 刚刚,Java 25 正式发布!
Java 25 都发布了哪些新特性?有没有必要升级?一篇文章,带你速通 Java 新特性。
刚刚,Java 25 正式发布!
Java 25 都发布了哪些新特性?有没有必要升级?一篇文章,带你速通 Java 新特性。大家好,我是程序员鱼皮。
刚刚,Java 25 正式发布!这是继 Java 21 之后,又一个 LTS 长期支持版本,也是 Java 开发者们最期待的版本之一。其中有个特性可以说是颠覆了我对 Java 的认知,让 Java 再次伟大!
那么 Java 25 都发布了哪些新特性?有没有必要升级?
一篇文章,带你速通 Java 新特性,学会后又能愉快地和面试官吹牛皮了~
推荐观看视频版:https://bilibili.com/video/BV1b5pCzGEPx

⭐️ 正式特性
这些特性在 Java 25 中正式稳定,可以在生产环境中放心使用。
【实用】Scoped Values 作用域值
如果我问你:怎么在同一个线程内共享数据?
估计你的答案是 ThreadLocal。
但是你有没有想过,ThreadLocal 存在什么问题?
举一个典型的 ThreadLocal 使用场景,在同一个请求内获取用户信息:
public class UserService {
private static final ThreadLocal<String> USER_ID = new ThreadLocal<>();
public void processRequest(String userId) {
USER_ID.set(userId); // 写入
doWork();
USER_ID.remove(); // 问题:必须手动清理,容易忘记
}
public void doWork() {
String userId = USER_ID.get(); // 读取
System.out.println("处理用户: " + userId);
// 问题:其他代码可以随意修改
USER_ID.set("被篡改的值");
}
}
这段简单的代码其实暗藏玄鸡,可以看出 ThreadLocal 的痛点:
-
容易内存泄漏:必须手动调用
remove() -
可以随意修改数据,可能导致不可预期的结果
此外,如果想让子线程也共享数据,每个子线程都要复制一份数据。如果你使用的是 Java 21 的虚拟线程,1000 个虚拟线程就要复制1000 次,性能很差。
InheritableThreadLocal<String> threadLocal = new InheritableThreadLocal<>();
threadLocal.set("用户数据");
for (int i = 0; i < 1000; i++) {
Thread.ofVirtual().start(() -> {
String data = threadLocal.get(); // 每个线程都有自己的副本
});
}
现在 Java 25 的 Scoped Values 特性转正了,能解决 ThreadLocal 的这些问题。
什么是 Scoped Values?
Scoped Values 允许方法 在线程内以及子线程间安全高效地共享不可变数据。
和传统的 ThreadLocal 相比,它不仅更安全,而且在虚拟线程环境下的内存开销要小很多。
Scoped Values 和 ThreadLocal 的写法很像:
import static java.lang.ScopedValue.where;
public class UserService {
private static final ScopedValue<String> USER_ID = ScopedValue.newInstance();
public void processRequest(String userId) {
where(USER_ID, userId) // 写入并绑定作用域
.run(this::doWork);
// 自动清理,无需 remove()
}
public void doWork() {
String userId = USER_ID.get(); // 读取
System.out.println("处理用户: " + userId);
}
}
这段代码中,我们使用 where().run() 自动管理作用域,出了作用域就自动清理,更安全。
而且作用域一旦绑定,值就不能被修改,避免意外的状态变更。
和虚拟线程配合使用时,所有虚拟线程共享同一份数据,内存占用更小:
ScopedValue<String> scopedValue = ScopedValue.newInstance();
where(scopedValue, "用户数据").run(() -> {
for (int i = 0; i < 1000; i++) {
Thread.ofVirtual().start(() -> {
String data = scopedValue.get(); // 所有线程共享同一份数据
});
}
});
使用方法
1)支持返回值
