这里我使用了科大讯飞的免费大模型来尝试
最简的应用
from langchain_community.chat_models import ChatOpenAI
from langchain.schema import HumanMessagellm = ChatOpenAI(model_name="xop3qwen1b7", # 模型名称openai_api_base="https://maas-api.cn-huabei-1.xf-yun.com/v1", # 第三方API地址openai_api_key="sk-kBa9GlpIxpWX281iA35a26624b3d4f...", # 免费申请的API密钥temperature=0.7,max_tokens=1024
)# 统一调用方式
response = llm([HumanMessage(content="分析测试用例与需求的覆盖率关键点")
])print(response.content)
运行后得到了如下响应:

一个最简单的 本地文档问答机器人(RAG)
将构建一个最简单的 本地文档问答机器人(RAG) 的核心流程。这个例子包含了 Models, Prompts, Chains 和 Retrieval 等核心概念,非常具有实践意义。
# -*- codeing = utf-8 -*-
# @Time :2025/9/12 15:32
# @Author :Ajie
# @Version :1.0
# @Description : 学习的开始
# @File : l_start.pyimport osfrom langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAIfrom langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import Docx2txtLoader
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplatefrom langchain_community.embeddings import HuggingFaceEmbeddings# 1. 准备大模型api key
os.environ["OPENAI_API_KEY"] = "sk-kBa9GlpIxpWX281iA35a2..." # 请务必替换!
os.environ["OPENAI_API_BASE"] = "https://域名/v1"
# 2. 准备知识库文档,这里使用AI生成了一篇关于Jmeter的知识库文档# 3. 初始化第三方LLM模型
llm = ChatOpenAI(model_name="xop3qwen1b7", # 模型名称openai_api_base="https://域名/v1", # 第三方API地址openai_api_key="sk-kBa9GlpIxpWX281iA35a...", # 免费申请的API密钥temperature=0.7,max_tokens=1024
)# 4. 加载、分割文档
loader = Docx2txtLoader("D:\MyCode\TestProject\LLangChain\JMeterFile.docx")
documents = loader.load()
# test_splitter = RecursiveCharacterTextSplitter(chunk_size=200, # 每个文本块的大小
# chunk_overlap=50 # 块之间的重叠部分
# )
# 上面的配置可能存文本分割问题,对分割配置优化
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 增大块大小,能容纳更多内容chunk_overlap=100, # 增大重叠区域,更好地保留上下文separators=["\n\n", "\n", "。", "!", "?", " ", ""] # 优先按句号等自然分隔符分割
)texts = text_splitter.split_documents(documents)
# 5. 使用模型创建词并嵌入(Embedding),并存入向量数据 ,# 目前看使用的这个千问的模型不属于嵌入模型,不具备向量能力
# embeddings = OpenAIEmbeddings(model="xop3qwen1b7")
# print("正在生成向量并存入Chroma数据库...")# 解决向量问题:使用本地 Embedding 模型 (以 sentence-transformers 为例)
# 初始化一个本地Embedding模型
# 使用一个轻量且中文效果好的模型
model_name = "BAAI/bge-small-zh-v1.5"
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs={'device': 'cpu'}, # 使用CPU运行encode_kwargs={'normalize_embeddings': True} # 归一化向量
)
print(f"正在加载本地模型: {model_name}...")
vectorstore = Chroma.from_documents(documents=texts,embedding=embeddings,persist_directory="./chroma_db"
)
