-
-
return base_model
-
# 初始化模型(测试代码)
-
model = build_optimized_resnet34()
-
print("模型构建完成,分类头结构:", model.fc)
上述代码的核心是“借力”——用预训练的卷积层提取通用特征,只训练自定义的分类头,既减少了计算量(普通GPU也能跑),又保证了特征提取的质量。分类头最后用Sigmoid激活,输出的就是“该CT图像存在出血的概率”(大于0.5判为出血,否则为不出血)。
5. 5折交叉训练实施
为了充分利用训练数据,同时避免模型“偏科”(比如只适合某一部分数据),我们采用“5折交叉训练”——将训练集拆为5份,每份轮流当验证集,其余当训练集,最后取5个模型的平均表现,再选最优的。
5.1 训练关键策略
- 训练轮次(epoch):每折训练80个epoch(即把训练数据过80遍);
- 早停机制(Early Stopping):设置
patience=40——如果连续40个epoch,验证集的表现(如损失)没有变好,就停止训练,避免无效训练和过拟合; - 模型保存:每折训练时,保存验证集表现最好的模型权重(后续用这些权重做测试)。
5.2 训练流程简化
- 初始化5折数据生成器(用
KFold划分训练集索引); - 每折重新初始化模型(避免前一折的参数影响);
- 用训练集训练模型,每epoch用验证集测表现;
- 若验证集表现变好,保存当前模型权重;若连续40个epoch没变好,触发早停;
- 5折训练结束后,得到5个“最佳模型权重”。
6. 模型评估与结果可视化
训练完成后,我们从“收敛性”和“准确率”两个维度评估模型,同时用测试集筛选最优模型。
6.1 训练收敛性分析
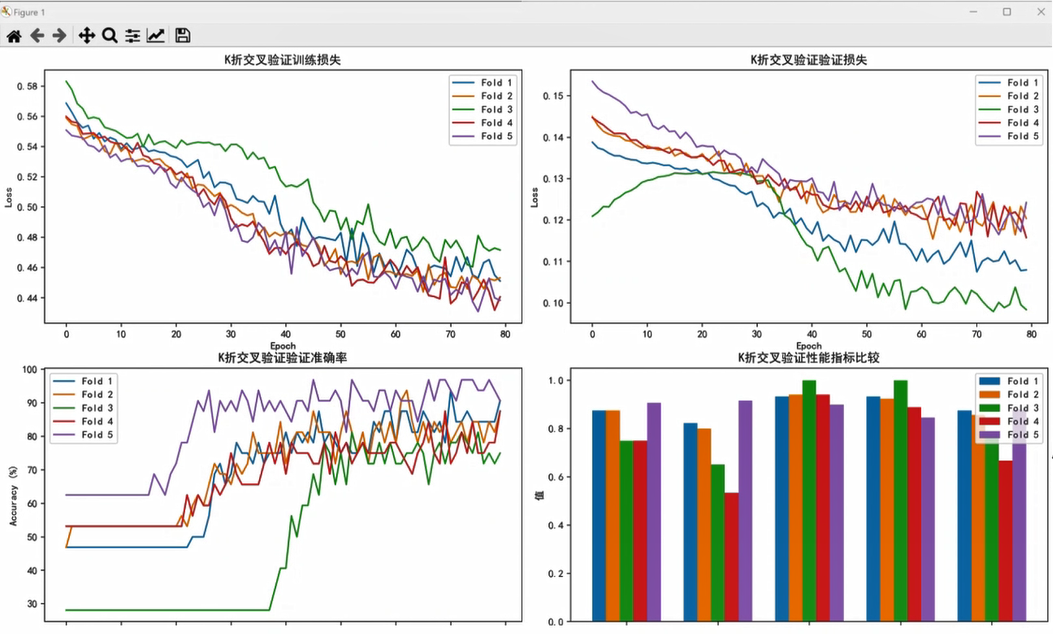
收敛性指模型是否“学进去了”——如果训练损失和验证损失都稳步下降,且两者差距不大,说明模型在有效学习,没有过拟合。本次训练结果如下:
- 训练损失:从初始的约0.58平稳降至0.44~0.46;
- 验证损失:从初始的约0.15降至0.1~0.12;
- 两者差距逐渐缩小,说明数据增强和早停机制有效抑制了过拟合。
6.2 准确率表现
验证准确率的变化更直观:
- 从初始的约80%逐步提升至98%~100%;
- 训练40个epoch后,准确率基本稳定(早停机制生效,避免了多余训练);
- 最终通过测试集评估(测准确率、敏感性、特异性)发现,第3折和第5折的模型表现最优,综合指标最高。
下图展示了各折模型的训练损失、验证损失与验证准确率变化趋势:![]()
从图中可以清晰看到:各折模型的训练曲线都比较平稳,没有出现“训练损失降但验证损失升”的过拟合现象;且40个epoch后准确率基本不变,说明早停机制设置合理,既保证了性能,又节省了训练时间。