除了 run() 方法,还可以使用 call() 方法来处理有返回值的场景:
public String processWithResult(String input) {
return where(CONTEXT, input)
.call(() -> {
String processed = doSomeWork();
return "结果: " + processed;
});
}
2)嵌套作用域
支持在已有作用域内建立新的嵌套作用域:
void outerMethod() {
where(X, "hello").run(() -> {
System.out.println(X.get()); // 输出 "hello"
where(X, "goodbye").run(() -> {
System.out.println(X.get()); // 输出 "goodbye"
});
System.out.println(X.get()); // 输出 "hello"
});
}
3)多值绑定
可以在一个调用中绑定多个 Scoped Values,或者直接用类封装多个值:
where(USER_ID, userId)
.where(REQUEST_ID, requestId)
.where(TENANT_ID, tenantId)
.run(() -> {
processRequest();
});
4)和结构化并发配合
Scoped Values 和 Java 结构化并发 API 可以打个配合,子线程自动继承父线程的作用域值:
void handleRequest() {
where(USER_ID, getCurrentUserId())
.run(() -> {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var userTask = scope.fork(() -> loadUser()); // 子线程可以访问 USER_ID
var ordersTask = scope.fork(() -> loadOrders()); // 子线程可以访问 USER_ID
scope.join().throwIfFailed();
return new Response(userTask.get(), ordersTask.get());
}
});
}
不过结构化并发这哥们也挺惨的,过了这么多个版本还没转正。等它转正了,感觉 Java 并发编程的模式也要改变了。
使用场景
虽然 Scoped Values 听起来比 ThreadLocal 更高级,但它不能 100% 替代 ThreadLocal。
如果你要在线程中共享不可变数据、尤其是使用了虚拟线程的场景,建议使用 Scoped Values;但如果线程中共享的数据可能需要更新,那么还是使用 ThreadLocal,要根据实际场景选择。
【实用】模块导入声明
模块导入声明特性(Module Import Declarations)虽然是首次亮相,但它的设计理念可以追溯到 Java 9 的模块系统。
模块系统允许我们将代码组织成模块,每个模块都有明确的依赖关系和导出接口,让大型应用的架构变得更加清晰和可维护。
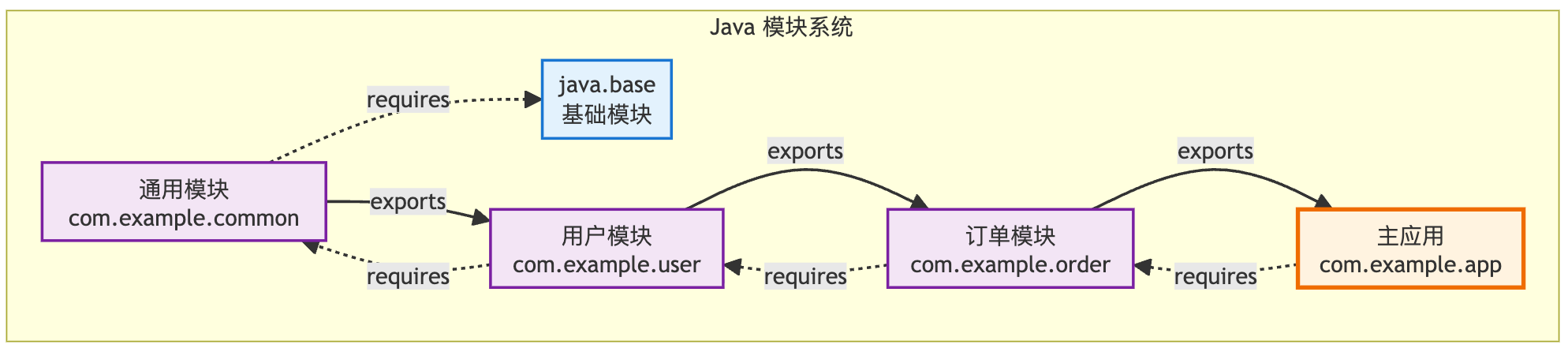
模块导入声明是在这个基础上进一步简化开发体验。
以前我们使用多个 Java 标准库的包需要大量的导入语句:
import java.util.Map;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import java.util.function.Function;
import java.nio.file.Path;
import java.nio.file.Files;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
// ... 还有更多
现在可以一行导入整个模块:
import module java.base;
对于聚合模块(比如 java.se),一次导入可以使用大量包:
import module java.se; // 导入 100 多个包
public class FullFeatureApp {
// 可以使用整个 Java SE 平台的所有公开 API
}
不过我感觉这个特性会比较有争议,我记得大厂的 Java 规约中是禁止使用通配符 * 方式导入所有类的,可读性差、有命名冲突风险、依赖不明确。
而模块导入的范围更大,类名冲突可能更严重。如果导入多个模块时遇到了同名类,还要再通过具体导入来解决:
import module java.base; // 包括 java.util.List 接口
import module java.desktop; // 包括 java.awt.List 类
import java.util.List; // 明确指定使用 util 包的 List
所以我可能不会用这个特性,纯个人偏好。
【必备】紧凑源文件和实例主方法
这是我最喜欢的特性,直接打破了外界对于 Java 的刻板印象!
