RAG(检索增强生成)本质上就是给AI模型外挂一个知识库。平常用ChatGPT只能基于训练数据回答问题,但RAG可以让它查阅你的专有文档——不管是内部报告、技术文档还是业务资料,都能成为AI的参考资源。
很多人第一反应是用LangChain或LlamaIndex这些现成框架,确实能快速搭起来。但自己实现的核心价值在于:你能清楚知道文档是怎么被切分的、向量是怎么生成的、检索逻辑具体怎么跑的。
当系统出现检索不准确、回答质量差、成本过高这些问题时,你能精确定位到是哪个环节的问题。比如是分块策略不合适,还是embedding模型选择有问题,或者是检索参数需要调整。用框架的话,很多时候只能盲目调参数,治标不治本。
另外业务场景往往有特殊需求:PDF表格要特殊处理、某些文档类型需要提取特定元数据、检索结果要按业务规则重排序等等。自己实现就能在任何环节做针对性优化,而不是被框架的设计限制住。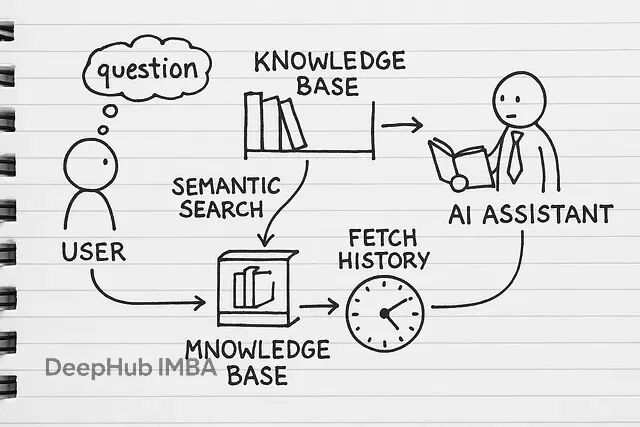
下面我们开始一步一步的进行:
https://avoid.overfit.cn/post/a9251c8e996b4c24b1b9536537b0c936