三.ubuntu22.04 使用C++部署PyTorch模型
前面一/二步骤配置好conda torch环境后,这里举例运行怎么将PyTorch模型应用到C++中,参照https://zhuanlan.zhihu.com/p/513571175 使用
这里使用libtorch, (部署到QNX平台还有使用SNPE,模型->ONNX->SNPE)
使用PyTorch的C++版本LibTorch来重写推理代码,并用JIT跟踪来得到LibTorch可以直接读取的模型参数。
- 1.安装libtorch
- 2.第一步:先用PyTorch训练一个网络
- 3.第二步:使用tracing将模型文件转化成TorchScript
- 4.第三步:使用libtorch重写推理程序
1.安装libtorch
进入官网 https://pytorch.org/get-started/locally/ 下载libtorch, 这里简便,使用的是CPU版本

下载完成后,随便丢到一个地方去解压,完成。建议linux小白将libtorch放在/usr/local/lib下,并保证libtorch文件夹下存在include这个文件夹。
测试是否安装成功:
1.创建CMakeList.txt
cmake_minimum_required(VERSION 3.5)
project(LibTorchDemo)# package
find_package(OpenCV REQUIRED)
find_package(Torch REQUIRED PATHS "/usr/local/lib/libtorch")add_executable(digit digit.cpp)
# libtorch
target_link_libraries(digit ${TORCH_LIBRARIES})
target_link_libraries(digit ${OpenCV_LIBS})
2.创建digit.cpp
#include "iostream"
#include "opencv2/opencv.hpp"
#include "torch/script.h"int main(int argc, char const *argv[])
{std::cout << "hello world!" << std::endl;return 0;
}
3.运行编译
$mkdir build
$cd build
$cmake .. && make -j8
$./digit
如果没有任何报错,说明没问题
2.第一步:先用PyTorch训练一个网络
既然我们需要将PyTorch模型使用C++部署,那么首先肯定需要一个Torch的模型。我们先使用PyTorch简单训练一个手写数字识别
创建digit.py
from sklearn.datasets import load_digits
import torch
from torch import nn
import torch.utils.data as Data
import numpy as np
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import osclass Digit(nn.Module):def __init__(self):super().__init__()self.conv = nn.Sequential(nn.Conv2d(1, 16, 3, 1, 1),nn.Tanh(),nn.Conv2d(16, 32, 3, 2, 1),nn.Tanh(),nn.Conv2d(32, 16, 3, 2, 1),nn.Tanh(),nn.Conv2d(16, 8, 3, 1, 1))self.output = nn.Linear(32, 10)def forward(self, x):out = self.conv(x)out = self.output(out.flatten(1))return outRATIO = 0.8
BATCH_SIZE = 128
EPOCH = 10if __name__ == "__main__":X, y = load_digits(return_X_y=True)X = X / 16.sample_num = len(y)X = [x.reshape(1, 8, 8).tolist() for x in X]indice = np.arange(sample_num)np.random.shuffle(indice)X = torch.FloatTensor(X)y = torch.LongTensor(y)offline = int(sample_num * RATIO)train = Data.TensorDataset(X[indice[:offline]], y[indice[:offline]])test = Data.TensorDataset(X[indice[offline:]], y[indice[offline:]])train_loader = Data.DataLoader(train, BATCH_SIZE, True)test_loader = Data.DataLoader(test, BATCH_SIZE, False)model = Digit()optimizer = torch.optim.RMSprop(model.parameters(), lr=1e-3)criterion = nn.CrossEntropyLoss(reduction="mean")test_losses = []test_accs = []for epoch in range(EPOCH):model.train()for bx, by in train_loader:out = model(bx)loss = criterion(out, by)optimizer.zero_grad()loss.backward()optimizer.step()model.eval()correct = 0total = 0test_loss = []test_acc = []for bx, by in test_loader:with torch.no_grad():out = model(bx)pre_lab = out.argmax(1)loss = criterion(out, by)test_loss.append(loss.item())test_acc.append(accuracy_score(pre_lab, by))test_losses.append(np.mean(test_loss))test_accs.append(np.mean(test_acc))plt.figure(dpi=120)plt.plot(test_losses, 'o-', label="loss")plt.plot(test_accs, 'o-', label="accuracy")plt.legend()plt.grid()plt.show()if not os.path.exists("model"):os.makedirs("model")torch.save(model.state_dict(), "model/digit.pth")
运行
python digit.py
测试集精度和损失曲线如下:

运行结束后可以得到模型文件,就在model文件夹: digit.pth
3.第二步:使用tracing将模型文件转化成TorchScript
PyTorch导出的模型文件是不能直接被libtorch读取的,因为PyTorch默认导出的后端的序列化是joblib。
PyTorch通过JIT搭建了Python和C++的桥梁,我们可以将模型转成TorchScript Module,将Python运行时的部分运行时包裹进去。
转换方法非常简单:
import torch
from digit import Digitmodel = Digit()
model.load_state_dict(torch.load("model/digit.pth", map_location="cpu"))sample = torch.randn(1, 1, 8, 8)trace_model = torch.jit.trace(model, sample)
trace_model.save("model/digit.jit")
原理大概就是模拟一个输入sample,让模型走一遍前向推理,将state_dict中的每个参数跟踪一边。因此sample只需要是一个符合输入规范的张量即可。
运行上述代码,可以在model文件夹中得到digit.jit。这个jit文件可以直接被python使用,下面我就来使用JIT跟踪的模型来进行Python端的预测,一来验证我们的JIT跟踪得到的TorchScript模型是否可以正常工作,二来比较JIT会对模型推理的加速起到多大的效果。
例子图片 保存到image/sample.png

运行下述测试代码,由于Python本身的特性和JIT的即时编译的特性,模型在同一进程生命周期内运行时前几次会比较慢,所以在测试前,需要空跑几次:
import time
import torch
import cv2 as cv
from digit import Digit
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pddef run_model(model, image):s = time.time()out = model(image)pre_lab = torch.argmax(out, dim=1)cost_time = round(time.time() - s, 5)return cost_timeimage = cv.imread("image/sample.png")
image = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
image = 1 - image / 255.
image = cv.resize(image, (8, 8))image = torch.FloatTensor(image).unsqueeze(0).unsqueeze(0).contiguous()
origin_model = Digit()
origin_model.load_state_dict(torch.load("model/digit.pth"))
jit_model = torch.jit.load("model/digit.jit")# init jit