之前不是都说 Java 入门比 Python 难么?一个简单的 Hello World 程序就要包含类、public、static、方法参数等概念。
传统的 Hello World 程序:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
用 Python 或者 JavaScript 直接写一行代码就完成了:
print("Hello World")
在 Java 25 中,Hello World 程序可以直接简写为 3 行代码!
void main() {
IO.println("Hello, World!");
}
这么一看和好多语言都有点像啊。。。安能辨我是 Java?
但是你知道,这 3 含代码的含金量么?你知道 Java 为了支持简写成这 3 行代码付出了多少努力么?

新的 IO 类
首先是 Java 25 在 java.lang 包中新增了 IO 类,提供更简单的控制台 I/O 操作:
void main() {
String name = IO.readln("请输入您的姓名: ");
IO.print("很高兴认识您,");
IO.println(name);
}
IO 类的主要方法包括:
public static void print(Object obj);
public static void println(Object obj);
public static void println();
public static String readln(String prompt);
public static String readln();
自动导入 java.base 模块
在紧凑源文件中,所有 java.base 模块导出的包都会自动导入,就像有这样一行代码:
import module java.base;
也就是说,你可以直接使用 List、Map、Stream 等常用类:
void main() {
var fruits = List.of("苹果", "香蕉", "橙子");
var lengths = fruits.stream()
.collect(Collectors.toMap(
fruit -> fruit,
String::length
));
IO.println("水果及其长度: " + lengths);
}
这样一来,Java 对初学者更友好,同时也让有经验的开发者能快速编写脚本和小工具。
我觉得这个特性是让 Java 再次伟大的关键,为什么呢?
Java 的核心竞争优势在于它成熟完善的生态系统,但语法不够简洁;现在 Java 只要持续借鉴其他新兴编程语言的优秀设计和语法特性、给开发者提供平滑的技术升级路径,就还是会有很多开发者继续使用 Java,就不会被别的语言取代。
【实用】灵活的构造函数体
这个特性解决的是 Java 自诞生以来就存在的一个限制:构造函数中的 super() 或 this() 调用必须是第一条语句。
这个限制虽然保证了对象初始化的安全性,但可能也会影响我们的编码。
举个例子:
class Employee extends Person {
Employee(String name, int age) {
super(name, age); // 必须是第一条语句
if (age < 18 || age > 67) {
throw new IllegalArgumentException("员工年龄不符要求");
}
}
}
这种写法的问题是,即使参数不符合要求,也会先调用父类构造函数,做一些可能不必要的工作。
Java 25 打破了这个限制,引入了新的构造函数执行模型,分为两个阶段:
-
序言阶段:构造函数调用之前的代码
-
尾声阶段:构造函数调用之后的代码
简单来说,允许在构造函数调用之前添加语句!
class Employee extends Person {
String department;
Employee(String name, int age, String department) {
// 序言阶段,可以校验参数
if (age < 18 || age > 67) {
throw new IllegalArgumentException("员工年龄必须在 18-67 之间");
}
// 可以初始化字段
this.department = department;
// 验证通过后,再调用父类构造函数
super(name, age);
// 尾声阶段,可以干点儿别的事
IO.println("新员工 " + name + " 已加入 " + department + " 部门");
}
}
怎么样,感觉是不是一直以来背的八股文、做的选择题崩塌了!

