引言
最近几个月,我们公司在开发AI应用平台并集成到现有系统中。作为项目的技术选型负责人,我被MaaS平台API的选择问题折磨得不轻。面对市面上众多的大模型服务商,如何选出最适合我们的那一个,真的是个大难题。
市面上的MaaS平台越来越多,光是国内的就有20多家,这还是我知道的,算上那些还没了解过的,只有更多。每家都说自己的服务好,延迟低,价格优。但是实际使用起来呢?有时候快得起飞,有时候慢得像蜗牛。有时候白天表现不错性能非常好,晚上就开始拉胯起来了。有的标称参数很漂亮,但是实际体验下来却差强人意。
更让人头疼的是啥,我们在做技术选型的时候,往往只能凭借着感觉或者官方给出的理论数据。缺乏一个客观、持续、全面的性能对比平台,就跟那盲人摸象一样。哈哈哈哈。
就在今天阳历9月13号,我在杭州GOSIM大会上了解到清华大学和中国软件评测中心联合发布了《2025大模型服务性能排行榜》,背后的技术支持方是一个叫AI Ping的平台。抱着试试看的心态,我深度体验了一下这个产品。
榜单:
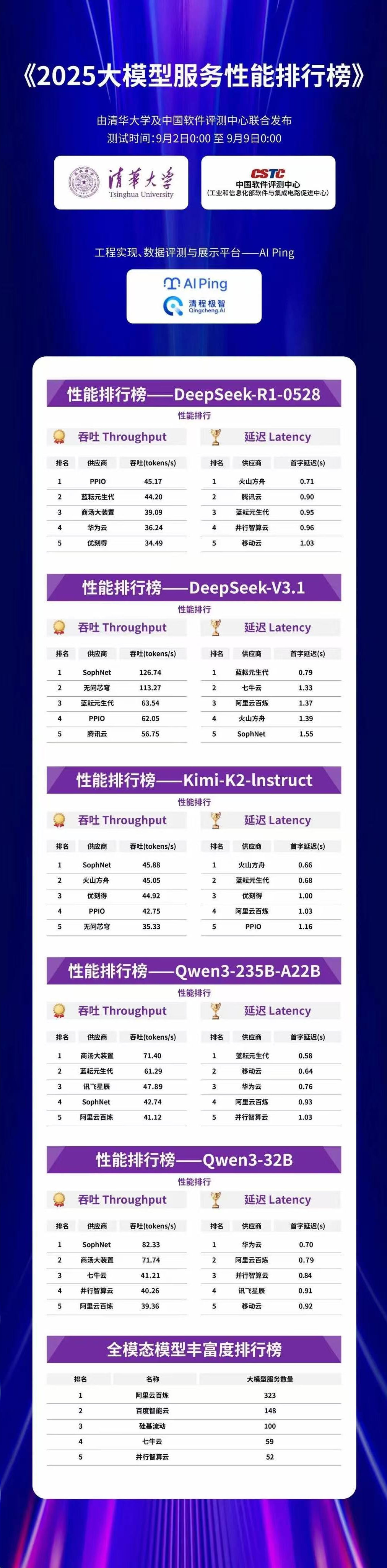
初次接触:这就是我想要的工具
官网地址: 点击跳转官网
打开AI ping的首页,我的第一感觉就是:简洁,专业。没有花里胡哨的营销词汇,直接就是各种性能数据和排行榜。

说实话,这个性能坐标图吸引到我了。横轴是延迟,纵轴是吞吐量,每个点代表一个模型供应商。这种可视化方式让我一眼就能看出哪些模型供应商在这个模型服务上表现的更优。

