正常操作
步骤 1:安装 WSL
启用 WSL 功能:
以管理员身份打开 PowerShell 或 命令提示符,输入以下命令并回车:
powershell
wsl --install
这个命令会自动启用所需的 Windows 功能、下载并安装默认的 Ubuntu 发行版。
(如果上述命令无效,可以手动启用):
powershell
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
设置用户账号:
安装完成后,系统会提示你重启电脑。重启后,首次启动安装的 Ubuntu 应用,它会要求你创建一个纯英文的 UNIX 用户名和密码。
步骤 2:在 WSL 中安装 Hadoop
现在,你拥有了一个 Ubuntu 终端,接下来的所有操作都和在真正的 Linux 系统中一模一样。
更新软件包列表:
bash
sudo apt update
安装 Java (Hadoop 的依赖):
bash
sudo apt install openjdk-11-jdk -y
安装后验证:java -version
下载并安装 Hadoop:
bash
进入用户主目录
cd ~
使用 wget 下载 Hadoop (以 3.3.6 为例,可替换为最新版)
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
解压
tar -xzvf hadoop-3.3.6.tar.gz
重命名并移动到常用位置(可选)
mv hadoop-3.3.6 hadoop
sudo mv hadoop /usr/local/
配置环境变量和 Hadoop:
编辑 ~/.bashrc 文件:
bash
nano ~/.bashrc
在文件末尾添加:
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 # Java 路径可能不同,可用 update-alternatives --config java 查看
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效:source ~/.bashrc
可能出现错误
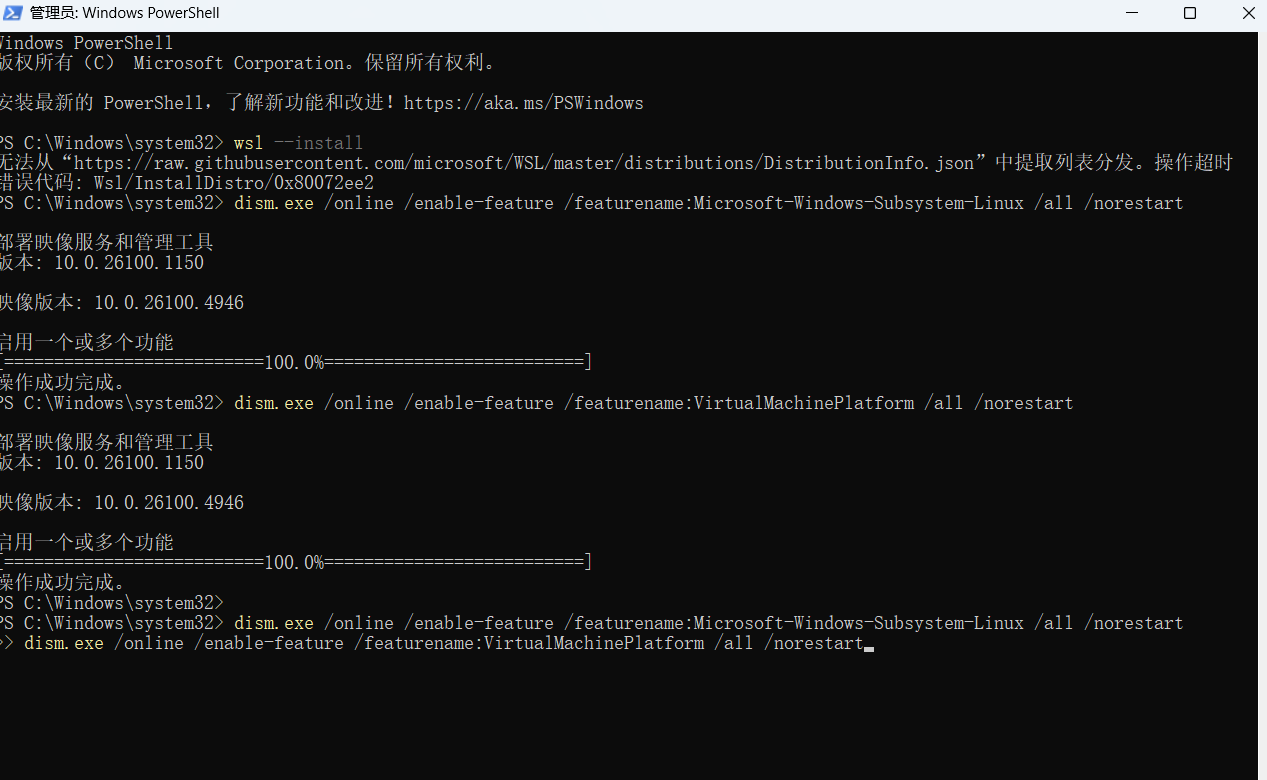
成功启用Windows功能,但是下载并安装Linux系统这一步遇到了网络连接超时错误
可以尝试手动安装
下载 Linux 内核更新包(必需步骤):
访问微软官方 WSL 文档的下载页:https://aka.ms/wsl2kernel
找到并下载 WSL2 Linux 内核更新包(例如:wsl_update_x64.msi)。
下载后,双击运行安装它。
手动下载并安装 Ubuntu 系统:
打开 Microsoft Store (微软应用商店)。
在搜索框中搜索 Ubuntu。
安装完成后,从开始菜单打开刚刚安装的 Ubuntu 应用。
系统会要求你等待几分钟进行初始解压,然后为你创建一个新的用户名和密码(这个用户名和密码是 WSL Linux 子系统内部的,用于 sudo 命令,可以与你的 Windows 账户密码不同)。
如何验证安装成功?
