1. TensorCore 简介:
- 硬件层面支持半精度浮点矩阵乘法,与昇腾NPU的 cube 核类似,最小只能计算规定尺寸的矩阵乘法。
- wmma API 封装在 nvcuda 命名空间
2. naive :
- 一个block 1 个warp,wmmaTile 16*16
点击查看代码
//naive 一个block 一个warp,一个线程处理一个数据
template <const uint32_t WMMA_M=16,const uint32_t WMMA_N=16,const uint32_t WMMA_K=16>
__global__ void hgemm_wmma_m16n16k16_naive_kernel(half *A,half *B,half *C, int M,int N,int K)
{const uint32_t aStartRow = blockIdx.y * WMMA_M;const uint32_t bStartCol = blockIdx.x * WMMA_N;if(aStartRow >= M || bStartCol >= N)return;//定义 CFrag wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,half> cFrag;wmma::fill_fragment(cFrag,0.0);//定义 AFrag BFragwmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> aFrag;wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> bFrag;//K 方向循环#pragma unrollfor(int k=0;k<div_ceil(K,WMMA_K);k++){//加载数据 主序参数 K Nwmma::load_matrix_sync(aFrag, A + aStartRow*K + k*WMMA_K,K);wmma::load_matrix_sync(bFrag, B + k*WMMA_K*N + bStartCol,N);//计算 cFrag 支持原地操作wmma::mma_sync(cFrag,aFrag,bFrag,cFrag);}//回写结果 主序参数 Nwmma::store_matrix_sync(C + aStartRow*N + bStartCol,cFrag,N,wmma::mem_row_major);}
3. 优化一:
- 一个block 有 4 * 2 个warp
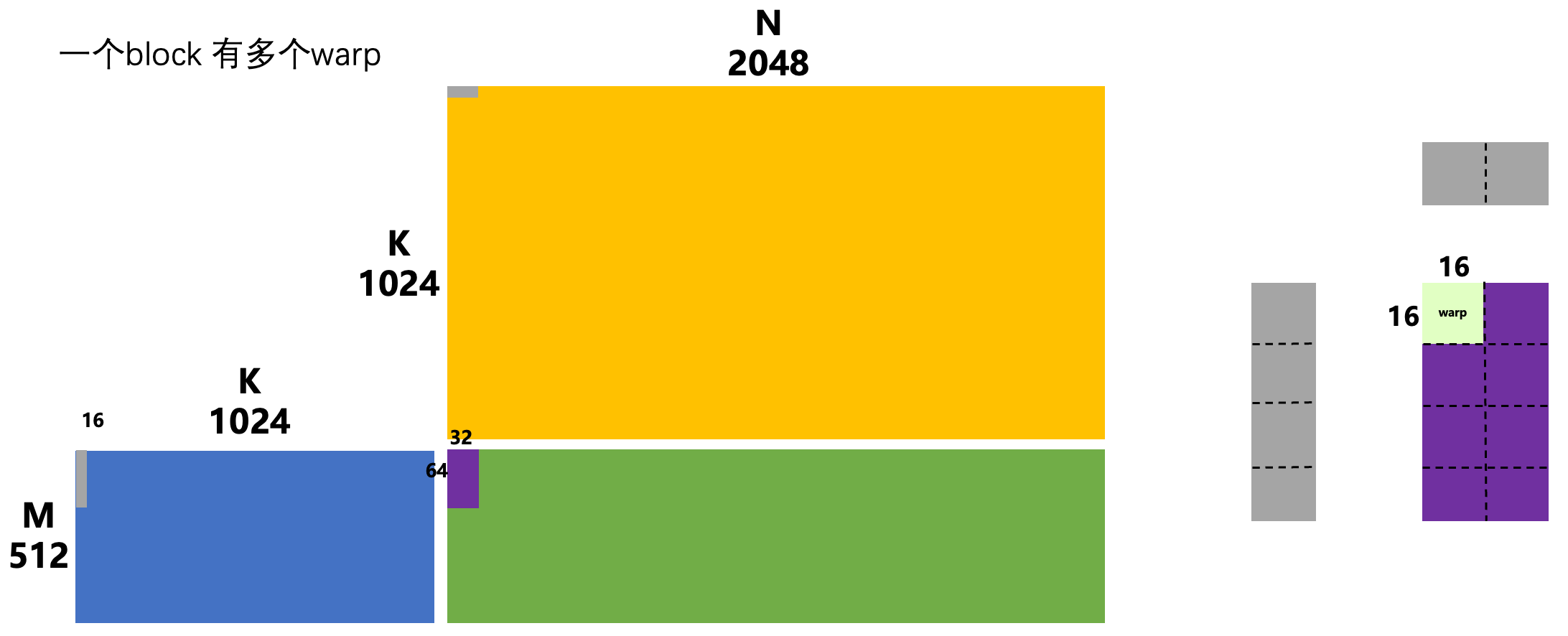
点击查看代码
//优化一:共享内存 + warpOfBlocksize(2,4): 一个block 有更多 warp,K 方向步长 WMMA_K
template<const uint32_t WMMA_M=16,const uint32_t WMMA_N=16,const uint32_t WMMA_K=16,const uint32_t BXNum=2,const uint32_t BYNum=4>
__global__ void hgemm_wmma_m16n16k16_block2x4_kernel(half *A,half *B,half *C, int M,int N,int K)
{//block内iduint32_t bid = threadIdx.y * blockDim.x + threadIdx.x;//线程计算结果归属于哪个 warpOfblock//warp shape (2,4) x 方向维度为2,y 方向维度为4/*warp0 | warp1warp2 | warp3warp4 | warp6warp6 | warp7*/uint32_t warpY = bid/(32*BXNum);uint32_t warpX = (bid/32)%2;// 共享内存,存放 K 方向一个步长内需要的数据__shared__ half sharedA[WMMA_M*BYNum][WMMA_K];__shared__ half sharedB[WMMA_K][WMMA_N*BXNum];//每个线程取数据个数//A uint32_t nFetchANum = WMMA_M*BYNum*WMMA_K/(blockDim.y*blockDim.x); //4 half4/float2//Buint32_t nFetchBNum = WMMA_K*WMMA_N*BXNum/(blockDim.y*blockDim.x); //2 half2//计算一个步长内取数据到共享内存的线程坐标//A 一行需要 4个线程 uint32_t threadsPerRowA = WMMA_K/nFetchANum;//在一个步长内取A数据的线程排布的坐标uint32_t threadRowA = bid/threadsPerRowA;uint32_t threadColA = bid%threadsPerRowA;//B 一行需要 16个线程uint32_t