此外,这个特性还能防止父类构造函数调用子类未初始化的方法:
class Base {
Base() {
this.show(); // 调用可能被重写的方法
}
void show() {
IO.println("Base.show()");
}
}
class Yupi extends Base {
private String message;
Yupi(String message) {
this.message = message; // 在 super() 之前初始化
super();
}
现在,当创建 Yupi 对象时,message 字段会在父类构造函数运行之前就被正确初始化,避免了打印 null 值的问题。
限制条件
但是要注意,在序言阶段有一些限制:
-
不能使用 this 引用(除了字段赋值)
-
不能调用实例方法
-
只能对未初始化的字段进行赋值
class Example {
int value;
String name = "default"; // 有初始化器
Example(int val, String nm) {
// ✅ 允许:验证参数
if (val < 0) throw new IllegalArgumentException();
// ✅ 允许:初始化未初始化的字段
this.value = val;
// ❌ 不允许:字段已有初始化器
// this.name = nm;
// ❌ 不允许:调用实例方法
// this.helper();
super();
// ✅ 现在可以正常使用 this 了
this.name = nm;
this.helper();
}
void helper() { /* ... */ }
}
总之,这个特性让构造函数变得更加灵活和安全,特别适合需要复杂初始化逻辑的场景。
【了解】密钥派生函数 API
随着量子计算技术的发展,传统的密码学算法面临威胁,后量子密码学成为必然趋势。
因此 Java 也顺应时代,推出了密钥派生函数(KDF),这是一种从初始密钥材料、盐值等输入生成新密钥的加密算法。
简单来说,你理解为 Java 出了一个新的加密工具类就好了,适用于对密码进行加强、从主密钥派生多个子密钥的场景。
核心是 javax.crypto.KDF 类,提供了两个主要方法:
-
deriveKey() 生成 SecretKey 对象
-
deriveData() 生成字节数组
比如使用 HKDF(HMAC-based Key Derivation Function)算法:
// 创建 HKDF 实例
KDF hkdf = KDF.getInstance("HKDF-SHA256");
// 准备初始密钥材料和盐值
byte[] initialKeyMaterial = "my-secret-key".getBytes();
byte[] salt = "random-salt".getBytes();
byte[] info = "application-context".getBytes();
// 创建 HKDF 参数
AlgorithmParameterSpec params = HKDFParameterSpec.ofExtract()
.addIKM(initialKeyMaterial) // 添加初始密钥材料
.addSalt(salt) // 添加盐值
.thenExpand(info, 32); // 扩展为 32 字节
// 派生 AES 密钥
SecretKey aesKey = hkdf.deriveKey("AES", params);
// 或者直接获取字节数据
byte[] derivedData = hkdf.deriveData(params);
【了解】紧凑对象头
了解过 Java 对象结构的同学应该知道,Java 对象除了存储数据外,还要通过 对象头 存储很多额外的信息,比如类型信息、GC 标记、锁状态等元数据。
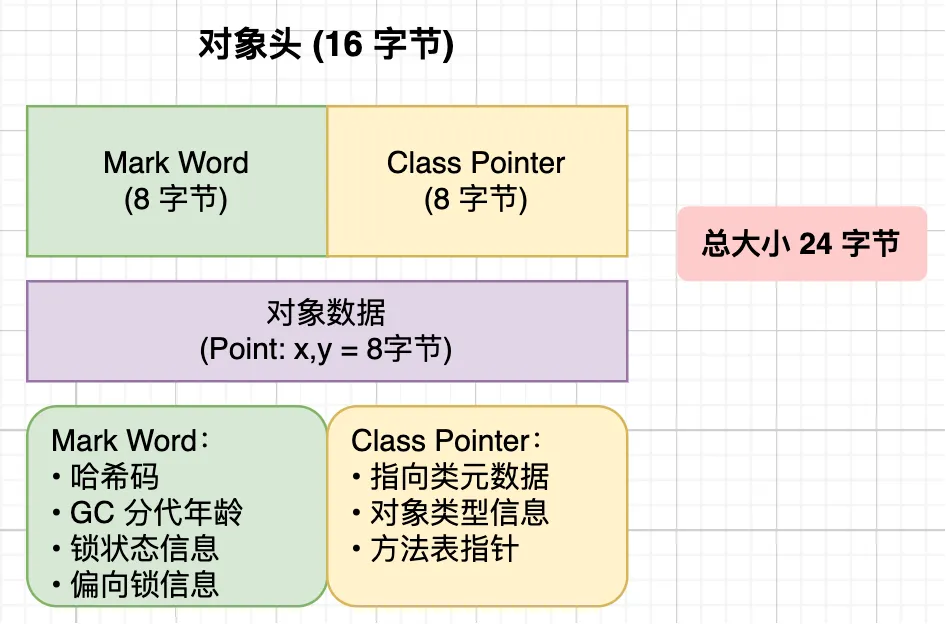
如果程序中要创建大量小对象,可能对象头本身占用的空间都比实际要存储的数据多了!
