Redis Stack扩展功能
一、Redis JSON:让 Redis 原生支持 JSON 数据类型
什么是 Redis JSON?
Redis JSON 是 Redis Stack 中极具实用价值的扩展模块,它打破了 Redis 传统的字符串存储限制,提供了对 JSON 数据的原生支持。这意味着我们可以直接在 Redis 中存储、查询和修改 JSON 数据,无需再将 JSON 转为字符串存储后进行二次解析,大幅简化了数据处理流程。
核心指令实战指南
1. JSON.SET:存储 JSON 数据的基石
JSON.SET用于向 Redis 中写入 JSON 数据,其基本语法为:
JSON.SET key $ '{"字段名":"值"}'
其中$代表 JSON 数据的根节点,后续所有字段路径都基于此节点展开。
基础示例:
# 存储一个用户信息JSON对象
JSON.SET user $ '{"name":"loulan","age":18,"hobbies":["reading"]}'
进阶用法:
-
条件设置:通过
NX参数实现 “字段不存在时才设置”,避免覆盖已有数据:# 仅当address字段不存在时,添加地址信息 JSON.SET user $.address '{"city":"Changsha","country":"China"}' NX -
数组操作:使用
JSON.ARRAPPEND向 JSON 数组添加元素:# 向hobbies数组添加"swimming" JSON.ARRAPPEND user $.hobbies '"swimming"'
2. JSON.GET:精准提取 JSON 数据
JSON.GET支持通过路径查询 JSON 中的特定字段,无需读取完整对象后再解析,显著提升效率。
示例:
# 获取完整用户信息
JSON.GET user# 仅获取用户名
JSON.GET user $.name# 同时获取年龄和爱好
JSON.GET user $.age $.hobbies
3. 其他高频指令
JSON.NUMINCRBY:对 JSON 中的数值字段进行自增操作,如将年龄增加 2 岁:
JSON.NUMINCRBY user $.age 2JSON.TYPE:查看字段的数据类型,辅助数据校验:
JSON.TYPE user $.name(返回 "string")JSON.DEL:删除指定字段,如移除地址信息:
JSON.DEL user $.address
为什么选择 Redis JSON?
相比将 JSON 作为字符串存储,Redis JSON 的优势体现在三个核心维度:
- 性能与内存优化:底层采用高效二进制格式存储,读写性能远超文本格式,且内存占用更低。根据官方测试,其性能可媲美 MongoDB 等传统 NoSQL 数据库。
- 高效查询能力:基于树状结构存储 JSON,支持直接定位子元素,避免全量解析,查询效率提升显著。
- 无缝集成 Redis 生态:可与 Redis 的 TTL、事务、发布 / 订阅等功能完美配合,例如为 JSON 数据设置过期时间,或在事务中原子性修改 JSON 字段。
典型使用场景
- 分布式系统中的用户会话管理:存储用户登录信息(如权限、角色、登录时间),支持高效字段更新。
- 电商商品详情缓存:直接存储包含多维度信息(名称、价格、规格、评价)的商品 JSON,快速响应商品详情页查询。
二、Search And Query:让 Redis 拥有搜索引擎能力
当 Redis 中存储的数据量达到十万甚至百万级时,如何高效检索数据成为关键问题。Redis Stack 的 Search And Query 模块正是为解决这一痛点而生,它让 Redis 具备了类似 ElasticSearch 的复杂搜索能力。
传统搜索方式的局限性
在 Redis Stack 出现前,开发者通常依赖两种方式检索数据:
keys *:遍历所有键,会导致线程阻塞,生产环境严格禁用。scan:通过游标迭代返回部分结果,避免阻塞,但仅支持简单的键名匹配,无法实现字段级筛选。
例如,电商场景中需要 “价格在 2000-5000 元且品牌为华为的手机” 这类多条件筛选时,传统方式完全无法满足。