threadsPerRowB = WMMA_N*BXNum/nFetchBNum;//在一个步长内取B数据的线程排布的坐标uint32_t threadRowB = bid/threadsPerRowB;uint32_t threadColB = bid%threadsPerRowB;//定义wmma 计算对象wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,half> CFrag;wmma::fill_fragment(CFrag,0.0);wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> AFrag;wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> BFrag;// #pragma unrollfor(int k=0;k<K;k+=WMMA_K){//取数据到共享内存//易错点 blockSize(32,8)CAST_HALF4(&sharedA[threadRowA][threadColA*nFetchANum])[0] = CAST_HALF4(A + (blockIdx.y*WMMA_M*BYNum+threadRowA)*K + (k+threadColA*nFetchANum))[0];CAST_HALF2(&sharedB[threadRowB][threadColB*nFetchBNum])[0] = CAST_HALF2(B + (k+threadRowB)*N + blockIdx.x*WMMA_N*BXNum + threadColB*nFetchBNum)[0];__syncthreads();//wmma 计算;ldm 是指共享内存的主序参数wmma::load_matrix_sync(AFrag,&sharedA[warpY*WMMA_M][0],WMMA_K);wmma::load_matrix_sync(BFrag,&sharedB[0][warpX*WMMA_N],WMMA_N*BXNum);wmma::mma_sync(CFrag,AFrag,BFrag,CFrag);__syncthreads();}//储存结果uint32_t rowStore = (blockIdx.y *BYNum + warpY) * WMMA_M;uint32_t colStore = (blockIdx.x *BXNum + warpX) * WMMA_N;//ldm 源数据的主序参数wmma::store_matrix_sync(C + rowStore*N + colStore,CFrag,N,wmma::mem_row_major);
}
4. 优化二:
- 一个 warp 计算 2 * 4 个 warp 的数据

点击查看代码
//优化二:共享内存 + warpOfBlocksize(2,4): 一个warp 处理的数据为 2*4=8个warp的数据,K 方向步长 WMMA_K
// block 中 warpShape(2,4),一个warp 处理的8个warp数据维度 (4,2),一个block 处理 128*128的数据
//一份共享内存的数据计算多个位置的结果。
template<const uint32_t WMMA_M=16,const uint32_t WMMA_N=16,const uint32_t WMMA_K=16,
const uint32_t BXNum=2,const uint32_t BYNum=4,const uint32_t WarpXNum=4,const uint32_t WarpYNum =2>
__global__ void hgemm_wmma_m16n16k16_block2x4_wmma4x2_kernel(half *A,half *B,half *C, int M,int N,int K)
{//block内iduint32_t bid = threadIdx.y * blockDim.x + threadIdx.x;//线程计算结果归属于哪个 warpOfblock//warp shape (2,4) x 方向维度为2,y 方向维度为4/*warp0 | warp1warp2 | warp3warp4 | warp6warp6 | warp7*/uint32_t warpY = bid/(32*BXNum);uint32_t warpX = (bid/32)%2;//一个block 计算结果的大小const uint32_t BM = BYNum*WarpYNum*WMMA_M;const uint32_t BN = BXNum*WarpXNum*WMMA_N;const uint32_t BK = WMMA_K;// 共享内存,存放 K 方向一个步长内需要的数据__shared__ half sharedA[BM][BK];__shared__ half sharedB[BK][BN];//每个线程取数据个数//A uint32_t nFetchANum = BM*BK/(blockDim.y*blockDim.x); //8 