安装完成后,重新打开一个普通的 PowerShell 或命令提示符窗口(不需要管理员身份),输入命令:
powershell
wsl -l -v
如果成功,你会看到类似下面的输出,表明 Ubuntu 正在运行,并且版本是 WSL 2:
text
NAME STATE VERSION
- Ubuntu Running 2
请直接运行:
bash
sudo apt update
sudo apt install openjdk-11-jdk -y
会出现这个图像
下载 Hadoop
现在我们可以下载 Hadoop 了。请回到用户主目录,然后使用 wget 命令下载(以 3.3.6 版本为例):
bash
cd ~
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
3. 解压并移动到合适的位置
bash
tar -xzvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 /usr/local/hadoop
4. 设置环境变量
接下来需要配置环境变量,让系统知道 Hadoop 的位置。编辑 ~/.bashrc 文件:
bash
nano ~/.bashrc
在文件的最后,添加以下内容(如果不会用 nano 编辑器,可以搜索一下基本用法:Ctrl+X 退出,按 Y 确认保存,回车确认文件名):
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后让配置生效:
bash
source ~/.bashrc
配置 Hadoop 本身
这是最复杂的一步,我们需要修改几个 Hadoop 的配置文件。所有配置文件都位于 /usr/local/hadoop/etc/hadoop/ 目录下。
4.1 配置 core-site.xml
这个文件指定 HDFS 的默认访问地址和临时目录。
bash
nano $HADOOP_HOME/etc/hadoop/core-site.xml
将
xml
4.2 配置 hdfs-site.xml
这个文件指定 HDFS 的副本数量(单机模式设为1)。
bash
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
替换为:
xml
4.3 配置 mapred-site.xml
这个文件指定 MapReduce 运行在 YARN 框架上。
bash
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
替换为:
xml
4.4 配置 yarn-site.xml
这个文件配置 YARN 资源管理器。
bash
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
替换为:
xml
免密登录
设置 SSH 免密登录
Hadoop 的启动脚本需要通过 SSH 连接到本地机器来启动各种守护进程(如 DataNode, NodeManager)。设置免密登录后,脚本就不需要手动输入密码了。
安装 SSH 客户端和服务器:
bash
sudo apt install openssh-client openssh-server -y
生成 SSH 密钥对(一直按回车即可,所有提示都使用默认值):
bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
将公钥授权给本机:
bash
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改授权文件权限(这是一个安全要求):
bash
chmod 0600 ~/.ssh/authorized_keys
测试 SSH 免密登录是否成功:
bash
ssh localhost
格式化 HDFS NameNode
注意:这是第一次安装时必须执行的操作,且只能做一次!它会清除所有已有的 HDFS 数据。
这相当于初始化 Hadoop 的文件系统。
bash
hdfs namenode -format
您会看到大量日志输出。如果格式化成功,最后几行通常会出现 Storage directory ... has been successfully formatted 之类的信息。
启动 Hadoop 集群
现在,一切准备就绪,可以启动 Hadoop 了!