Search And Query 的实战用法
Search And Query 模块通过 “索引 + 结构化查询” 实现复杂搜索,支持 HASH 和 JSON 两种数据结构,以下以 JSON 为例演示核心流程。
1. 创建索引:定义搜索规则
使用FT.CREATE创建索引,指定需要检索的字段及类型:
# 创建名为productIndex的索引,基于JSON数据,对name(文本)和price(数值)建立索引
FT.CREATE productIndex ON JSON SCHEMA $.name AS name TEXT $.price AS price NUMERIC
2. 插入数据:准备检索样本
通过JSON.SET插入符合索引规则的 JSON 数据:
# 插入10条华为手机数据
JSON.SET phone:1 $ '{"id":1,"name":"HUAWEI 1","price":1999}'
JSON.SET phone:2 $ '{"id":2,"name":"HUAWEI 2","price":2999}'
# ... 省略phone:3至phone:10
3. 执行搜索:多条件筛选
使用FT.SEARCH实现复杂查询,例如 “名称包含 HUAWEI 且价格在 1000-5000 元的手机”:
# 返回id和name字段,符合条件的结果
FT.SEARCH productIndex "@name:HUAWEI @price:[1000 5000]" RETURN 2 id name
核心优势与适用场景
- 替代传统搜索引擎:无需将数据同步到 ElasticSearch,直接在 Redis 中完成筛选,减少数据迁移成本。
- 低延迟响应:依托 Redis 的内存存储特性,搜索响应速度远超磁盘存储的搜索引擎。
- 适用场景:电商商品筛选、日志快速检索、用户信息多条件查询等。
三、布隆过滤器:海量数据中的快速存在性判断
在处理海量数据时,“判断一个元素是否存在于集合中” 是常见需求,例如 “用户是否已签到”“用户名是否已注册”。布隆过滤器(Bloom Filter)作为一种空间效率极高的概率型数据结构,成为解决这类问题的理想选择。
布隆过滤器的核心原理
布隆过滤器通过两个核心组件实现高效判断:
- 二进制位数组:初始时所有位均为 0,用于标记元素是否 “可能存在”。
- 多个哈希函数:将输入元素映射到位数组的多个位置,插入元素时将这些位置设为 1。
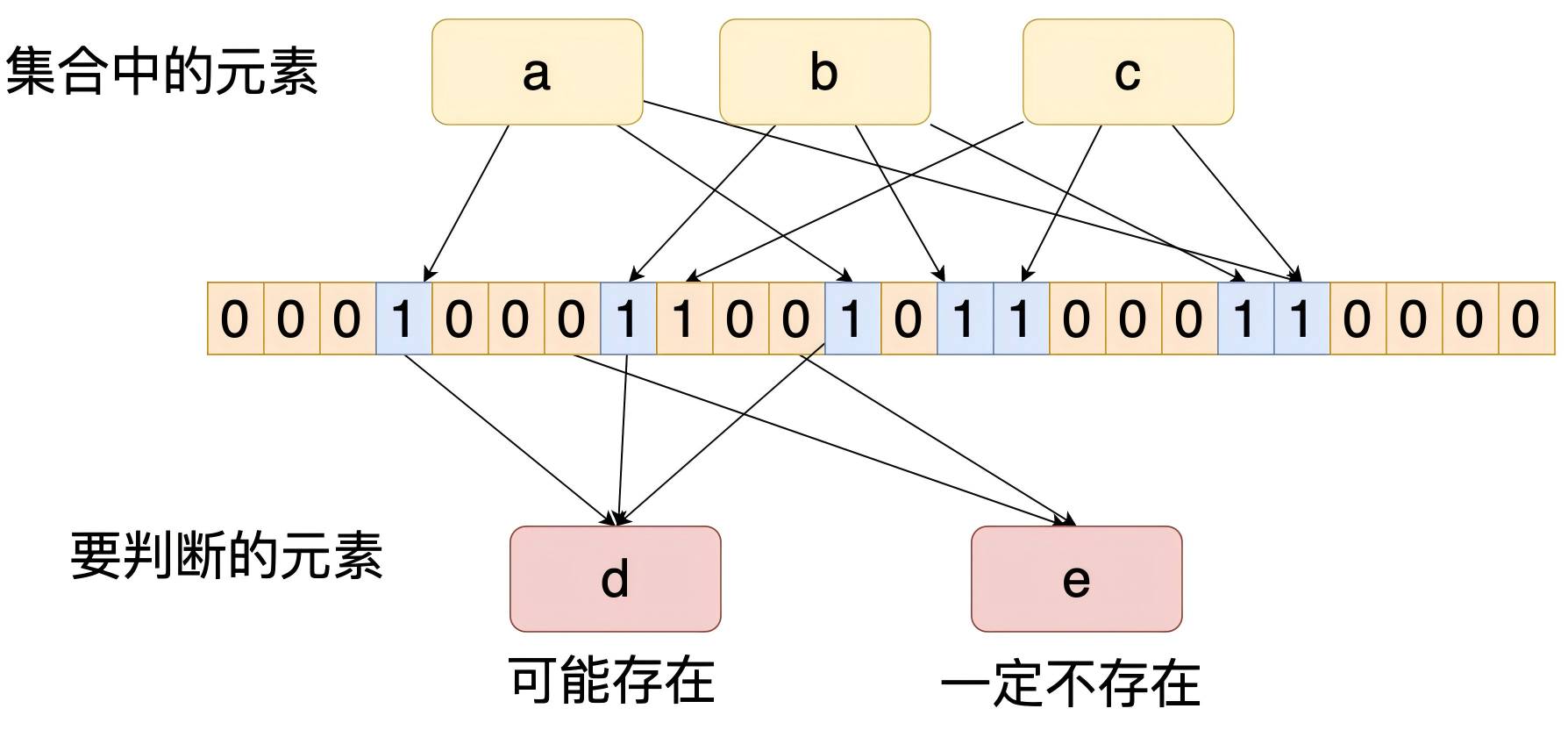
判断逻辑:
- 若元素映射的所有位置均为 1,则 “可能存在”(存在误判);
- 若任一位置为 0,则 “一定不存在”。
分析布隆过滤器结构图可知,d哈希之后的位数组的值与a或b哈希之后的数组位存在重叠,这也解释了为什么都满足了只是可能存在,而不满足则一定不存在;同时也理解了为什么不能删除元素
实战示例:从 Guava 到 Redis
1. Guava 布隆过滤器(本地实现)
Guava 是 Java 中常用的布隆过滤器实现库,通过指定容量和误判率初始化:
// 引入依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>33.1.0-jre</version>
</dependency>// 代码示例:存储A-Z并判断
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 10000, // 容量0.01 // 误判率
);
// 存入A-Z
for (int i = 64; i <= 90; i++) {bloomFilter.put(String.valueOf((char) i));
}
System.out.println(bloomFilter.mightContain("A")); // true
System.out.println(bloomFilter.mightContain("a")); // false
2. Redis 布隆过滤器(分布式场景)
Redis 通过BF系列指令原生支持布隆过滤器,适合分布式系统中的共享判断逻辑:
# 创建过滤器:容量1000,误判率0.01,不扩容
BF.RESERVE userSign 0.01 1000 NONSCALING# 单个添加:用户A签到
BF.ADD userSign A# 批量添加:用户B、C、D签到
BF.MADD userSign B C D# 判断用户是否签到:返回1表示可能已签,0表示未签
BF.EXISTS userSign A # 1
BF.EXISTS userSign X # 0
局限性与适用场景
- 局限性:存在误判率(可通过增大位数组或增加哈希函数降低),且无法删除元素。
- 适用场景:
- 缓存穿透防护:快速判断请求的 key 是否存在,避免无效数据库查询。
- 重复操作拦截:如限制用户重复签到、重复下单等。
实际业务中,我们可以通过lua脚本封装自己的工具类
四、Cuckoo Filter:支持删除的布隆过滤器改进版
布隆过滤器的最大痛点是 “无法删除元素”,而 Cuckoo Filter(布谷鸟过滤器)通过优化数据结构解决了这一问题,同时保持了高效的空间利用率。
Cuckoo Filter 的核心改进
- 存储结构:采用 “桶(Bucket)” 存储元素指纹(压缩后的元素信息),每个桶可存放多个指纹,默认每个桶存 2 个。
- 删除支持:通过指纹反向定位元素位置,实现精确删除,解决了布隆过滤器的历史难题。
- 参数调优:
BUSKETSIZE:每个桶的元素数,越大空间利用率越高,但误判率也越高。MAXITERATIONS:插入时的最大重试次数,影响性能与空间利用率。
实战示例
# 创建过滤器:容量1000,桶大小2,最大重试20次
CF.RESERVE userLogin 1000 BUSKETSIZE 2 MAXITERATIONS 20# 添加元素:用户登录记录
CF.ADD userLogin user123# 判断元素是否存在
CF.EXISTS userLogin user123 # 1# 删除元素:用户退出登录
CF.DEL userLogin user123# 再次判断:已删除
CF.EXISTS userLogin user123 # 0
适用场景
适合需要动态更新集合的场景,如:
- 在线用户列表:实时添加 / 删除在线用户,快速判断用户状态。
- 临时黑名单:动态封禁 / 解封账号,高效拦截恶意请求。
五、手动安装 Redis 扩展模块:本地环境实战
Redis Stack 的扩展模块不仅可在 Redis Cloud 中使用,也能手动安装到本地 Redis 服务,步骤如下:
-
下载模块:从 Redis 官网下载对应 Redis 版本和操作系统的模块文件(如
redisbloom.so),建议通过源码编译确保兼容性。 -
配置加载:修改 Redis 配置文件(
redis.conf),添加模块路径:loadmodule /path/to/redisbloom.so # 替换为实际路径 -
重启验证:
-
重启 Redis 服务:
redis-server /path/to/redis.conf -
查看模块加载情况:
-
127.0.0.1:6379> MODULE LIST
# 若显示"name":"bf"等信息,说明加载成功
-
注意事项:
- 模块文件需赋予可执行权限:
chmod +x redisbloom.so,否则 Redis 启动失败。 - 模块版本需与 Redis 版本匹配,否则可能出现兼容性问题。
- 模块文件需赋予可执行权限:
总结
Redis Stack 通过 JSON、Search And Query、布隆过滤器、Cuckoo Filter 等扩展模块,极大地丰富了 Redis 的功能边界。无论是处理结构化 JSON 数据、实现复杂搜索,还是解决海量数据的存在性判断问题,Redis Stack 都能提供高效且易用的解决方案。对于开发者而言,掌握这些扩展功能不仅能提升业务处理效率,更能让 Redis 在更多场景中发挥核心作用,从缓存工具升级为全能型数据处理平台。
如果你还在为 JSON 存储繁琐、搜索能力不足或海量数据判断发愁,不妨试试 Redis Stack 的这些扩展功能,相信会给你的开发工作带来全新的体验。