一个float4//Buint32_t nFetchBNum = BK*BN/(blockDim.y*blockDim.x); //8 一个float4//计算一个步长内取数据到共享内存的线程排布坐标//A 一行需要 2个线程 uint32_t threadsPerRowA = BK/nFetchANum;//在一个步长内取A数据的线程排布的坐标uint32_t threadRowA = bid/threadsPerRowA;uint32_t threadColA = bid%threadsPerRowA;//B 一行需要 16个线程uint32_t threadsPerRowB = BN/nFetchBNum;//在一个步长内取B数据的线程排布的坐标uint32_t threadRowB = bid/threadsPerRowB;uint32_t threadColB = bid%threadsPerRowB;//定义wmma 计算对象wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,half> CFrag[WarpYNum][WarpXNum];for(int i=0;i<WarpYNum;i++){for(int j=0;j<WarpXNum;j++)wmma::fill_fragment(CFrag[i][j],0.0);}wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> AFrag[WarpYNum];wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> BFrag[WarpXNum];// #pragma unrollfor(int k=0;k<K;k+=WMMA_K){//取数据到共享内存CAST_FLOAT4(&sharedA[threadRowA][threadColA*nFetchANum])[0] = CAST_FLOAT4(A + (blockIdx.y*BM+threadRowA)*K + (k+threadColA*nFetchANum))[0];CAST_FLOAT4(&sharedB[threadRowB][threadColB*nFetchBNum])[0] = CAST_FLOAT4(B + (k+threadRowB)*N + blockIdx.x*BN + threadColB*nFetchBNum)[0];__syncthreads();//sharedA Y 方向 8个//根据该warp 计算结果所在位置,从共享内存取数据进行遍历for(int i=0;i<WarpYNum;i++){ wmma::load_matrix_sync(AFrag[i],&sharedA[(warpY*WarpYNum +i) * WMMA_M][0],BK);for(int j=0;j<WarpXNum;j++){wmma::load_matrix_sync(BFrag[j],&sharedB[0][(warpX*WarpXNum + j)*WMMA_N],BN);wmma::mma_sync(CFrag[i][j],AFrag[i],BFrag[j],CFrag[i][j]);}} __syncthreads();}//储存结果for(int i=0;i<WarpYNum;i++){for(int j=0;j<WarpXNum;j++){uint32_t rowStore = (blockIdx.y * BYNum * WarpYNum + warpY*WarpYNum + i) * WMMA_M;uint32_t colStore = (blockIdx.x * BXNum * WarpXNum + warpX*WarpXNum + j) * WMMA_N;//ldm 源数据的主序参数wmma::store_matrix_sync(C + rowStore*N + colStore,CFrag[i][j],N,wmma::mem_row_major);}}
}
5. 优化三:
- 使用 doubleBuffer 和 PTX 指令异步拷贝数据到共享内存
点击查看代码
//优化三:共享内存 + warpOfBlocksize(2,4): 一个warp 处理的数据为 2*4=8个warp的数据,K 方向步长 WMMA_K
// block 中 warpShape(2,4),一个warp 处理的8个warp数据维度 (4,2),一个block 处理 128*128的数据
//一份共享内存的数据计算多个位置的结果。
// double buffer + 内嵌PTX指令,一个block内的逻辑 warp 间异步拷贝数据到共享内存
template<const uint32_t WMMA_M=16,const uint32_t WMMA_N=16,const uint32_t WMMA_K=16,
const uint32_t BXNum=2,const uint32_t BYNum=4,const uint32_t WarpXNum=4,const uint32_t WarpYNum =2,const uint32_t OFFFSET=0>