print("Chroma数据库创建并持久化成功!")# # 6. 验证:进行相似性搜索,证明数据库工作正常
# print("\n--- 开始验证向量数据库 ---")
# query = "Jmeter如何生成测试报告?"
# # print(f"查询问题: '{query}'")
# # 从数据库检索最相似的3个文档片段
# docs = vectorstore.similarity_search(query, k=3)
# print(f"检索到 {len(docs)} 个相关片段:")# 6. 创建一个中文的提示模板
prompt_template = """
请你作为一名专业的助理,严格根据以下提供的背景信息来回答用户的问题。如果背景信息中包含问题答案,请根据背景信息用中文回答。
如果背景信息中不包含问题答案,请如实告知"根据提供的资料,我无法找到相关答案。"背景信息:
{context}用户问题:
{question}请用中文给出准确、专业的回答:
"""
# 提示词模板
PROMPT = PromptTemplate(template=prompt_template,input_variables=["context", "question"]
)
# 7. 创建检索式问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=vectorstore.as_retriever(search_kwargs={"k": 3}), # 检索最相关的3个文本块chain_type_kwargs={"prompt": PROMPT},return_source_documents=True)if __name__ == '__main__':print("🔍 基于本地知识的智能问答系统已启动!")print("💡 输入'退出'即可结束程序")print("-" * 50)while True:try:query = input("\n请输入你的问题: ").strip()if query.lower() in ['退出', 'exit', 'quit']:print("感谢使用,再见!")breakif not query:continue# 获取答案print("正在思考...")result = qa_chain.invoke({"query": query})answer = result["result"]source_docs = result["source_documents"]print(f"\n🤖 答案: {answer}")# 显示参考来源(调试用)print(f"\n📚 参考了 {len(source_docs)} 个文档片段:")for i, doc in enumerate(source_docs, 1):print(f"[{i}] {doc.page_content[:80]}...")except Exception as e:print(f"❌ 出错了: {e}")print("请检查网络连接或API配置")
得到的回答如下:
- 提问知识库相关的内容得到的回答
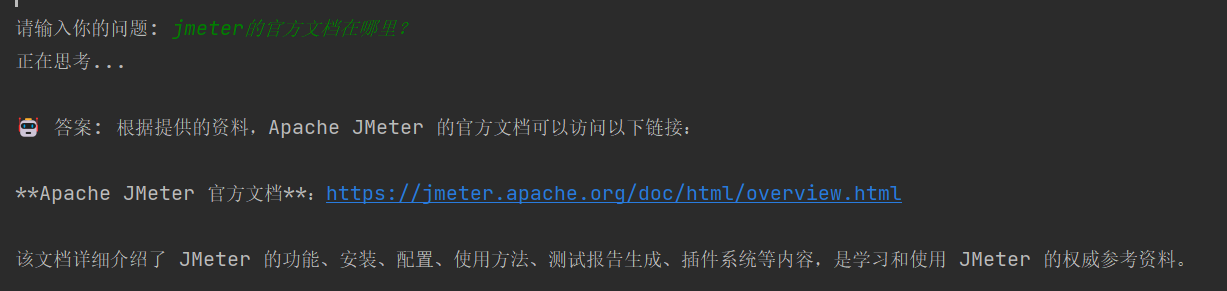
- 提问知识库之外的内容得到的回答

在实现过程中出现的问题
-
读取文档失败,出现编码异常
最开始使用的是from langchain.document_loaders import TextLoader来读取知识库数据,但是因为我提供的文档格式是.docx格式的,读取的时候会有编码问题,后续查看了document_loaders支持的类型,重新选择了Docx2txtLoader -
向量化失败,创建向量库异常
embeddings的初始化,最开始使用的是embeddings = OpenAIEmbeddings(model="xop3qwen1b7"),但是运行时,报错:
openai.BadRequestError: Error code: 400 - {'error': {'message': ' Response status is not 200 ok!, resp: &{404 Not Found 404 HTTP/1.1 1 1 map[Connection:[keep-alive] Content-Length:[80] Content-Type:[application/json; charset=utf-8] Date:[Fri, 12 Sep 2025 09:12:41 GMT] Via:[kong/1.3.0] X-Kong-Proxy-Latency:[1] X-Kong-Upstream-Latency:[2]] 0xc0088905e0 80 [] false false map[] 0xc000326500 <nil>}, body: {"message":"no any schema route found","sid":"ase000eb89a@dx1993d32c506cb0f882"}\n (request id: 2025091217124146847574969891949)', 'type': 'one_api_error', 'param': '', 'code': 'ase_embedding_req_failed'}}
经过验证,目前使用的xop3qwen1b7是语言模型LLM而不是嵌入模型
- 语言模型用于文本生成
- 嵌入模型用于将文本转换为向量
两者功能完全不同,API端点也不同
