 RAG系统评估听起来高深,其实跟我们生活中的'尝鲜评测'没啥两样!本文用轻松幽默的方式,带你从检索质量、生成质量到用户体验,全方位掌握如何科学评测RAG系统,避免踩坑,让你的AI应用又快又准。#RAG技术 #AI评估 #信息检索 #大模型 #数据科学
RAG系统评估听起来高深,其实跟我们生活中的'尝鲜评测'没啥两样!本文用轻松幽默的方式,带你从检索质量、生成质量到用户体验,全方位掌握如何科学评测RAG系统,避免踩坑,让你的AI应用又快又准。#RAG技术 #AI评估 #信息检索 #大模型 #数据科学你是不是经常被这些问题困扰:
"我搭的RAG系统,到底靠不靠谱?"
"花了大价钱部署的RAG应用,效果怎么还不如直接问ChatGPT?"
"为啥有时候回答超准,有时候却离谱到天际线?"
别担心,今天我们就要聊聊如何给RAG系统打分,就像我们平时给外卖评星一样简单!
RAG评测:从"感觉良好"到"有理有据"
先来个小场景:小王刚刚搭建了一个公司内部文档问答系统,同事们反馈"感觉挺好用的",但是CEO突然问他:"这系统到底比原来的搜索好在哪?能不能量化?"
小王:😰...
这不就是我们的日常吗?所以今天我们就要从"感觉良好"升级到"有理有据"的评估体系!
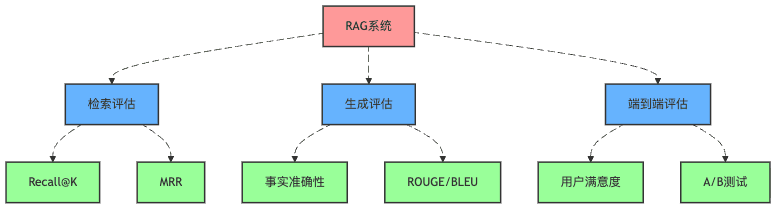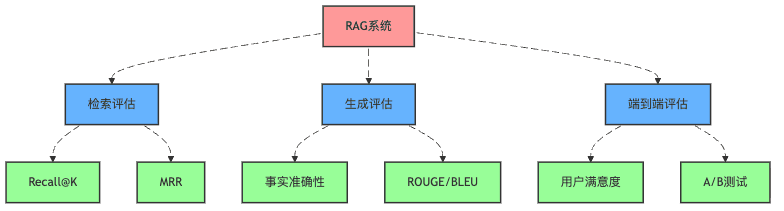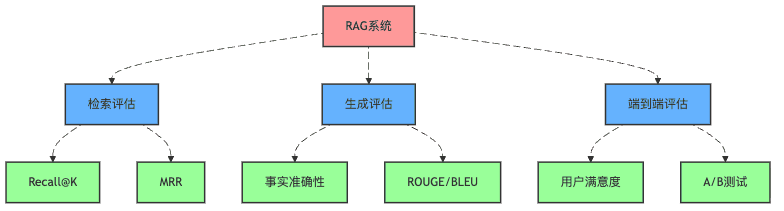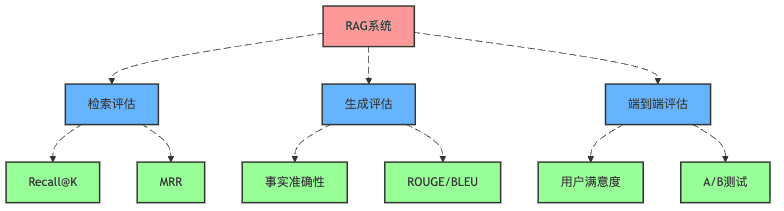
检索质量评估:从"大海捞针"到"一针见血"
检索评估那些事儿
想象你在图书馆找一本关于"如何训练猫咪使用马桶"的书:
- 方式A:你问图书管理员,他给了你50本书,说"应该在里面"
- 方式B:管理员直接带你到准确位置,第一本就是你要的
这就是RAG检索质量的差别!而衡量这种差别的指标主要有:
Recall@K:就像赶场相亲,相中的那个人在前K个候选里的概率。
"哎呀妈,你给我安排的10个相亲对象里,居然没一个是学计算机的!"
这就是Recall@K等于0的惨案,你要找的信息压根不在检索结果里!
MRR (Mean Reciprocal Rank):第一个正确答案出现的位置的倒数平均值。
假设你在某宝搜"程序员加班神器",如果第一个就是"黑咖啡",那MRR=1;
如果第二个才是,那MRR=1/2=0.5;
如果第十个才是,那MRR=1/10=0.1。MRR越高,说明系统越能把正确答案放前面!