__global__ void hgemm_wmma_m16n16k16_block2x4_wmma4x2_dBuff_async_kernel(half *A,half *B,half *C, int M,int N,int K)
{//block内iduint32_t bid = threadIdx.y * blockDim.x + threadIdx.x;//线程计算结果归属于哪个 warpOfblock//warp shape (2,4) x 方向维度为2,y 方向维度为4/*warp0 | warp1warp2 | warp3warp4 | warp6warp6 | warp7*/uint32_t warpY = bid/(32*BXNum);uint32_t warpX = (bid/32)%2;//一个block 计算结果的大小const uint32_t BM = BYNum*WarpYNum*WMMA_M;const uint32_t BN = BXNum*WarpXNum*WMMA_N;const uint32_t BK = WMMA_K;// 共享内存,存放 K 方向一个步长内需要的数据__shared__ half sharedA[2][BM][BK+OFFFSET];__shared__ half sharedB[2][BK][BN+OFFFSET];//每个线程取数据个数//A uint32_t nFetchANum = BM*BK/(blockDim.y*blockDim.x); //8 一个float4//Buint32_t nFetchBNum = BK*BN/(blockDim.y*blockDim.x); //8 一个float4//计算一个步长内取数据到共享内存的线程排布坐标//A 一行需要 2个线程 uint32_t threadsPerRowA = BK/nFetchANum;//在一个步长内取A数据的线程排布的坐标uint32_t threadRowA = bid/threadsPerRowA;uint32_t threadColA = bid%threadsPerRowA;//B 一行需要 16个线程uint32_t threadsPerRowB = BN/nFetchBNum;//在一个步长内取B数据的线程排布的坐标uint32_t threadRowB = bid/threadsPerRowB;uint32_t threadColB = bid%threadsPerRowB;//预取第一轮共享内存数据uint32_t writeFlag = 0;uint32_t readFlag = 1- writeFlag;//获取共享内存地址偏移量uint32_t cp_Offset_A = __cvta_generic_to_shared(&sharedA[writeFlag][threadRowA][threadColA*nFetchANum]);uint32_t cp_Offset_B = __cvta_generic_to_shared(&sharedB[writeFlag][threadRowB][threadColB*nFetchBNum]);//dst src bytesCP_ASYNC_CG(cp_Offset_A, A + (blockIdx.y*BM+threadRowA)*K + threadColA*nFetchANum,16);CP_ASYNC_CG(cp_Offset_B, B + threadRowB*N + blockIdx.x*BN + threadColB*nFetchBNum,16);//提交异步任务到任务队列CP_ASYNC_COMMIT_GROUP();// 同步阻塞等待数据拷贝完成CP_ASYNC_WAIT_GROUP(0);__syncthreads();//定义wmma 计算对象wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,half> CFrag[WarpYNum][WarpXNum];for(int i=0;i<WarpYNum;i++){for(int j=0;j<WarpXNum;j++)wmma::fill_fragment(CFrag[i][j],0.0);}wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> AFrag[WarpYNum];wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> BFrag[WarpXNum];// #pragma unrollfor(int k=WMMA_K;k<K;k+=WMMA_K){// 修改共享内存读写标志位writeFlag = 1 - writeFlag;readFlag = 1 - writeFlag;//提交任务:下个循环数据拷贝到共享内存cp_Offset_A = __cvta_generic_to_shared(&sharedA[writeFlag][threadRowA][threadColA*nFetchANum]);cp_Offset_B = __cvta_generic_to_shared(&sharedB[writeFlag][threadRowB][threadColB*nFetchBNum]);//dst src bytesCP_ASYNC_CG(cp_Offset_A, A + (blockIdx.y*BM+threadRowA)*K + k+threadColA*nFetchANum,16);CP_ASYNC_CG(cp_Offset_B, B + (k+threadRowB)*N + blockIdx.x*BN + threadColB*nFetchBNum,16);//提交异步任务到任务队列CP_ASYNC_COMMIT_GROUP();//sharedA Y 方向 8个//根据该warp 计算结果所在位置,从共享内存取数据进行遍历for(int i=0;i<WarpYNum;i++){ wmma::load_matrix_sync(AFrag[i],&sharedA[readFlag][(warpY*WarpYNum +i) * WMMA_M][0],BK+OFFFSET);for(int j=0;j<WarpXNum;j++){wmma::load_matrix_sync(BFrag[j],&sharedB[readFlag][0][(warpX*WarpXNum + j)*WMMA_N],BN+OFFFSET);wmma::mma_sync(CFrag[i][j],AFrag[i],BFrag[j],CFrag[i][j]);}}// 同步阻塞等待数据拷贝完成CP_ASYNC_WAIT_GROUP(0);// 块共享内存同步__syncthreads();}// 修改共享内存读写标志位writeFlag = 1 - writeFlag;readFlag = 1 - writeFlag;//计算最后一个步长for(int i=0;i<WarpYNum;i++){ wmma::load_matrix_sync(AFrag[i],&sharedA[readFlag][(warpY*WarpYNum +i) * WMMA_M][0],BK+OFFFSET);for(int j=0;j<WarpXNum;j++){wmma::load_matrix_sync(BFrag[j],&sharedB[readFlag][0][(warpX*WarpXNum + j)*WMMA_N],BN+OFFFSET);wmma::mma_sync(CFrag[i][j],AFrag[i],BFrag[j],CFrag[i][j]);}}//储存结果for(int i=0;i<WarpYNum;i++){for(int j=0;j<WarpXNum;j++){uint32_t rowStore = (blockIdx.y * BYNum * WarpYNum + warpY*WarpYNum + i) * WMMA_M;uint32_t colStore = (blockIdx.x * BXNum * WarpXNum + warpX*WarpXNum + j) * WMMA_N;//ldm 源数据的主序参数wmma::store_matrix_sync(C + rowStore*N + colStore,CFrag[i][j],N,wmma::mem_row_major);}}
}
6. 调用代码
点击查看代码
#include <cuda_runtime.h>#include "common/tester.h"
#include "common/common.h"//没有 half4 用 float2 替代
#define CAST_HALF4(point) (reinterpret_cast<float2*>(point))
#define CAST_HALF2(point) (reinterpret_cast<half2*>(point))
#define CAST_FLOAT4(point) (reinterpret_cast<float4*>(point))using namespace nvcuda;void hgemm_wmma_m16n16k16_naive(half *A,half *B,half *C, int M,int N,int K)
{// 设置 warp 处理数据 shapeconst uint32_t WMMA_M = 16; const uint32_t WMMA_N = 16;const uint32_t WMMA_K = 16;dim3 blockSize(32);dim3 gridSize(div_ceil(N,WMMA_N),div_ceil(M,WMMA_M));hgemm_wmma_m16n16k16_naive_kernel<WMMA_M,WMMA_N,WMMA_K><<<gridSize,blockSize>>>(A,B,C,M,N,K);