比如下面这段代码:
class Point {
int x, y; // 实际数据只有 8 字节
}
// 创建一堆 Point 对象
List<Point> points = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
points.add(new Point(i, i)); // 每个对象实际占用 24 字节!
}
用来存储传统的对象头在 64 位系统上占 16 字节,对于只有 8 字节数据的 Point 来说,开销确实有点大。
Java 25 将紧凑对象头特性转正,把对象头从 16 字节压缩到 8 字节,减少了小对象的内存开销。
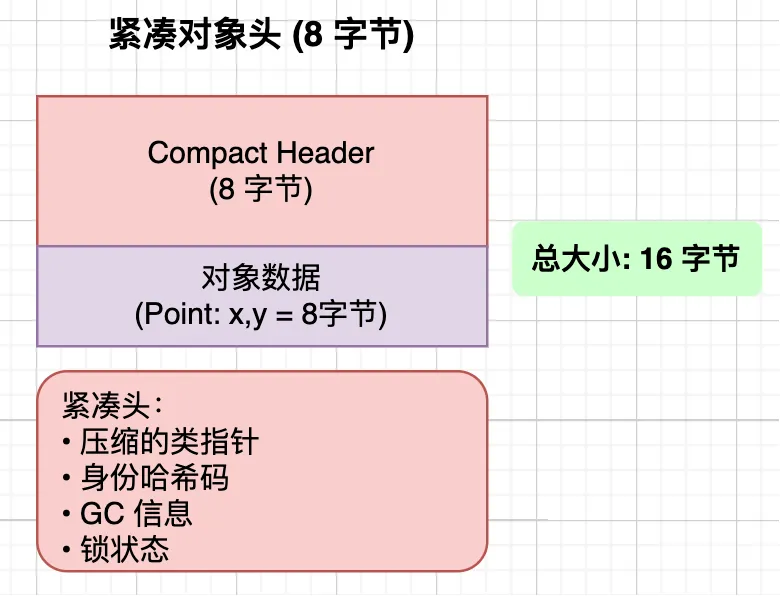
但是,紧凑对象头并不是默认开启的,需要手动指定。毕竟少存了一些信息,必须考虑到兼容性,比如下面这几种情况可能会有问题:
-
使用了 JNI 直接操作对象头的代码
-
依赖特定对象头布局的调试工具
-
某些第三方性能分析工具
【了解】Shenandoah 分代收集
对于 Java 这种自动垃圾收集的语言,我们经常遇到这种问题:GC 一运行,应用就卡顿。特别是占用大堆内存的应用,传统的垃圾收集器一跑起来,停顿时间可能多达几百毫秒甚至几秒。
Shenandoah 作为 Java 中延迟最低的垃圾收集器,在 Java 25 中 Shenandoah 的分代模式转为正式特性。
什么是分代垃圾回收呢?
