跟学视频:学以致知Learning - 软件设计师 基础阶段|考点理论精讲
Chapter 9 - 结构化开发方法(数据流图)
1 - 系统设计基本原理
抽象
抽象是一种设计技术,重点说明一个实体的本质方面,而忽略或掩盖不是很重要或非本质的方面
模块化
模块化是指将一个待开发的软件分解成若干个小的、简单的部分——模块,每个模块可独立地开发、测试,最后组装成完整的程序。模块化的目的是使程序的结构清晰,容易阅读、理解、测试和修改
信息隐蔽
信息隐蔽是开发整体程序结构时使用的法则,即将每个程序的成分隐蔽或封装在一个单一的设计模块中,定义每一个模块时尽可能少地显露其内部的处理。信息隐蔽原则对提高软件的可修改性、可测试性和可移植性都有重要的作用
模块独立
模块独立是指每个模块完成一个相对独立的特定子功能,并且与其他模块之间的联系简单
衡量模块独立程度的标准有两个:耦合和内聚。耦合是指模块之间联系的紧密程度。耦合度越高,则模块的独立性越差;内聚是指模块内部各元素之间联系的精密程度。内聚度越低,则模块的独立性越差。因此,模块独立就是希望每个模块都是高内聚、低耦合的
| 内聚类型 | 描述 |
|---|---|
| 功能内聚 | 完成一个单一功能,各个部分协同工作,缺一不可 |
| 顺序内聚 | 处理元素相关,而且必须顺序执行 |
| 通信内聚 | 所有处理元素集中在一个数据结构的区域上 |
| 过程内聚 | 处理元素相关,而且必须按特定的次序执行 |
| 瞬时内聚(时间内聚) | 所包含的任务必须在同一时间间隔内执行 |
| 逻辑内聚 | 完成逻辑上相关的一组任务 |
| 偶然内聚(巧合内聚) | 完成一组没有关系或松散关系的任务 |
| 耦合类型 | 描述 |
|---|---|
| 非直接耦合 | 两个模块之间没有直接关系 它们之间的联系完全是通过主模块的控制和调用来实现的 |
| 数据耦合 | 一组模块借助参数表传递简单数据 |
| 标记耦合 | 一组模块借助参数表来传递记录信息 |
| 控制耦合 | 模块之间传递的信息中包含用于控制模块内部逻辑的信息 |
| 外部耦合 | 一组模块都访问同一全局简单变量 而且不是通过参数表传递该全局变量的信息 |
| 公共耦合 | 多个模块都访问同一个公共数据环境 |
| 内容耦合 | 一个模块直接访问另一个模块的内部数据 一个模块不通过正常入口转到另一个模块的内部 两个模块有一部分程序代码重叠 一个模块有多个入口 |

2 - 系统总体结构设计
系统结构设计应遵循以下原则:
- 分解——协调原则
- 自顶向下原则
- 信息隐蔽、抽象的原则
- 一致性原则
- 明确性原则
- 模块之间的耦合度尽可能小,模块的内聚度尽可能高
- 模块的扇入系数和扇出系数要合理
- 模块的规模适当
子系统划分要遵循以下原则:
- 子系统要具有相对独立性
- 子系统之间数据的依赖性尽量小
- 子系统划分的结果应使数据冗余较小
- 子系统的设置应考虑今后管理发展的需要
- 子系统的划分应便于系统分阶段实现
- 子系统的划分应考虑到各类资源的充分利用
模块是组成系统的基本单位,它的特点是可以组合、分解和更换。系统中任何一个处理功能都可以看成是一个模块。根据模块功能具体化程度的不同,可以分为逻辑模块和物理模块
一个模块要具备以下四个要素:
- 输入和输出:模块的输入来源和输出去向都是同一个调用者,即一个模块从调用者那里取得输入,进行加工后再把输出返回给调用者