启动 HDFS(包含 NameNode, DataNode, SecondaryNameNode):
bash
start-dfs.sh
启动 YARN(包含 ResourceManager, NodeManager):
bash
start-yarn.sh
使用 jps 命令验证所有进程是否都已启动:
bash
jps
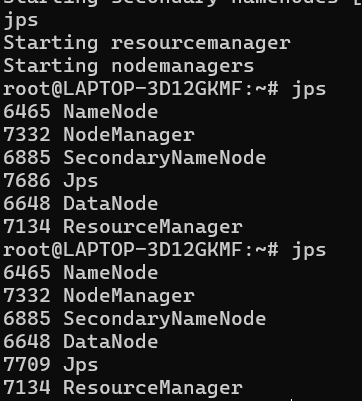
如果启动成功,您应该能看到类似以下的 6个 关键进程(顺序可能不同):
text
1234 NameNode
5678 DataNode
9012 SecondaryNameNode
3456 ResourceManager
7890 NodeManager
1112 Jps
Jps 进程本身是用来查看Java进程的工具,可以忽略。只要前5个都在,就说明集群启动成功了!
可能出现问题
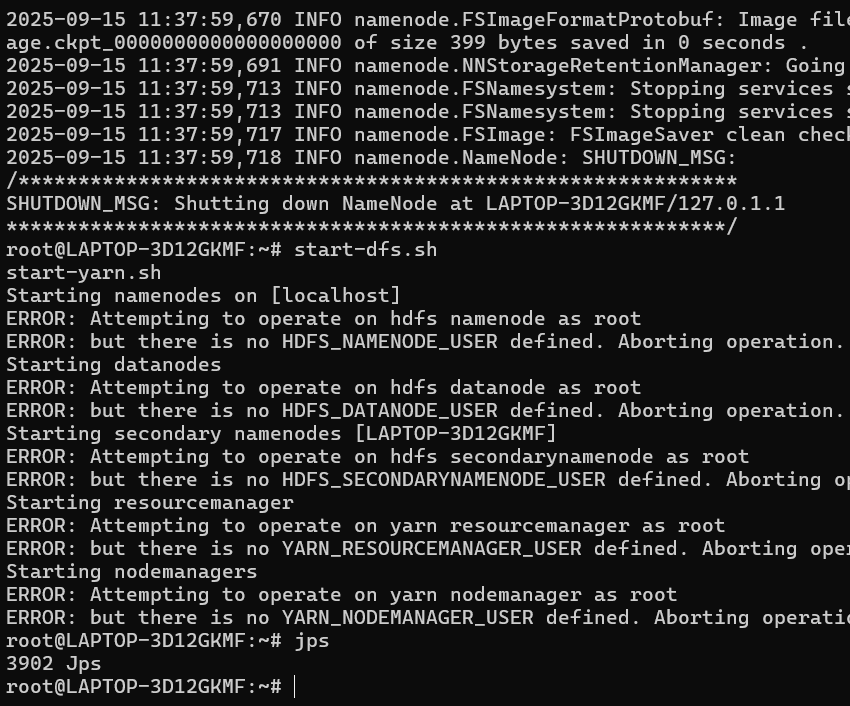
Hadoop 从 3.x 版本开始,出于安全考虑,不允许直接使用 root 用户来启动和管理服务。
错误信息非常明确:
text
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
我们需要在环境变量中明确指定运行 Hadoop 服务的用户。
解决方案:配置 Hadoop 用户环境变量
请按照以下步骤操作:
编辑 ~/.bashrc 文件,添加必要的用户环境变量:
bash
nano ~/.bashrc
在文件的最末尾,添加以下配置行(这些变量会告诉 Hadoop 脚本使用哪个用户来启动服务):
bash
Hadoop User Definitions (Required for Hadoop 3.x+)
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
由于我们就是在 root 用户下操作的,所以这里都设置为 "root"。
保存并退出 nano 编辑器 (Ctrl+X -> Y -> Enter)。
让新的环境配置立即生效:
bash
source ~/.bashrc
现在,重新启动 Hadoop 集群:
bash
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh
再次使用 jps 命令验证进程是否都已成功启动:
bash
jps
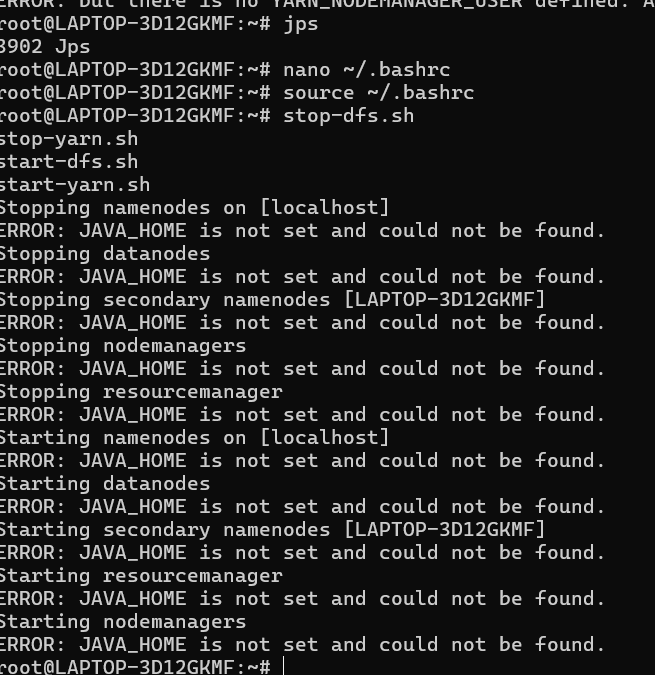
看到这个错误 ERROR: JAVA_HOME is not set and could not be found.,这表明 Hadoop 启动脚本无法找到 Java 安装路径。虽然您之前可能已经设置了 JAVA_HOME,但可能设置不正确或者没有生效。
让我们一步步解决这个问题:
解决方案:正确设置 JAVA_HOME
- 首先,确认 Java 确实已安装并找到其准确路径
bash
update-alternatives --config java
或者
bash
which java
执行这些命令后,您会看到 Java 的安装路径,例如:
text
/usr/lib/jvm/java-11-openjdk-amd64/bin/java
请记下这个路径(去掉末尾的 /bin/java),例如:/usr/lib/jvm/java-11-openjdk-amd64
- 编辑 Hadoop 的环境配置文件