大部分对象都是 “朝生夕死” 的。将堆内存划分为年轻代和老年代两个区域,年轻代的垃圾收集可以更加频繁和高效,因为大部分年轻对象很快就会死亡,收集器可以快速清理掉这些垃圾;而老年代的收集频率相对较低,减少了对长期存活对象的不必要扫描。
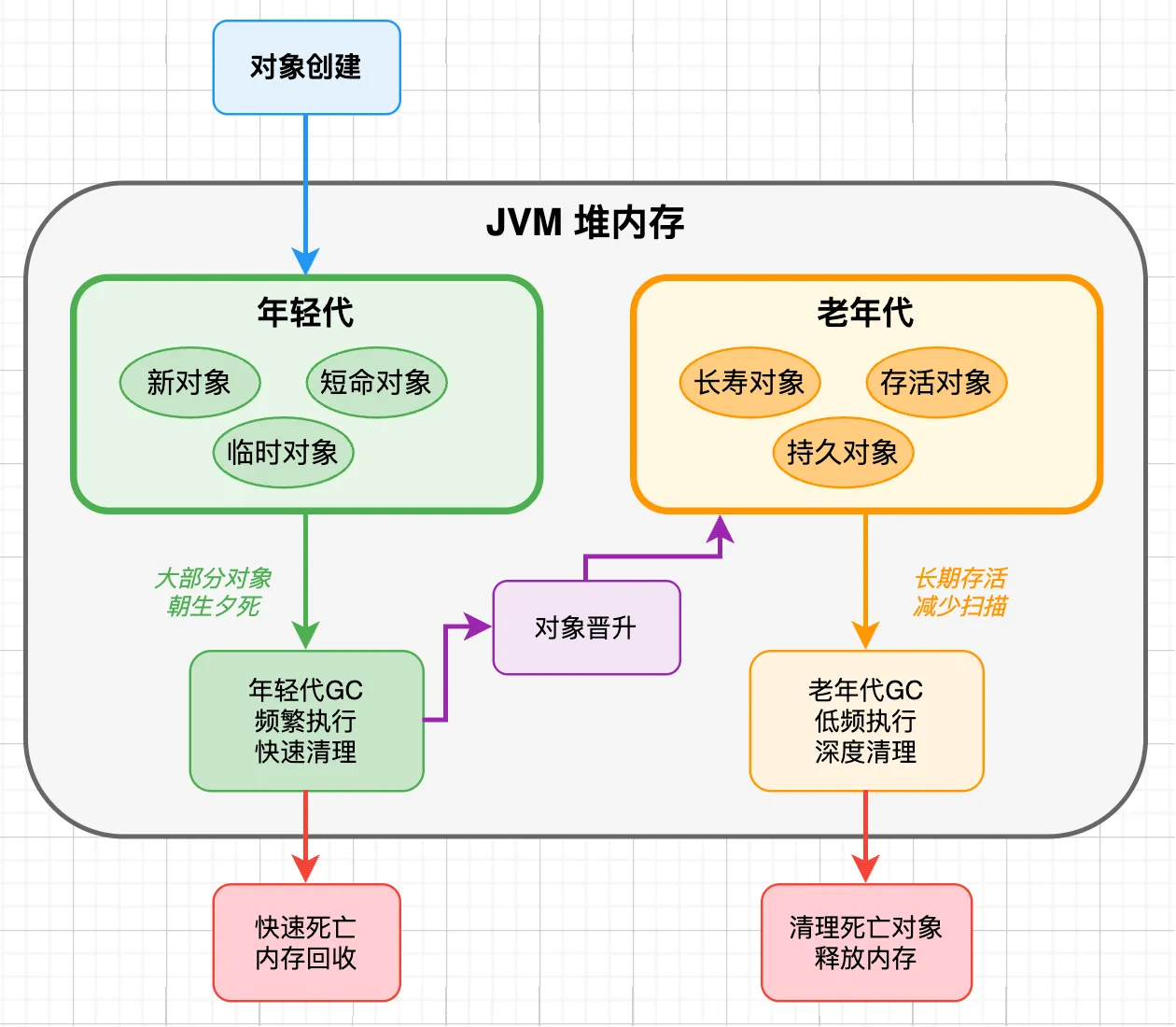
经过大量测试,分代 Shenandoah 在保持超低延迟的同时,还能获得更好的吞吐量。对于延迟敏感的应用来说,这个改进还是很实用的。
但是 Shenandoah 并不是默认的垃圾收集器,需要手动指定。而且分代模式也不是 Shenandoah 的默认模式,默认情况下 Shenandoah 还是使用单代模式。
预览特性
这些特性仍在预览阶段,可以体验 但不建议在生产环境使用!