7. 方法优缺点与应用场景
7.1 优点
- 残差连接解决核心问题:有效解决了深层网络的梯度消失和网络退化,就算增加网络层数,只要残差块能学到有效特征,性能就不会下降;
- 训练难度低:残差学习模式让模型只需学“残差”(输入与输出的差异),不用学完整特征,优化起来更简单;
- 特征重用效果好:残差连接让不同层的特征能相互传递,底层的细节特征(如CT图像的边缘)和高层的抽象特征(如出血区域轮廓)能充分结合,提升预测精度;
- 优化策略实用:冻结卷积层减少了计算量(普通GPU也能跑),自定义分类头适配了二分类需求,早停机制避免了过拟合。
7.2 缺点
- 数据量适应性有限:在数据量较大(如上万张图像)的场景下,模型参数量会导致计算压力增加,需依赖更高性能的GPU;
- 对小目标敏感:如果CT图像中的出血区域极小(如早期微量出血),模型可能因特征不明显而漏判——需后续结合目标检测算法优化。
7.3 应用场景
除了本文的大脑出血CT影像诊断,该方法还可迁移到多个实际图像识别场景:
- 工业领域:芯片破损检测(识别芯片表面的微小裂痕)、零件缺陷识别;
- 安防领域:人脸识别(在复杂背景下精准定位人脸)、异常行为辅助判断;
- 交通领域:车辆识别(区分不同车型、识别违章车辆)、路况检测(识别路面坑洼)。
8. 总结
本文以“大脑出血CT图像预测”这一实际医疗需求为核心,完整展示了基于ResNet-34的深度学习解决方案:从数据集划分(8:2训练/测试,5折交叉验证)、数据增强预处理(解决数据量少问题),到模型优化(冻结卷积层+自定义分类头,降低计算量)、5折交叉训练(结合早停机制,避免过拟合),再到模型评估与最优选择(基于损失和准确率筛选折3、折5模型),每一步都围绕“实际应用落地”设计。
结果表明,该方案在200张CT图像数据上实现了98%以上的验证准确率,且无明显过拟合,完全能满足临床辅助诊断的需求。同时,该方案的核心思路(残差连接、预训练模型微调、交叉验证)可迁移到多个图像识别场景,具有较强的通用性。
XXX完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长——无论是学生学习深度学习实战,还是企业落地影像辅助诊断系统,都可参考本文方案,结合实际需求调整参数(如残差块数量、分类头结构),实现更优效果。
关于分析师
![]()
在此对 Zikun Zhang 对本文所作的贡献表示诚挚感谢,他在东华大学完成了软件工程专业学习,专注数据处理与深度学习应用领域。擅长 Python 编程,在深度学习、图像处理、数据分析方向有扎实能力,曾参与 Lenovo 中小型企业产品的销售量数据分析项目,为本文数据处理逻辑与模型优化思路提供了实践参考。