- 处理功能:指模块把输入转换成输出所做的工作
- 内部数据:指仅供该模块本身引用的数据
- 程序代码:指用来实现模块功能的程序
3 - 数据流图
基本概念
数据流图:或称数据流程图,是一种便于用户理解、分析系统数据流程的图形工具。它摆脱了系统的物理内容,精确地在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分
数据字典:数据流图描述了系统的分解,但没有对图中各成分进行说明。数据字典用于对数据流图中每个数据流、文件、加工,以及组成数据流或文件的数据项做出说明
数据字典有四类条目:数据流条目、数据存储条目、加工条目和数据项条目。数据字典管理主要是指把字典条目按照某种格式组织后存储在字典中,并提供排序、查找、统计等功能
数据字典
| 符号 | 含义 | 举例说明 |
|---|---|---|
| = | 被定义为 | |
| + | 与 | x=a+b,表示x由a和b组成 |
| [… , …]或[… | …] | 或 | x=[a , b],x=[a | b],表示x由a或由b组成 |
| 重复 | x={a},表示x由0个或多个a组成 | |
| (…) | 可选 | x=(a),表示a可在x中出现,也可以不出现 |
基本成分
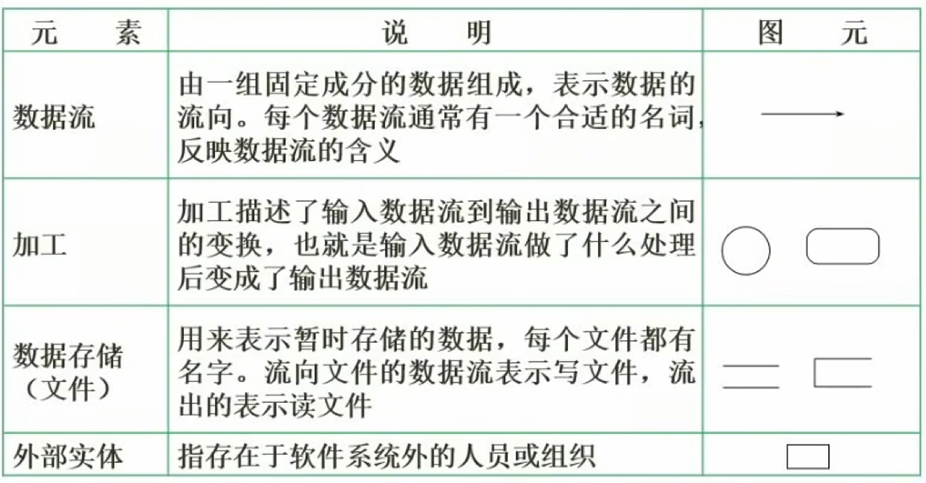
数据流图的分层

对图和加工进行编号
对于一个软件系统,其数据流图可能有许多层,每一层又有许多张图。为了区分不同的加工和不同的DFD子图,应该对每张图和每个加工进行编号,以利于管理
父图与子图
假设分层数据流图里的某张图A中的某个加工可用另一张图B来分解,则称图A是图B的父图,图B是图A的子图
在一张图中,有些加工需要进一步分解,有些加工则不必分解。因此,如果父图中有n个加工,那么它可以有0~n张子图(这些子图位于同一层),但每张子图都只对应于一张父图
编号
- 顶层图只有一张,图中的加工也只有一个,所以不必编号
- 0层图只有一张,图中的加工号可以分别是0.1、0.2 或者 1.2、…
- 子图号就是父图中被分解的加工号
- 图的加工号由图号、原点和序号组成
数据流图应注意的问题
(1)适当地为数据流、加工、数据存储、外部实体命名,名字应反映该成分的实际含义,避免空洞的名字
(2)画数据流而不要画控制流
(3)每条数据流的输入或者输出都是加工
(4)一个加工的输出数据流不应与输入数据流同名,即使它们的组成成分相同
(5)允许一个加工有多条数据流流向另一个加工,也允许一个加工有两个相同的输出数据流流向两个不同的加工
(6)保持父图与子图平衡。也就是说,父图中某加工的输入/输出数据流必须与它的子图的输入/输出数据流在数量和名字上相同。值得注意的是,如果父图的一个输入(或输出)数据流对应子图中几个输入(或输出)数据流,而子图中组成这些数据流的数据项全体正好是父图中的这一个数据流,那么它们仍然算是平衡的
(7)在自顶向下的分解过程中,若一个数据存储首次出现时只与一个加工有关,那么这个数据存储应作为这个加工的内部文件而不必画出
(8)保持数据守恒。也就是说,一个加工所有输出数据流中的数据必须能从该加工的输入数据流中直接获得,或者是通过该加工产生的数据中获得
(9)每个加工必须既有输入数据流,又有输出数据流
(10)在整套数据流图中,每个数据存储必须既有读的数据流,又有写的数据流。但在某一张子图中,可能是只有读没有写,或者是只有写没有读