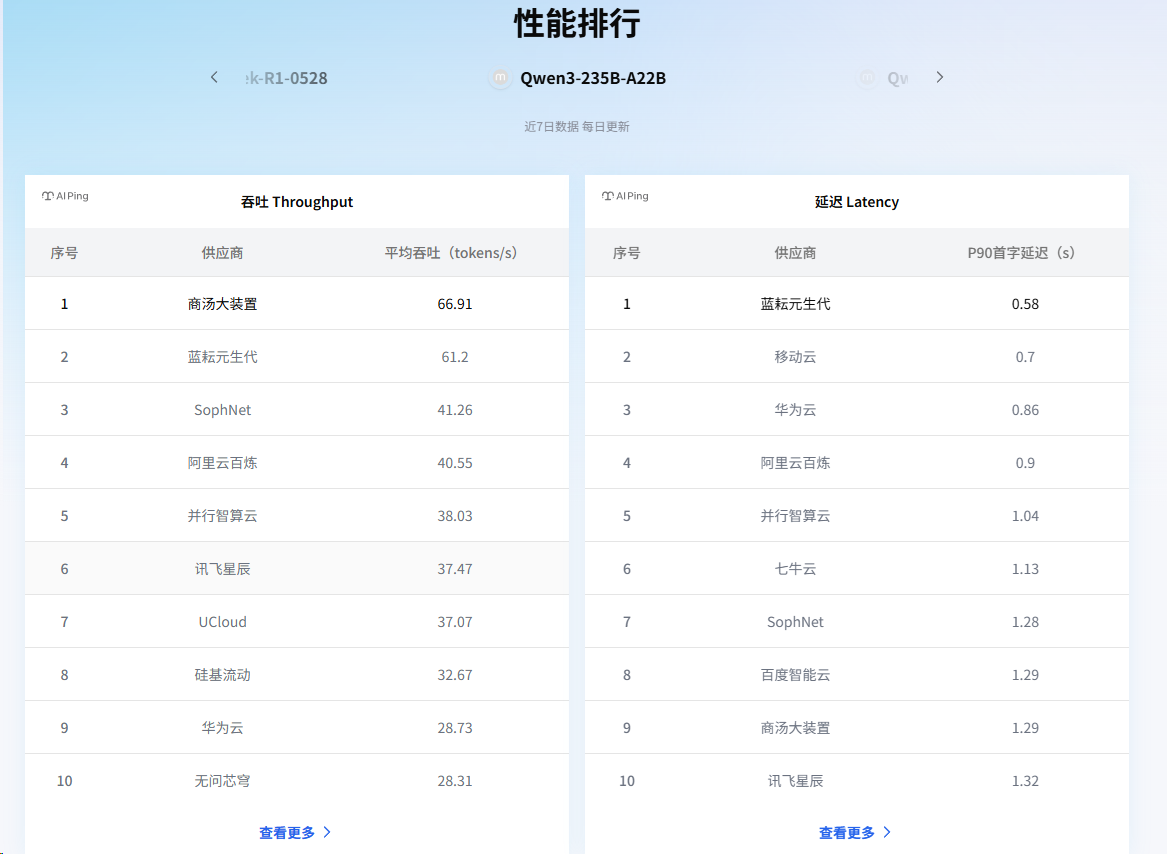
深度体验:数据说话,不玩虚的
覆盖范围够广
目前的话,AI Ping已经整合评测了21家供应商,226个模型服务。基本上国内主流的MaaS平台都包含了。
这个覆盖面对我来说已经完全够用了。之前我需要一个个去各家官网查参数,看文档,现在一个平台就能对比所有供应商以及模型服务了。
评测维度很实用
AI Ping的评测指标正好戳中了我的痛点:
- 延迟(Latency):从发送请求到收到第一个token的时间
- 吞吐(Throughput):每秒收到的token平均数
- 可靠性(Reliability):成功请求占比
这三个指标直接关系到用户体验。延迟影响响应速度,吞吐影响处理效率,可靠性影响服务稳定性。比那些只看精度的评测更贴近实际使用场景。
真实案例:DeepSeek-R1对比
我特别关注DeepSeek-R1这个模型,因为最近项目中正在考虑使用。

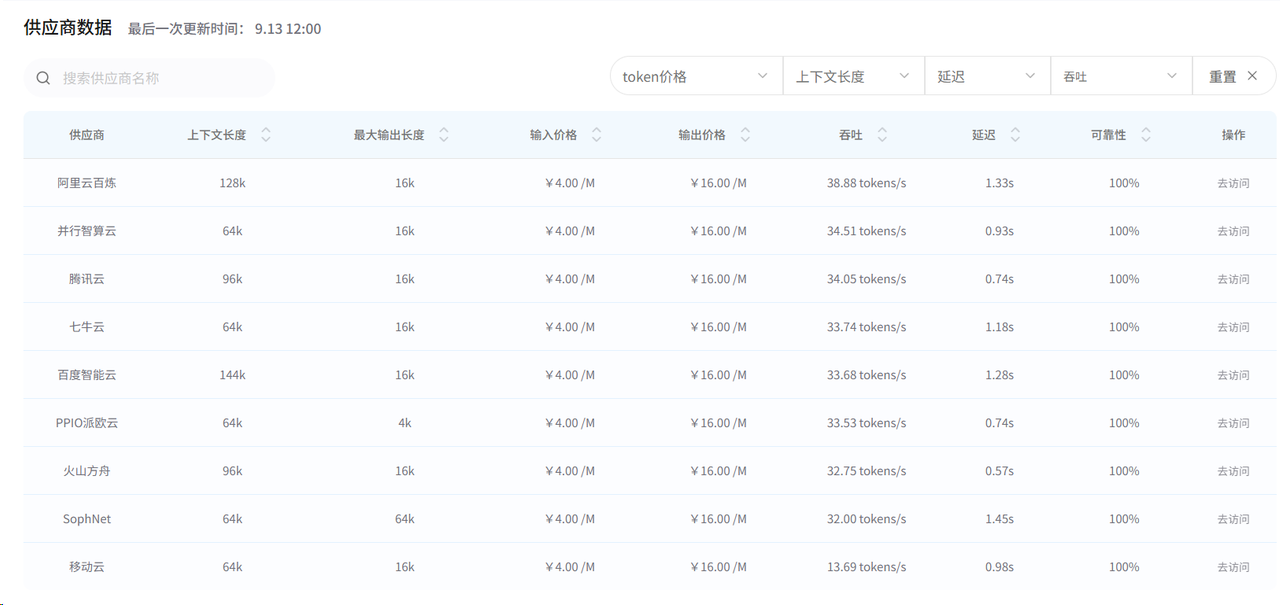
通过AI Ping的对比页面,我可以清晰的看到:
- 各个供应商的性能差异
- 不同供应商的价格对比(输入/输出token价格)
- 不同供应商上下文长度和最大输出长度的对比
- 不同供应商实时的吞吐量和延迟数据对比
这种对比让我发现,同一个模型在不同供应商那里,性能表现竟然差别这么大!有些代理商的上下文长度比官方还要高,有些则明显拖后腿。

让我印象深刻的几个细节
测试规范很严格
AI Ping的测试规范让我觉得很专业:
- 同一轮测试使用相同的输入Prompt和参数
- 同一时间段内进行测试
- 不使用缓存,避免"作弊"
- 不同轮次间变换Prompt前缀
- 统一从北京地区服务器发出请求
这种严格的测试标准保证了数据的公平性和可信度。
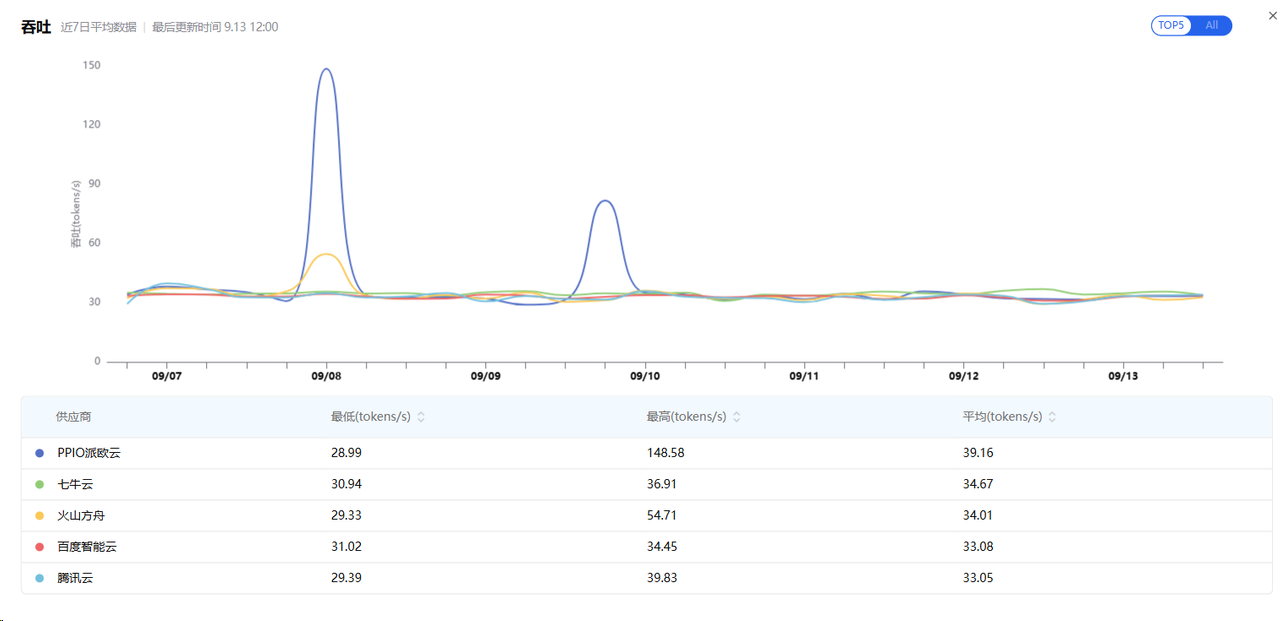
7x24小时持续监测
这个功能太赞了!不是那种一次性"跑分",而是持续监控各个时段的性能表现。
我发现有些服务商在白天表现不错,但到了晚上高峰期就开始掉链子。有了这个持续监测,我就能选择那些全天候稳定的服务商。
数据更新及时
每日更新的性能排行榜让我能及时了解各家服务商的最新表现。这在快速迭代的AI行业特别重要。
实际使用感受
优点
- 节省选型时间:以前需要一周时间调研的工作,现在半小时就能搞定
- 数据客观真实:基于实际测试,不是营销数据
- 界面清晰易懂:技术人员和产品经理都能快速上手
- 更新及时:跟上行业发展节奏
改进建议
- 希望能增加更多地区的测试节点(不只是北京)
- 可以考虑增加成本效益比的综合评分
- 希望能提供API,方便集成到我们的选型工具中
写在最后
作为一个在AI应用开发一线的技术人员,AI Ping确实解决了我的一个痛点。它让大模型服务的选择从"拍脑袋"变成了"看数据"。
特别是在当前这个大模型服务商百花齐放的时代,有这样一个第三方的、客观的评测平台,对整个行业的健康发展都是有益的。
如果你也在为选择哪家大模型服务而纠结,不妨去AI Ping看看。数据会告诉你答案。