for _ in range(3):run_model(origin_model, image)run_model(jit_model, image)test_times = 10# begin testing
results = pd.DataFrame({"type" : ["orgin"] * test_times + ["jit"] * test_times,"cost_time" : [run_model(origin_model, image) for _ in range(test_times)] + [run_model(jit_model, image) for _ in range(test_times)]
})plt.figure(dpi=120)
sns.boxplot(x=results["type"],y=results["cost_time"]
)
plt.show()
性能箱图如下:
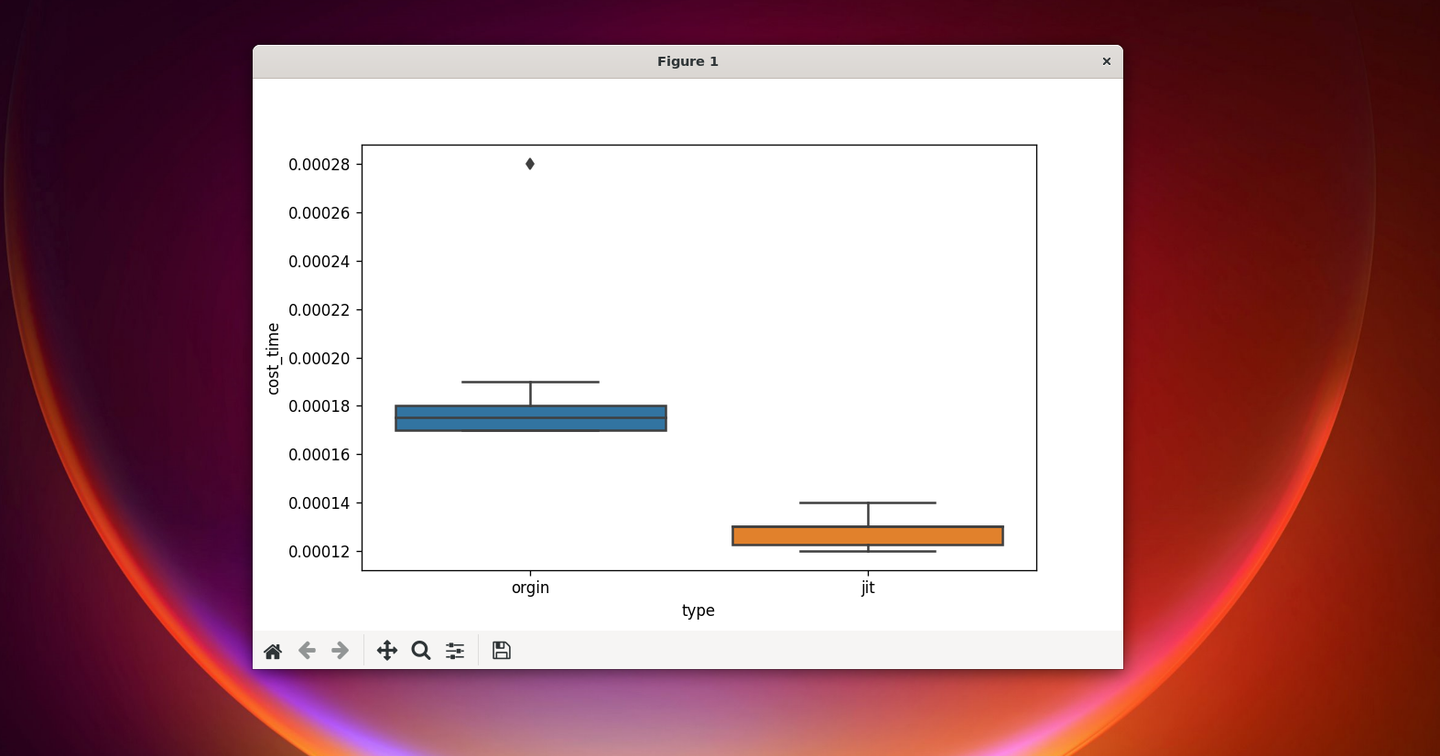
可以看到,JIT的推理速度比原本的有些许的提升。我们的TorchScript模型也可以正常工作。
4.第三步:使用libtorch重写推理程序
由于TorchScript可以被C++直接调用,所以我们只需要使用libtorch重写推理代码,并将模型读入就完成了。
libtorch的语法和PyTorch基本一致,学起来很快,于此锦恢就不再赘述了。相应的,在C++中,我们用cv::Mat来取代Python中的numpy.ndarray对象,如何将cv::Mat转成libtorch可以读入的数据结构也会在demo中涉及。
下面的例子会完成一个C++命令行程序,它的第一个参数为模型,第二个参数为需要读入的手写数字图像的路径,预测结果会打印到控制台上。期待已久的C++代码如下:
#include "iostream"
#include "opencv2/opencv.hpp"
#include "opencv2/imgproc/types_c.h"
#include "torch/script.h"
#include "fstream"
using namespace cv;
using namespace std;
void checkPath(const char* path) {std::ifstream in;in.open(path);bool flag = (bool)in;in.close();if (flag) return;else {std::cout << "file " << path << " doesn't exist!" << std::endl;exit(-1);}
}int main(int argc, char const *argv[])
{if (argc != 3) {std::cout << "usage : digit <model path> <image path>" << std::endl;return -1;}checkPath(argv[1]);checkPath(argv[2]);cv::Mat img = cv::imread(argv[2]), gimg, fimg, rimg;cv::cvtColor(img, gimg, CV_BGR2GRAY);gimg.convertTo(fimg, CV_32F, - 1. / 255., 1.);cv::resize(fimg, rimg, {8, 8});// convert Mat to tensorat::Tensor img_tensor = torch::from_blob(rimg.data,{1, 1, 8, 8},torch::kFloat32);// load modeltorch::jit::Module model = torch::jit::load(argv[1]);// torch.no_grad()torch::NoGradGuard no_grad;// forwardtorch::Tensor out = model({img_tensor}).toTensor();int pre_lab = torch::argmax(out, 1).item().toInt();std::cout << "predict number is " << pre_lab << std::endl;return 0;
}
请一定加入torch::NoGradGuard no_grad; 这句话,否则内存会炸。
然后我们编译一把:
$cd build && cmake .. && make -j8
测试,将之前生成的digit.jit和使用的sample.png放在编译好的C++可执行程序同级目录下,然后执行
$./test ./digit.jit ./sample.png
得到

参考
优雅地使用C++部署你的PyTorch推理模型(一)LibTorch的安装与基本使用
https://zhuanlan.zhihu.com/p/513571175
使用cuda的待尝试
CUDA12.2+Libtorch+VS2022搭建神经网络运行环境及测试(Win10)
https://zhuanlan.zhihu.com/p/656804199
使用SNPE的待尝试
使用SNPE运行PyTorch模型
https://blog.51cto.com/u_16213325/13337144