【了解】结构化并发
目前我们经常使用 ExecutorService 实现并发,可能会写下面这种代码:
// 传统写法
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = executor.submit(() -> findUser());
Future<Integer> order = executor.submit(() -> fetchOrder());
String theUser = user.get(); // 如果这里异常了
int theOrder = order.get(); // 这个任务还在跑,造成线程泄漏!
return new Response(theUser, theOrder);
}
上述代码存在一个问题,如果 findUser() 方法失败了,fetchOrder() 还在后台运行,浪费资源。而且如果当前线程被中断,子任务不会自动取消。
什么是结构化并发?
结构化并发就是来解决并发编程中 线程泄露和资源管理 问题的。它在 Java 25 中第 5 次预览,API 已经成熟,盲猜下个版本就要转正了。
结构化并发的基本使用方法:
Response handle() throws InterruptedException {
// 打开新作用域,打开作用域的线程是作用域的所有者。
try (var scope = StructuredTaskScope.open()) {
// 使用 fork 方法在作用域中开启子任务
var userTask = scope.fork(() -> findUser());
var orderTask = scope.fork(() -> fetchOrder());
// 等待所有子任务完成或失败
scope.join();
return new Response(userTask.get(), orderTask.get());
}
// 作用域结束时,所有子任务自动清理,不会泄漏
}
这样就解决了几个问题:
-
自动清理:任一任务失败,其他任务自动取消
-
异常传播:主线程被中断,子任务也会取消
-
资源管理:可以配合 try-with-resources 保证资源释放
更多用法
Java 25 提供了多种执行策略:
// 1. 默认策略:所有任务都要成功
try (var scope = StructuredTaskScope.open()) {
// 任一失败就全部取消
}
// 2. 竞速策略:任一成功即可
try (var scope = StructuredTaskScope.open(Joiner.anySuccessfulResultOrThrow())) {
var task1 = scope.fork(() -> callService1());
var task2 = scope.fork(() -> callService2());
var task3 = scope.fork(() -> callService3());
// 谁先成功就用谁的结果,其他任务取消
return scope.join();
}
// 3. 收集所有结果(忽略失败)
try (var scope = StructuredTaskScope.open(Joiner.awaitAll())) {
// 等待所有任务完成,不管成功失败
}
结构化并发搭配虚拟线程,可以轻松处理大量并发:
void processLotsOfRequests() throws InterruptedException {
try (var scope = StructuredTaskScope.open()) {
// 创建上万个虚拟线程都没问题
for (int i = 0; i < 10000; i++) {
int requestId = i;
scope.fork(() -> processRequest(requestId));
}
scope.join(); // 等待所有请求处理完成
}
// 自动清理,不用担心线程泄漏
}
【了解】基本类型模式匹配
之前 Java 优化过很多次模式匹配,可以利用 switch 和 instanceof 快速进行类型检查和转换。
比如:
public String processMessage(Object message) {
return switch (message) {
case String text -> "文本消息:" + text;
case Integer number -> "数字消息:" + number;
case List<?> list -> "列表消息,包含 " + list.size() + " 个元素";
case -> "空消息";
default -> "未知消息类型";
};
}
但是目前模式匹配只能用于引用类型,如果你想在 switch 中匹配基本类型,只能用常量,不能绑定变量。
支持基本类型模式匹配后,switch 中可以使用基本类型:
switch (value) {
case int i when i > 100 -> "大整数: " + i;
case int i -> "小整数: " + i;
case float f -> "浮点数: " + f;
case double d -> "双精度: " + d;
}
注意这里的 int i,变量 i 绑定了匹配的值,可以直接使用。
而且基本类型模式会检查转换是否安全,这比手动写范围检查方便多了!
int largeInt = 1000000;
// 检查能否安全转换为 byte
if (largeInt instanceof byte b) {
IO.println("可以安全转换为 byte: " + b);
} else {
IO.println("转换为 byte 会丢失精度"); // 这个会执行
}
// 检查 int 转 float 是否会丢失精度
int preciseInt = 16777217; // 2^24 + 1
if (preciseInt instanceof float f) {
IO.println("转换为 float 不会丢失精度");
} else {
IO.println("转换为 float 会丢失精度"); // 这个会执行
}
【了解】Stable Values 稳定值
这个特性对大多数开发者来说应该是没什么用的。
不信我先考考大家:final 字段有什么问题?