NDCG:考虑了相关性程度和排名位置的指标。
就像点外卖,不光看有没有你想吃的菜,还要看好评的店是不是排在前面。
如果五星餐厅被排在第10页,而三星餐厅排在首页,这就是NDCG不高的表现!
生成质量评估:从"狗屁不通"到"如数家珍"
AI回答也要打分
你有没有过这样的体验,RAG系统明明检索到了正确的内容,但生成的回答却像是被猫踩过的键盘?
评价生成质量,主要看这几点:
事实准确性:AI说的是不是真的。
这就像你男朋友给你讲他前任的故事,你总得找个知情人核实一下,对不对?
BLEU/ROUGE:衡量生成文本与标准答案的相似度。
想象你小时候背诵课文,老师会看你背得有多准确。
BLEU/ROUGE就像是AI的"背诵评分",看它是不是把知识点都覆盖到了。

BERTScore:更注重语义相似性而非字面相似性。
这就像你跟朋友讲同一个笑话,表达不同但笑点一样,依然是好笑话!
BERTScore就是看AI回答的"神韵"对不对,而不只是字字相符。
端到端评估:用户才是最终裁判
从技术指标到用户体验
技术指标再好,用户不买单也是白搭。所以我们还需要端到端评估:
响应时间:系统响应速度。
就像你问路,对方思考了半小时才告诉你"往前走",
信息再准确,你可能也已经自己找到了...
端到端准确率:整体回答正确率。
这就像你点的外卖,不管餐厅、骑手、包装环节谁出了问题,
最终送到你手上的食物凉了或者洒了,这单体验就是失败的。
实战案例:小李的客服机器人评测记
小李最近在电商公司部署了一个基于RAG的客服机器人,上线前他是这样评测的:
-
检索质量测试:
准备了100个常见问题,看机器人能否找到对应的产品手册和政策文档。
结果发现Recall@5只有75%,意味着1/4的问题找不到正确资料! -
生成质量测试:
对成功检索的75个问题,生成回答与标准答案的ROUGE-L平均只有0.6,
就像教科书上的知识点只答对了60%... -
A/B测试:
找了50名真实客户,一半使用新机器人,一半使用旧系统。
结果用户满意度只提升了5%,远低于预期的20%!
通过这些评估,小李发现了问题所在:

最终,小李针对性地进行了三方面优化:
- 建立知识库自动更新机制,提高了检索覆盖率
- 改进提示词,让回答更全面和客户友好
- 升级服务器配置,将响应时间从5秒缩短到2秒
一个月后,小李的系统满意度提升了25%,超过了目标!
实用建议:别让评估变成"形式主义"
许多人做RAG评估时会陷入几个常见误区:
误区一:只看技术指标,忽视业务价值
这就像你的对象长得帅身材好性格佳,但从不给你买奶茶...
各项指标都优秀,但解决不了你的实际需求,有什么用?
误区二:一次性评估,缺乏持续监控
就像你减肥,测了一次体重发现瘦了2斤就开始疯狂吃火锅...
RAG系统也需要持续监控,因为数据和问题都在变化!
误区三:样本偏差,不代表真实场景
就像相亲照片P得很好看,但见面发现是照骗...
测试样本要足够多样化,才能反映真实使用情况!
给我的RAG应用做体检:实用清单
如果你正准备给自己的RAG系统做评估,这里有一份简易清单:
-
检索评估:
- 准备100个典型问题和标准答案
- 计算Recall@3, Recall@5, MRR
- 目标:Recall@5 > 85%, MRR > 0.7
-
生成评估:
- 使用自动指标:ROUGE-L > 0.7
- 人工评估:事实准确率 > 95%
- 幻觉检测:错误事实比例 < 3%
-
端到端评估:
- 响应时间 < 3秒
- 用户满意度提升 > 15%
- A/B测试样本量 > 200
记住,评估不是为了评估而评估,而是为了发现问题、持续改进!
总结:优秀的RAG系统是"考"出来的
好了,现在你已经掌握了如何给RAG系统进行全方位的科学评估。记住,这不是一次性的工作,而是持续优化的过程。
想想我们日常使用的搜索引擎,它们可是经过了几十年、数不清的评估和优化才达到今天的水平。你的RAG系统也需要这样不断"迭代进化"!
最后,送你一句话:
"没有评估的RAG,就像没有体检的身体,看起来健康,隐患却可能不少;
科学评估的RAG,才能真正做到'有问必答,答必精准'!"
现在,去给你的RAG系统安排一次全面体检吧!