Hadoop 有自己的环境配置文件,我们需要在其中设置 JAVA_HOME:
bash
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
在这个文件中,找到 export JAVA_HOME= 这一行(大约在第54行左右),取消注释并将路径设置为您刚才找到的 Java 路径:
bash
将原本的行修改为:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
请确保将路径替换为您实际找到的 Java 安装路径。
保存并退出编辑器(Ctrl+X → Y → Enter)。
- 同时确保 ~/.bashrc 中的 JAVA_HOME 也正确设置
bash
nano ~/.bashrc
检查 JAVA_HOME 的设置是否正确,应该与上面设置的路径一致。
然后让配置生效:
bash
source ~/.bashrc
4. 验证 JAVA_HOME 设置
bash
echo $JAVA_HOME
应该输出您设置的 Java 路径。
- 现在重新启动 Hadoop
bash
stop-all.sh
start-dfs.sh
start-yarn.sh - 检查进程是否正常运行
bash
jps
出现下面的图像HADOOP就算完成了
![image]()
下载HBASE
1.在Ubuntu 终端中执行:
bash
cd ~
以 HBase 2.4.18 为例(请检查官网是否有更新版本)
wget https://downloads.apache.org/hbase/2.4.18/hbase-2.4.18-bin.tar.gz
1.2 解压和安装
bash
解压
tar -xzvf hbase-2.4.18-bin.tar.gz
移动到合适位置并重命名
sudo mv hbase-2.4.18 /usr/local/hbase
1.3 设置环境变量
编辑 ~/.bashrc 文件:
bash
nano ~/.bashrc
在文件末尾添加:
bash
HBase Configuration
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
使配置生效:
bash
source ~/.bashrc
第 2 步:配置 HBase
2.1 配置 hbase-site.xml
这是 HBase 的主要配置文件:
bash
nano $HBASE_HOME/conf/hbase-site.xml
将以下配置替换文件内容(确保 Hadoop 正在运行):
xml
bash
nano $HBASE_HOME/conf/hbase-env.sh
找到并设置 JAVA_HOME:
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
第 3 步:启动和测试 HBase
3.1 确保 Hadoop 正在运行
bash
jps
您应该看到 NameNode、DataNode、ResourceManager 等进程。
3.2 启动 HBase
bash
start-hbase.sh
3.3 验证 HBase 进程
bash
jps
您现在应该看到额外的 HBase 进程:
HMaster - HBase 主节点
HRegionServer - HBase 区域服务器
3.4 启动 HBase Shell 进行测试
bash
hbase shell
进入 HBase 交互式命令行界面,提示符变为 hbase(main):001:0>。就算成功了