答案是必须在构造时初始化。
举个例子:
class OrderController {
private final Logger logger = Logger.create(OrderController.class);
}
这段代码中,logger 必须立刻初始化,如果创建 logger 很耗时,所有实例都要等待,可能影响启动性能。
特别是在对象很多、但不是每个都会用到某个字段的场景下,这种强制初始化就很浪费。
但我又想保证不可变性,怎么办呢?
Stable Values 可以解决上述问题,提供 延迟初始化的不可变性:
class OrderController {
private final StableValue<Logger> logger = StableValue.of();
Logger getLogger() {
// 只在首次使用时初始化,之后直接返回同一个实例
return logger.orElseSet(() -> Logger.create(OrderController.class));
}
}
说白了其实就是包一层。。。
还有更简洁的写法,可以在声明时指定初始化逻辑:
class OrderController {
private final Supplier<Logger> logger =
StableValue.supplier(() -> Logger.create(OrderController.class));
void logOrder() {
logger.get().info("处理订单"); // 自动延迟初始化
}
}
还支持集合的延迟初始化:
class ConnectionPool {
// 延迟创建连接池,每个连接按需创建
private static final List<Connection> connections =
StableValue.list(POOL_SIZE, index -> createConnection(index));
public static Connection getConnection(int index) {
return connections.get(index); // 第一次访问才创建这个连接
}
}
重点是,Stable Values 底层使用 JVM 的 @Stable 注解,享受和 final 字段一样的优化(比如常量折叠),所以不用担心性能。
这个特性特别适合:
-
创建成本高的对象
-
不是每个实例都会用到的字段
-
需要延迟初始化但又要保证不可变的场景
没记错的话这个特性应该是首次亮相,对于追求性能的开发者来说还是挺实用的。
其他特性
【了解】移除 32 位 x86 支持
Java 25 正式移除了对 32 位 x86 架构的支持。
简单来说就是:32 位系统现在用不了 Java 25 了。
不过对绝大多数朋友来说,这个变化应该没啥影响。
【了解】JFR 性能分析增强
JFR(Java Flight Recorder)飞行记录器是 JDK 内置的低开销性能监控工具,可以记录程序运行时的详细数据。
它在这个版本获得了几个重要增强,包括更精确地测量 CPU 使用情况、通过协作式采样保证了 JVM 安全性、可以更安全地在生产环境开启分析等。
【了解】Vector API(第 10 次孵化)
Vector API 继续孵化,主要改进:
-
更好的数学函数支持:现在通过 FFM API 调用本地数学库,提高可维护性
-
Float16 支持增强:在支持的 CPU 上可以自动向量化 16 位浮点运算
-
VectorShuffle 增强:支持与 MemorySegment 交互
这个 API 对高性能计算、机器学习等领域很重要,尤其是现在 AI 的发展带火了向量运算。但是我想说真的别再孵化了,等你转正了,黄花菜都凉了。
以上就是 Java 25 的新特性了,不知道大家有什么想法,可以在评论区留言分享。
我的评价是:虽然 Java 25 在开发体验、性能优化和并发编程方面都有进步,雨露均沾,但是目前对于新项目选择 Java 21 就够了,老项目还是可以继续用 Java 8,真没必要升级到 Java 25。
但是建议大家还是把 Java 8 之后的 Java 新特性都了解一下,拓宽下知识面,面试的时候也能跟面试官多聊几句。我也把免费 Java 教程和 Java 新特性大全都整理到编程导航上了:
免费 Java 教程 + 新特性大全:https://codefather.cn/course/java

如果本期内容有收获,记得点赞关注三连支持,我们下期见。