import requestsdef check_model_capabilities():base_url = "https://您的API地址/v1"api_key = "您的API密钥"# 检查模型详情headers = {"Authorization": f"Bearer {api_key}","Content-Type": "application/json"}try:# 获取模型信息response = requests.get(f"{base_url}/models", headers=headers)models = response.json()print("可用模型列表:")for model in models.get('data', []):print(f"ID: {model['id']}, 类型: {model.get('object', 'unknown')}")# 检查特定模型能力model_info_url = f"{base_url}/models/xop3qwen1b7"model_response = requests.get(model_info_url, headers=headers)if model_response.status_code == 200:model_info = model_response.json()print(f"\n模型详情: {model_info}")else:print(f"\n无法获取模型详情: {model_response.status_code}")except Exception as e:print(f"检查失败: {e}")check_model_capabilities()
因此考虑使用其他的向量模型来解决
考虑使用dashscope, sentence-transformers, pymilvus三类,从AI了解到如下详情:
这三个工具在AI应用开发中扮演着完全不同的角色,它们分别处于技术栈的不同层次:
1. Dashscope(阿里云灵积) - 云服务API
定位: 云端的AI模型服务平台
功能特点:
- 提供多种预训练AI模型的API访问
- 包括语言模型、嵌入模型、多模态模型等
- 完全托管,无需本地部署
- 按使用量付费
使用场景:
# 示例:使用Dashscope的嵌入服务
from dashscope import TextEmbedding# 调用云端嵌入模型
response = TextEmbedding.call(model="text-embedding-v1",input="你的文本"
)
embedding = response.output['embeddings'][0]['embedding']
优点: 简单易用、无需维护、模型强大
缺点: 需要网络连接、有API调用成本
2. sentence-transformers - 本地嵌入模型库
定位: 本地文本嵌入模型框架
功能特点:
- 在本地设备上运行嵌入模型
- 提供各种预训练的句子转换模型
- 完全离线运行
- 一次安装,无限使用
使用场景:
# 示例:使用sentence-transformers本地生成嵌入
from sentence_transformers import SentenceTransformer# 在本地加载模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 本地生成嵌入向量
embeddings = model.encode(["你的文本"])
优点: 完全离线、无API成本、数据隐私性好
缺点: 需要本地计算资源、模型加载时间
3. PyMilvus - 向量数据库客户端
定位: 向量数据存储和检索系统
功能特点:
- 专门用于存储和查询向量数据
- 支持高效的相似性搜索
- 提供数据管理功能(CRUD)
- 需要单独部署Milvus数据库
使用场景:
# 示例:使用PyMilvus存储和检索向量
from pymilvus import connections, Collection# 连接向量数据库
connections.connect("default", host="localhost", port="19530")# 存储向量数据
collection = Collection("my_collection")
collection.insert([embeddings])# 相似性搜索
results = collection.search(query_vectors=[query_embedding],anns_field="embedding",limit=10
)
优点: 高效向量检索、可扩展、生产级性能
缺点: 需要部署维护数据库、学习曲线较陡
三者的关系和工作流程
典型技术栈组合
方案1: 云端全栈方案
Dashscope(嵌入生成) → PyMilvus(向量存储) → 应用系统
方案2: 本地化方案
sentence-transformers(本地嵌入) → PyMilvus(向量存储) → 应用系统
方案3: 混合方案
sentence-transformers(开发测试) → Dashscope(生产环境) → PyMilvus(向量存储)
选择建议
- 需要快速原型开发:选择 Dashscope
- 注重数据隐私和成本控制:选择 sentence-transformers
- 需要生产级向量检索:选择 PyMilvus
- 大型项目:通常三者结合使用
它们不是竞争关系,而是互补关系,共同构成完整的AI应用技术栈。