}void hgemm_wmma_m16n16k16_block2x4(half *A,half *B,half *C, int M,int N,int K)
{// 设置 warp 处理数据 shapeconst uint32_t WMMA_M = 16; const uint32_t WMMA_N = 16;const uint32_t WMMA_K = 16;const uint32_t nBxNum = 2;const uint32_t nByNum = 4;// 计算warpOfBlcok(2,4) 计算结果64*32dim3 blockSize(8,32); dim3 gridSize(div_ceil(N,WMMA_N*nBxNum),div_ceil(M,WMMA_M*nByNum));hgemm_wmma_m16n16k16_block2x4_kernel<WMMA_M,WMMA_N,WMMA_K,nBxNum,nByNum><<<gridSize,blockSize>>>(A,B,C,M,N,K);
}void hgemm_wmma_m16n16k16_block2x4_wmma4x2(half *A,half *B,half *C, int M,int N,int K)
{// 设置 warp 处理数据 shapeconst uint32_t WMMA_M = 16; const uint32_t WMMA_N = 16;const uint32_t WMMA_K = 16;const uint32_t nBxNum = 2;const uint32_t nByNum = 4;const uint32_t nWarpXNum = 4;const uint32_t nWarpYNum = 2;// 计算warpOfBlcok(2,4) 计算结果 128*128dim3 blockSize(8,32); dim3 gridSize(div_ceil(N,WMMA_N*nBxNum*nWarpXNum),div_ceil(M,WMMA_M*nByNum*nWarpYNum));hgemm_wmma_m16n16k16_block2x4_wmma4x2_kernel<WMMA_M,WMMA_N,WMMA_K,nBxNum,nByNum,nWarpXNum,nWarpYNum><<<gridSize,blockSize>>>(A,B,C,M,N,K);
}void hgemm_wmma_m16n16k16_block2x4_wmma4x2_dBuff_async(half *A,half *B,half *C, int M,int N,int K)
{// 设置 warp 处理数据 shapeconst uint32_t WMMA_M = 16; const uint32_t WMMA_N = 16;const uint32_t WMMA_K = 16;const uint32_t nBxNum = 2;const uint32_t nByNum = 4;const uint32_t nWarpXNum = 4;const uint32_t nWarpYNum = 2;// 计算warpOfBlcok(2,4) 计算结果 128*128 dim3 blockSize(8,32); dim3 gridSize(div_ceil(N,WMMA_N*nBxNum*nWarpXNum),div_ceil(M,WMMA_M*nByNum*nWarpYNum));hgemm_wmma_m16n16k16_block2x4_wmma4x2_dBuff_async_kernel<WMMA_M,WMMA_N,WMMA_K,nBxNum,nByNum,nWarpXNum,nWarpYNum,8><<<gridSize,blockSize>>>(A,B,C,M,N,K);
}int main(int argc, char** argv)
{{Tester tester(512,2048,1024,1,10,100,true);tester.evaluate(hgemm_wmma_m16n16k16_naive,"hgemm_wmma_m16n16k16_naive");}{Tester tester(512,2048,1024,1,10,100,true);tester.evaluate(hgemm_wmma_m16n16k16_block2x4,"hgemm_wmma_m16n16k16_block2x4");}{Tester tester(512,2048,1024,1,10,100,true);tester.evaluate(hgemm_wmma_m16n16k16_block2x4_wmma4x2,"hgemm_wmma_m16n16k16_block2x4_wmma4x2");}{Tester tester(512,2048,1024,1,10,100,true);tester.evaluate(hgemm_wmma_m16n16k16_block2x4_wmma4x2_dBuff_async,"hgemm_wmma_m16n16k16_block2x4_wmma4x2_dBuff_async");}return 0;
}